The STATESPACE Procedure

The state space model represents a multivariate time series through auxiliary variables, some of which might not be directly observable. These auxiliary variables are called the state vector. The state vector summarizes all the information from the present and past values of the time series that is relevant to the prediction of future values of the series. The observed time series are expressed as linear combinations of the state variables. The state space model is also called a Markovian representation, or a canonical representation, of a multivariate time series process. The state space approach to modeling a multivariate stationary time series is summarized in Akaike (1976).
The state space form encompasses a very rich class of models. Any Gaussian multivariate stationary time series can be written in a state space form, provided that the dimension of the predictor space is finite. In particular, any autoregressive moving average (ARMA) process has a state space representation and, conversely, any state space process can be expressed in an ARMA form (Akaike, 1974). More details on the relation of the state space and ARMA forms are given in the section Relation of ARMA and State Space Forms.
Let ![]() be the
be the ![]() vector of observed variables, after differencing (if differencing is specified) and subtracting the sample mean. Let
vector of observed variables, after differencing (if differencing is specified) and subtracting the sample mean. Let ![]() be the state vector of dimension s,
be the state vector of dimension s, ![]() , where the first r components of
, where the first r components of ![]() consist of
consist of ![]() . Let the notation
. Let the notation ![]() represent the conditional expectation (or prediction) of
represent the conditional expectation (or prediction) of ![]() based on the information available at time t. Then the last
based on the information available at time t. Then the last ![]() elements of
elements of ![]() consist of elements of x
consist of elements of x ![]() , where k >0 is specified or determined automatically by the procedure.
, where k >0 is specified or determined automatically by the procedure.
There are various forms of the state space model in use. The form of the state space model used by the STATESPACE procedure is based on Akaike (1976). The model is defined by the following state transition equation :
In the state transition equation, the ![]() coefficient matrix F is called the transition matrix; it determines the dynamic properties of the model.
coefficient matrix F is called the transition matrix; it determines the dynamic properties of the model.
The ![]() coefficient matrix G is called the input matrix; it determines the variance structure of the transition equation. For model identification, the first r rows and columns of G are set to an
coefficient matrix G is called the input matrix; it determines the variance structure of the transition equation. For model identification, the first r rows and columns of G are set to an ![]() identity matrix.
identity matrix.
The input vector e ![]() is a sequence of independent normally distributed random vectors of dimension r with mean 0 and covariance matrix
is a sequence of independent normally distributed random vectors of dimension r with mean 0 and covariance matrix ![]() . The random error e
. The random error e ![]() is sometimes called the innovation vector or shock vector.
is sometimes called the innovation vector or shock vector.
In addition to the state transition equation, state space models usually include a measurement equation or observation equation that gives the observed values ![]() as a function of the state vector
as a function of the state vector ![]() . However, since PROC STATESPACE always includes the observed values
. However, since PROC STATESPACE always includes the observed values ![]() in the state vector
in the state vector ![]() , the measurement equation in this case merely represents the extraction of the first r components of the state vector.
, the measurement equation in this case merely represents the extraction of the first r components of the state vector.
The measurement equation used by the STATESPACE procedure is
where ![]() is an
is an ![]() identity matrix. In practice, PROC STATESPACE performs the extraction of
identity matrix. In practice, PROC STATESPACE performs the extraction of ![]() from
from ![]() without reference to an explicit measurement equation.
without reference to an explicit measurement equation.
In summary:
- x

-
is an observation vector of dimension r.
- z
-
is a state vector of dimension s, whose first r elements are x
and whose last  elements are conditional prediction of future x .
elements are conditional prediction of future x .
- F
-
is an
 transition matrix.
transition matrix.
- G
-
is an
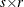 input matrix, with the identity matrix I
input matrix, with the identity matrix I  forming the first r rows and columns.
forming the first r rows and columns.
- e
-
is a sequence of independent normally distributed random vectors of dimension r with mean 0 and covariance matrix
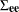 .
.