The SSM Procedure
-
Overview

- Getting Started
-
Syntax
-
DetailsState Space Model and NotationTypes of Sequence DataOverview of Model Specification SyntaxFiltering, Smoothing, Likelihood, and Structural Break DetectionEstimation of User-Specified Linear Combination of State ElementsContrasting PROC SSM with Other SAS Procedures Predefined Trend ModelsPredefined Structural ModelsModels with Dependent LagsCovariance ParameterizationMissing ValuesComputational IssuesDisplayed OutputODS Table NamesODS Graph NamesOUT= Data Set
-
ExamplesBivariate Basic Structural Model Panel Data: Random-Effects and Autoregressive ModelsBackcasting, Forecasting, and InterpolationLongitudinal Data: Smoothing of Repeated MeasuresA User-Defined Trend ModelModel with Multiple ARIMA ComponentsDynamic Factor ModelingDiagnostic Plots and Structural Break AnalysisLongitudinal Data: Variable Bandwidth SmoothingA Transfer Function Model for the Gas Furnace DataPanel Data: Dynamic Panel Model for the Cigar DataMultivariate Modeling: Long-Term Temperature TrendsBivariate Model: Sales of Mink and Muskrat FursFactor Model: Now-Casting the US EconomyLongitudinal Data: Lung Function Analysis
- References
Delete-One Cross Validation and Structural Breaks
In addition to the interpolation of missing response values and the full-sample estimation of components in the model, the smoothing phase can also produce several useful diagnostic measures that can indicate outlying observations and breaks in the state evolution process. The treatment of additive outliers and structural breaks that is described in this section is based on De Jong and Penzer (1998).
Delete-One Cross Validation and the Additive Outlier Detection
Let 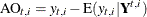 denote the difference between the observed response value
denote the difference between the observed response value 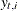 and its estimate or prediction by using all the data except , which is denoted by
and its estimate or prediction by using all the data except , which is denoted by 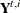 . The smoothing phase of DKFS can generate
. The smoothing phase of DKFS can generate 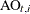 (and its variance) at all
(and its variance) at all 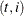 . A large value of signifies that the observed response value () is unusual relative to the rest of the sample (according to the postulated model). Such values are called additive outliers.
In the literature, are referred by a few different names. Sometimes they are called delete-one cross validation errors or simply prediction errors. In this chapter, these names are used interchangeably. Like the one-step-ahead residuals,
. A large value of signifies that the observed response value () is unusual relative to the rest of the sample (according to the postulated model). Such values are called additive outliers.
In the literature, are referred by a few different names. Sometimes they are called delete-one cross validation errors or simply prediction errors. In this chapter, these names are used interchangeably. Like the one-step-ahead residuals, 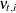 , the prediction errors can be used in checking the adequacy of the model. The prediction errors are normally distributed;
however, unlike , they are not serially uncorrelated. is set to missing when is missing. The SSM procedure prints a summary table of extreme additive outliers by default. In addition, you can request
the plotting of the standardized prediction errors, and they can be output to a data set.
, the prediction errors can be used in checking the adequacy of the model. The prediction errors are normally distributed;
however, unlike , they are not serially uncorrelated. is set to missing when is missing. The SSM procedure prints a summary table of extreme additive outliers by default. In addition, you can request
the plotting of the standardized prediction errors, and they can be output to a data set.
The prediction error sum of squares (PRESS)
![\[ \sum _{t,i} {AO}_{t, i}^{2} \]](images/etsug_ssm0283.png)
can be a useful measure of fit to compare different models. It is also called the cross validation error sum of squares. An additional measure of fit based on the prediction errors is called the generalized cross validation error sum of squares (GCV). Denoting the variance of by 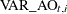 , it is defined as
, it is defined as
![\[ \frac{\sum _{t,i} ( {AO}_{t, i}^{2} / {VAR\_ AO}_{t, i}^{2})}{[ \; \sum _{t,i}(1/{VAR\_ AO}_{t, i})\; ]^{2}} \]](images/etsug_ssm0285.png)
You can request the printing of PRESS and GCV by specifying the PRESS option in the OUTPUT statement.
After inspecting the reported additive outliers, you can adjust the model to account for the effects of some of the extreme outlying observations. This can be done by including appropriate dummy variables in the observation equation.
Structural Breaks in the State Evolution
The additive outliers that are discussed in the preceding section are diagnostic measures associated with the measurement equation. The smoothing phase of DKFS can generate diagnostic measures that are also associated with the state equation.
For simplicity of notation and exposition, initially assume that the state equation has the following form:
![\[ \pmb {\alpha }_{t+1} = \mb{T}_{t} \pmb {\alpha }_{t} + \mb{c}_{t+1} + \pmb {\eta }_{t+1} \]](images/etsug_ssm0286.png)
That is, the state regression term 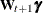 is absent in the postulated model. Suppose that an unanticipated change of unknown size takes place in the
is absent in the postulated model. Suppose that an unanticipated change of unknown size takes place in the 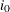 th element of the state at time
th element of the state at time 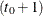 . The model can then be adjusted to account for this change by including a suitable dummy regressor in the state equation
as follows:
. The model can then be adjusted to account for this change by including a suitable dummy regressor in the state equation
as follows:
![\[ \pmb {\alpha }_{t+1} = \mb{T}_{t} \pmb {\alpha }_{t} + \mb{W}_{t+1} \pmb {\gamma } + \mb{c}_{t+1} + \pmb {\eta }_{t+1} \]](images/etsug_ssm0289.png)
Here 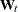 is a sequence of m-dimensional column vectors such that
is a sequence of m-dimensional column vectors such that ![$\mb{W}_{t_{0}+1}[i_{0}] = 1$](images/etsug_ssm0290.png) and
and ![$\mb{W}_{t}[i] = 0$](images/etsug_ssm0291.png) for all other t and i. The estimate of the regression coefficient
for all other t and i. The estimate of the regression coefficient 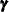 provides information about the size of the unanticipated change in the th element of
provides information about the size of the unanticipated change in the th element of 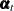 at time
at time 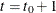 . Similarly, an unanticipated change in a subsection of at a time can be estimated by using a set of appropriate dummies (the number of dummies equals the number of elements in the state
subsection) in the state equation. The algorithm of De Jong and Penzer (1998) efficiently generates the estimates of such one-time changes in the state at all distinct time points in the sample in one
smoothing pass. A statistically significant value of at a time point
. Similarly, an unanticipated change in a subsection of at a time can be estimated by using a set of appropriate dummies (the number of dummies equals the number of elements in the state
subsection) in the state equation. The algorithm of De Jong and Penzer (1998) efficiently generates the estimates of such one-time changes in the state at all distinct time points in the sample in one
smoothing pass. A statistically significant value of at a time point 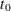 indicates an unanticipated change in the relevant element (or the subsection) of
indicates an unanticipated change in the relevant element (or the subsection) of 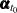 . Note that the change associated with an additive outlier is temporary: the previous or the subsequent measurements are not
affected. On the other hand, because of the evolutionary nature of the state equation, a one-time change in the state affects
all the subsequent states, which in turn affect the subsequent observations. In this sense, a significant unanticipated change
in the state is a structural break.
. Note that the change associated with an additive outlier is temporary: the previous or the subsequent measurements are not
affected. On the other hand, because of the evolutionary nature of the state equation, a one-time change in the state affects
all the subsequent states, which in turn affect the subsequent observations. In this sense, a significant unanticipated change
in the state is a structural break.
In the preceding discussion, the absence of the state regression variables in the postulated model was assumed only for notational simplicity. If the postulated model does contain some state regression variables, the dummy variable that is associated with the one-time state change is simply added to the existing set of state regression variables, and the interpretation of its regression coefficient as the measure of unanticipated change in the state remains unaffected.
In the SSM procedure, you can request the computation of significance statistics that are associated with one-time changes
in the state subsections specified by using the STATE statement in addition to the state subsections that are associated with
the components specified by using the TREND statements. This is done by using the CHECKBREAK option in these statements. In
addition, you can request the computation of such statistics for the entire state by using the MAXSHOCK option in the OUTPUT statement. The significance statistics can be computed for both elementwise change
and subsectionwise change. The computation of subsectionwise change statistics can be computationally expensive for large
subsections (an inversion of a 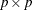 -dimensional matrix at each distinct time point in the sample is needed for the computation of significance statistics for
a state subsection of size p). For an example of structural break analysis, see Example 34.8.
-dimensional matrix at each distinct time point in the sample is needed for the computation of significance statistics for
a state subsection of size p). For an example of structural break analysis, see Example 34.8.