| The FAMILY Procedure |
Example 6.1 Performing Tests with Missing Parental Data
The following data are from GAW9 (Hodge 1995) and contain 20 nuclear families that are genotyped at two markers. The data have been modified so that each mother’s genotype is missing.
data gaw;
input ped id f_id m_id sex disease m11 m12 m21 m22;
datalines;
1 1 0 0 1 1 7 8 7 2
1 2 0 0 2 1 . . . .
1 401 1 2 1 1 7 2 7 6
1 402 1 2 1 1 8 2 7 6
1 403 1 2 1 1 7 2 2 7
1 404 1 2 2 2 8 2 7 7
2 3 0 0 1 1 4 4 1 3
2 4 0 0 2 1 . . . .
2 405 3 4 2 1 4 6 1 7
2 406 3 4 2 2 4 4 3 7
3 5 0 0 1 1 6 7 7 2
3 6 0 0 2 1 . . . .
3 407 5 6 2 2 7 4 7 7
4 7 0 0 1 1 1 8 7 3
4 8 0 0 2 1 . . . .
4 408 7 8 2 2 8 4 7 3
4 409 7 8 1 1 1 2 3 3
4 410 7 8 2 1 8 2 7 3
4 411 7 8 1 1 8 2 7 5
5 9 0 0 1 1 7 1 6 2
5 10 0 0 2 1 . . . .
5 412 9 10 2 2 7 6 6 2
5 413 9 10 1 1 1 6 6 2
6 11 0 0 1 1 8 4 2 3
6 12 0 0 2 1 . . . .
6 414 11 12 1 2 8 1 2 7
6 415 11 12 1 1 8 6 3 7
7 13 0 0 1 1 4 6 2 2
7 14 0 0 2 1 . . . .
7 416 13 14 1 1 4 5 2 7
7 417 13 14 2 2 6 4 2 7
7 418 13 14 2 1 6 5 2 6
7 419 13 14 1 1 6 5 2 6
8 15 0 0 1 1 6 8 2 7
8 16 0 0 2 1 . . . .
8 420 15 16 2 1 6 2 7 7
8 421 15 16 2 1 8 6 2 7
8 422 15 16 2 2 6 6 7 7
8 423 15 16 2 1 6 6 7 7
9 17 0 0 1 2 4 7 2 7
9 18 0 0 2 1 . . . .
9 424 17 18 2 2 4 5 7 2
9 425 17 18 2 1 7 4 2 7
9 426 17 18 1 1 4 5 2 2
10 19 0 0 1 1 6 4 2 7
10 20 0 0 2 1 . . . .
10 427 19 20 2 2 4 4 7 2
11 21 0 0 1 1 4 7 7 7
11 22 0 0 2 1 . . . .
11 428 21 22 1 1 7 6 7 2
11 429 21 22 2 2 7 4 7 2
11 430 21 22 2 1 7 6 7 3
12 23 0 0 1 1 7 6 7 5
12 24 0 0 2 1 . . . .
12 431 23 24 1 2 6 4 7 7
13 25 0 0 1 1 4 1 2 8
13 26 0 0 2 1 . . . .
13 432 25 26 1 1 4 8 2 6
13 433 25 26 1 2 1 8 8 6
13 434 25 26 1 1 1 4 2 6
14 27 0 0 1 1 7 6 3 2
14 28 0 0 2 1 . . . .
14 435 27 28 1 1 6 2 3 3
14 436 27 28 1 1 7 4 3 7
14 437 27 28 1 1 6 2 2 7
14 438 27 28 1 1 7 4 2 7
14 439 27 28 2 2 6 2 2 7
14 440 27 28 1 1 6 4 3 7
15 29 0 0 1 1 2 4 7 4
15 30 0 0 2 1 . . . .
15 441 29 30 1 1 4 2 7 7
15 442 29 30 2 2 4 8 4 7
15 443 29 30 2 1 4 2 7 5
15 444 29 30 2 1 4 2 7 5
15 445 29 30 1 1 2 8 7 5
;
Since there are missing parental data, the original TDT might not be the best test to perform on this data set. The following analysis uses the S-TDT, SDT, and RC-TDT to test markers for linkage with the disease locus.
proc family data=gaw prefix=Marker sdt stdt rctdt;
id id f_id m_id;
var m11 m12 m21 m22;
trait disease / affected=2;
run;
proc print;
format Probsdt probstdt probrctdt pvalue5.4;
run;
The output data set, which is created by default, is displayed in Output 6.1.1.
Since only one parent is missing genotype information in each nuclear family, the TDT might be applicable to some of the families. The COMBINE option can be specified, as in the following code, to use the TDT in the appropriate families, and the S-TDT or SDT for all other families. This option does not apply to the RC-TDT, so that test is omitted from this analysis.
proc family data=gaw prefix=Marker tdt sdt stdt combine;
id id f_id m_id;
var m11 m12 m21 m22;
trait disease / affected=2;
run;
proc print;
format Probsdt probstdt probtdt pvalue5.4;
run;
The output data set is displayed in Output 6.1.2.
Note that the test statistics for the TDT and the S-TDT and SDT are not the same; this implies that not all families meet the requirements for the TDT. In this case, the S-TDT, SDT, and RC-TDT use more of the data than the TDT alone. However, since there is only one affected child in each nuclear family, the TDT is a valid test of association; since there is at least one occasion when there is more than one unaffected child in a nuclear family, the S-TDT and RC-TDT are not valid for testing for association of the marker with the disease locus (the SDT is always a valid test of association when the data consist of unrelated nuclear families). Both of these considerations, the amount of information that can be used and the validity for testing association, should be taken into account in deciding which test(s) to perform.
Another type of analysis can be performed using the MULT=MAX option in the PROC FAMILY statement. This option indicates that instead of doing a joint test over all the alleles at each marker, you want to perform a test to see if any of the alleles at a marker are significantly linked with the disease locus. This analysis is invoked with the following code, using only the SDT and RC-TDT:
proc family data=gaw prefix=Marker sdt rctdt combine mult=max;
id id f_id m_id;
var m11 m12 m21 m22;
trait disease / affected=2;
run;
proc print;
format Probsdt Probrctdt pvalue6.5;
run;
The output data set produced by this code is displayed in Output 6.1.3.
The chi-square statistics for the tests always have one degree of freedom when the MULT=MAX option is used. Note, however, that the  -values are not the corresponding right-tailed probabilities for a
-values are not the corresponding right-tailed probabilities for a 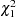 statistic; this is because the -values are Bonferroni-corrected in order to account for taking the maximum of several chi-square statistics.
statistic; this is because the -values are Bonferroni-corrected in order to account for taking the maximum of several chi-square statistics.
Copyright © 2008 by SAS Institute Inc., Cary, NC, USA. All rights reserved.