The SEVERITY Procedure
- Overview
-
Getting Started

-
Syntax
-
DetailsPredefined DistributionsCensoring and TruncationParameter Estimation MethodParameter InitializationEstimating Regression EffectsEmpirical Distribution Function Estimation MethodsStatistics of FitDefining a Distribution Model with the FCMP ProcedurePredefined Utility FunctionsCustom Objective FunctionsMultithreaded ComputationInput Data SetsOutput Data SetsDisplayed OutputODS Graphics
-
Examples
- References
If you have not specified a custom objective function by specifying programming statements and the OBJECTIVE= option in the PROC SEVERITY statement, then PROC SEVERITY uses the maximum likelihood (ML) method to estimate the parameters of each model. A nonlinear optimization process is used to maximize the log of the likelihood function. If you have specified a custom objective function, then PROC SEVERITY uses a nonlinear optimization algorithm to estimate the parameters of each model that minimize the value of your specified objective function. For more information, see the section Custom Objective Functions.
Let ![]() and
and ![]() denote the PDF and CDF, respectively, evaluated at
denote the PDF and CDF, respectively, evaluated at ![]() for a set of parameter values
for a set of parameter values ![]() . Let
. Let ![]() denote the random response variable, and let
denote the random response variable, and let ![]() denote its value recorded in an observation in the input data set. Let
denote its value recorded in an observation in the input data set. Let ![]() and
and ![]() denote the random variables for the left-truncation and right-truncation threshold, respectively, and let
denote the random variables for the left-truncation and right-truncation threshold, respectively, and let ![]() and
and ![]() denote their values for an observation, respectively. If there is no left-truncation, then
denote their values for an observation, respectively. If there is no left-truncation, then ![]() , where
, where ![]() is the smallest value in the support of the distribution; so
is the smallest value in the support of the distribution; so ![]() . If there is no right-truncation, then
. If there is no right-truncation, then ![]() , where
, where ![]() is the largest value in the support of the distribution; so
is the largest value in the support of the distribution; so ![]() . Let
. Let ![]() and
and ![]() denote the random variables for the left-censoring and right-censoring limit, respectively, and let
denote the random variables for the left-censoring and right-censoring limit, respectively, and let ![]() and
and ![]() denote their values for an observation, respectively. If there is no left-censoring, then
denote their values for an observation, respectively. If there is no left-censoring, then ![]() , so
, so ![]() . If there is no right-censoring, then
. If there is no right-censoring, then ![]() , so
, so ![]() .
.
The set of input observations can be categorized into the following four subsets within each BY group:
-
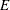 is the set of uncensored and untruncated observations. The likelihood of an observation in is
is the set of uncensored and untruncated observations. The likelihood of an observation in is
![\[ l_{E} = \Pr (Y=y) = f_\Theta (y) \]](images/etsug_severity0311.png)
-
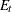 is the set of uncensored observations that are truncated. The likelihood of an observation in is
is the set of uncensored observations that are truncated. The likelihood of an observation in is
![\[ l_{E_ t} = \Pr (Y=y | t^ l < Y \leq t^ r) = \frac{f_\Theta (y)}{F_\Theta (t^ r) - F_\Theta (t^ l)} \]](images/etsug_severity0313.png)
-
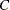 is the set of censored observations that are not truncated. The likelihood of an observation is
is the set of censored observations that are not truncated. The likelihood of an observation is
![\[ l_{C} = \Pr (c^ r < Y \leq c^ l) = F_\Theta (c^ l) - F_\Theta (c^ r) \]](images/etsug_severity0315.png)
-
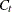 is the set of censored observations that are truncated. The likelihood of an observation is
is the set of censored observations that are truncated. The likelihood of an observation is
![\[ l_{C_ t} = \Pr (c^ r < Y \leq c^ l | t^ l < Y \leq t^ r) = \frac{F_\Theta (c^ l) - F_\Theta (c^ r)}{F_\Theta (t^ r) - F_\Theta (t^ l)} \]](images/etsug_severity0317.png)
Note that ![]() . Also, the sets
. Also, the sets ![]() and
and ![]() are empty when no truncation is specified, and the sets
are empty when no truncation is specified, and the sets ![]() and
and ![]() are empty when no censoring is specified.
are empty when no censoring is specified.
Given this, the likelihood of the data ![]() is as follows:
is as follows:
The maximum likelihood procedure used by PROC SEVERITY finds an optimal set of parameter values ![]() that maximizes
that maximizes ![]() subject to the boundary constraints on parameter values. For a distribution dist, such boundary constraints can be specified by using the dist_LOWERBOUNDS and dist_UPPERBOUNDS subroutines. See the section Defining a Distribution Model with the FCMP Procedure for more information. Some aspects of the optimization process can be controlled by using the NLOPTIONS statement.
subject to the boundary constraints on parameter values. For a distribution dist, such boundary constraints can be specified by using the dist_LOWERBOUNDS and dist_UPPERBOUNDS subroutines. See the section Defining a Distribution Model with the FCMP Procedure for more information. Some aspects of the optimization process can be controlled by using the NLOPTIONS statement.
If probability of observability is specified for the left-truncation, then PROC SEVERITY uses a modified likelihood function
for each truncated observation. If the probability of observability is ![]() , then for each left-truncated observation with truncation threshold
, then for each left-truncated observation with truncation threshold ![]() , there exist
, there exist ![]() observations with a response variable value less than or equal to
observations with a response variable value less than or equal to ![]() . Each such observation has a probability of
. Each such observation has a probability of ![]() . The right-truncation and censoring information does not apply to these added observations. Thus, following the notation
of the section Likelihood Function, the likelihood of the data is as follows:
. The right-truncation and censoring information does not apply to these added observations. Thus, following the notation
of the section Likelihood Function, the likelihood of the data is as follows:
|
|
|
|
|
|
Note that the likelihood of the observations that are not left-truncated (observations in sets ![]() and
and ![]() , and observations in sets
, and observations in sets ![]() and
and ![]() for which
for which ![]() ) is not affected.
) is not affected.
If you have specified a custom objective function, then PROC SEVERITY accounts for the probability of observability only while computing the empirical distribution function estimate. The parameter estimates are affected only by your custom objective function.
PROC SEVERITY computes an estimate of the covariance matrix of the parameters by using the asymptotic theory of the maximum
likelihood estimators (MLE). If ![]() denotes the number of observations used for estimating a parameter vector
denotes the number of observations used for estimating a parameter vector ![]() , then the theory states that as
, then the theory states that as ![]() , the distribution of
, the distribution of ![]() , the estimate of
, the estimate of ![]() , converges to a normal distribution with mean
, converges to a normal distribution with mean ![]() and covariance
and covariance ![]() such that
such that ![]() , where
, where ![]() is the information matrix for the likelihood of the data,
is the information matrix for the likelihood of the data, ![]() . The covariance estimate is obtained by using the inverse of the information matrix.
. The covariance estimate is obtained by using the inverse of the information matrix.
In particular, if ![]() denotes the Hessian matrix of the negative of log likelihood, then the covariance estimate is computed as
denotes the Hessian matrix of the negative of log likelihood, then the covariance estimate is computed as
where ![]() is a denominator that is determined by the VARDEF= option. If VARDEF=N, then
is a denominator that is determined by the VARDEF= option. If VARDEF=N, then ![]() , which yields the asymptotic covariance estimate. If VARDEF=DF, then
, which yields the asymptotic covariance estimate. If VARDEF=DF, then ![]() , where
, where ![]() is number of parameters (the model’s degrees of freedom). The VARDEF=DF option is the default, because it attempts to correct
the potential bias introduced by the finite sample.
is number of parameters (the model’s degrees of freedom). The VARDEF=DF option is the default, because it attempts to correct
the potential bias introduced by the finite sample.
The standard error ![]() of the parameter
of the parameter ![]() is computed as the square root of the
is computed as the square root of the ![]() th diagonal element of the estimated covariance matrix; that is,
th diagonal element of the estimated covariance matrix; that is, ![]() .
.
If you have specified a custom objective function, then the covariance matrix of the parameters is still computed by inverting
the information matrix, except that the Hessian matrix ![]() is computed as
is computed as ![]() , where
, where ![]() denotes your custom objective function that is minimized by the optimizer.
denotes your custom objective function that is minimized by the optimizer.
Covariance and standard error estimates might not be available if the Hessian matrix is found to be singular at the end of the optimization process. This can especially happen if the optimization process stops without converging.