| The FAMILY Procedure |
| Example |
The following example demonstrates how you can use PROC FAMILY to perform one of several family-based tests, the TDT. You have collected the following family genotypic data that you input into a SAS data set:
data example;
input ped indiv father mother disease (a1-a4)($);
datalines;
1 1 0 0 1 a b a c
1 2 0 0 1 c c a d
1 101 1 2 1 a c a d
1 102 1 2 1 b c a d
1 103 1 2 1 a c c a
1 104 1 2 2 b c a a
2 3 0 0 1 e e f g
2 4 0 0 1 d e g a
2 105 3 4 1 e d f a
2 106 3 4 2 e e g a
3 5 0 0 1 d a a c
3 6 0 0 1 e e c a
3 107 5 6 2 a e a a
4 7 0 0 1 f b a g
4 8 0 0 1 c e h g
4 108 7 8 2 b e a g
4 109 7 8 1 f c g g
4 110 7 8 1 b c a g
4 111 7 8 1 b c a h
5 9 0 0 1 a f d c
5 10 0 0 1 h d c h
5 112 9 10 2 a d d c
5 113 9 10 1 f d d c
6 11 0 0 1 b e c g
6 12 0 0 1 d f a g
6 114 11 12 2 b f c a
6 115 11 12 1 b d g a
7 13 0 0 1 e d c c
7 14 0 0 1 e h d a
7 116 13 14 1 e h c a
7 117 13 14 2 d e c a
7 118 13 14 1 d h c d
7 119 13 14 1 d h c d
;
The first column of the data set contains the pedigree ID, followed by an individual ID and the two parental IDs. The fifth column is a variable representing affection status of a disease. The last four columns of this data set contain the two alleles at each of two markers for each individual. Since there are no missing parental genotypes in this data set, the TDT is a reasonable test to perform in order to determine whether either of the two markers is significantly linked to the disease locus whose location you are trying to pinpoint. Furthermore, close inspection of the data reveals that there is only one affected child (which corresponds to a value of "2" for the disease affection variable) per each family. Thus, the TDT is also a valid test for association with the disease locus. To perform the analysis, you would use the following statements:
proc family data=example prefix=Marker outstat=stats tdt contcorr;
id ped indiv father mother;
trait disease / affected=2;
var a1-a4;
run;
proc print data=stats;
format ProbTDT pvalue6.5;
run;
This code creates an output data set stats, which contains the chi-square statistic, degrees of freedom, and  -value for testing each marker for linkage and association with the disease locus by using the TDT. The PREFIX= option in the PROC FAMILY statement specifies that the two markers be named Marker1 and Marker2 in the output data set. The CONTCORR option indicates that the continuity correction of 0.5 should be used in calculating the chi-square statistic. The AFFECTED= option of the TRAIT statement specifies which value of the variable disease should be considered "affected." Note that the pedigree ID variable is listed in the ID statement; however, it is not necessary for this data set, since all the individual IDs are unique. The same results would be obtained if this variable were omitted.
-value for testing each marker for linkage and association with the disease locus by using the TDT. The PREFIX= option in the PROC FAMILY statement specifies that the two markers be named Marker1 and Marker2 in the output data set. The CONTCORR option indicates that the continuity correction of 0.5 should be used in calculating the chi-square statistic. The AFFECTED= option of the TRAIT statement specifies which value of the variable disease should be considered "affected." Note that the pedigree ID variable is listed in the ID statement; however, it is not necessary for this data set, since all the individual IDs are unique. The same results would be obtained if this variable were omitted.
Figure 6.1 shows the output data set that is produced.
Figure 6.1 displays the statistics for the TDT. Since both markers are multiallelic, a joint test of all alleles at each marker is performed by default. The degrees of freedom (in the dfTDT column) indicate that there are seven alleles at Marker1 and six alleles at Marker2, since df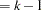 , where
, where 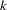 is the number of marker alleles. The ProbTDT column shows that neither of the markers is significantly linked and associated with the disease locus.
is the number of marker alleles. The ProbTDT column shows that neither of the markers is significantly linked and associated with the disease locus.
Copyright © 2008 by SAS Institute Inc., Cary, NC, USA. All rights reserved.