| Model Fitting: Logistic Regression |
The Output Variables Tab
You can use the Output Variables tab (Figure 23.13) to add analysis variables to the data table. If you request a plot that uses one of the output variables, then that variable is automatically created even if you did not explicitly select the variable on the Output Variables tab.
The following list describes each output variable and indicates how the output variable is named. ![]() represents the name of the response variable. If you use events/trials syntax, then
represents the name of the response variable. If you use events/trials syntax, then ![]() represents the name of the events variable.
represents the name of the events variable.
- Proportions for events/trials
- adds a variable named Proportion_
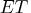 , where
, where 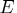 is the name if the events variable and
is the name if the events variable and 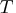 is the name of the trials variable. The value of the variable is the ratio . This variable is added only when you use events/trials syntax.
is the name of the trials variable. The value of the variable is the ratio . This variable is added only when you use events/trials syntax. - Predicted probabilities
- adds predicted probabilities. The variable is named LogiP_
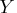 .
. - Confidence limits for predicted probabilities
- adds 95% confidence limits for the predicted probabilities. The variables are named LogiLclm_ and LogiUclm_.
- Linear predictor (log odds)
- adds the linear predictor values. The variable is named LogiXBeta_.
- Pearson chi-square residuals
- adds the Pearson chi-square residuals. The variable is named LogiChiSqR_.
- Deviance residuals
- adds the deviance residuals. The variable is named LogiDevR_.
- Confidence interval displacement (C)
- adds the confidence interval displacement diagnostic,
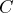 . The variable is named LogiC_.
. The variable is named LogiC_. - Scaled confidence interval displacement (CBAR)
- adds the confidence interval displacement diagnostic,
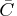 . The variable is named LogiCBar_.
. The variable is named LogiCBar_. - Leverage (H)
- adds the leverage statistic. The variable is named LogiH_.
- DIFCHISQ (influence on chi-square goodness-of-fit)
- adds the change in the chi-square goodness-of-fit statistic attributed to deleting the individual observation. The variable is named LogiDifChiSq_.
- DIFDEV (influence on deviance)
- adds the change in the deviance attributed to deleting the individual observation. The variable is named LogiDifDev_.
- DFBETAS (influence on coefficients)
- adds
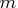 variables, where is the number of parameters in the model. The variables are scaled measures of the change in each parameter estimate and are calculated by deleting the
variables, where is the number of parameters in the model. The variables are scaled measures of the change in each parameter estimate and are calculated by deleting the 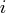 th observation. Large probabilities of DFBETAS indicate observations that are influential in estimating a given parameter. The variables are named DFBETA_
th observation. Large probabilities of DFBETAS indicate observations that are influential in estimating a given parameter. The variables are named DFBETA_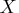 , where is the name of an interval regressor (including the intercept). For classification variables, the variables are named DFBETA_
, where is the name of an interval regressor (including the intercept). For classification variables, the variables are named DFBETA_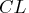 , where is the name of the variable and
, where is the name of the variable and 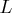 represents a level.
represents a level.
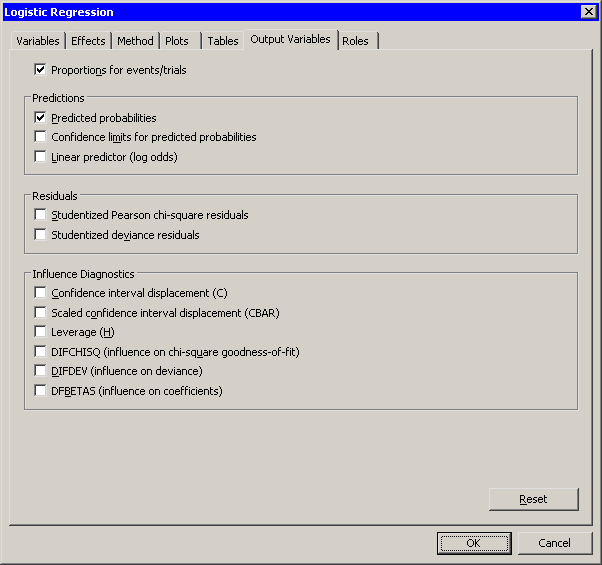 |
Figure 23.13: The Output Variables Tab
Copyright © 2009 by SAS Institute Inc., Cary, NC, USA. All rights reserved.