SEVERITY Procedure
The following features and updates have been added to the SEVERITY procedure:
-
Estimation algorithms have been modified to use multiple threads of execution in parallel, which enables PROC SEVERITY to fully utilize all the CPU cores of the machine where it is being run to complete the estimation tasks significantly faster.
-
A new plot, the Q-Q plot, has been added. You can request this plot by specifying the PLOTS=QQPLOT or PLOTS=ALL option in the PROC SEVERITY statement. For a distribution named dist, the quantile for a given value of the cumulative distribution function (CDF) is computed either by evaluating the dist_QUANTILE function, if it is defined for the distribution, or by inverting the dist_CDF function of the distribution.
-
Standard errors and confidence intervals are now available for the empirical distribution function (EDF) estimates. They are written to the OUTCDF= data set. If you specify the PLOTS=CDFPERDIST option, then the lower and upper confidence limits of EDF estimates are plotted in the CDFDistPlot plots. You can specify the confidence level for the confidence interval by specifying the new EDFALPHA= option in the PROC SEVERITY statement.
For standard EDF estimators (no censoring or truncation), the standard errors are computed using the normal approximation. For Kaplan-Meier and modified Kaplan-Meier estimators (truncation with one type of censoring), Greenwood’s formula is used. For Turnbull’s estimator (both types of censoring with or without truncation), standard errors are computed from the estimate of the covariance matrix that is computed by inverting the Hessian matrix of Turnbull’s nonparametric log-likelihood. If the Hessian matrix is singular or results in missing values for the standard errors of any of the intervals, then the normal approximation method is used.
-
If you specify the SCALEMODEL statement, then the scale of the distribution depends on the values of regressors. For a given distribution family, each observation implies a different scaled version of the distribution. PROC SEVERITY needs to construct a single representative distribution from all such distributions in order to compute estimates of CDF and the probability density function (PDF) that are comparable across different distribution families. Prior to this release, the representative distribution was constructed as the weighted mixture of distributions implied by all observations. For that method, estimation of CDF or PDF for one observation requires
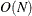 computations, where
computations, where 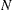 denotes the total number of observations. So estimation of CDF or PDF for all observations requires
denotes the total number of observations. So estimation of CDF or PDF for all observations requires 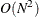 computations, which can dominate the runtime of PROC SEVERITY even for moderately large values of .
computations, which can dominate the runtime of PROC SEVERITY even for moderately large values of .
Starting with this release, you can specify the new DFMIXTURE= option in the SCALEMODEL statement to choose one of four methods to construct the representative mixture distribution. The prior method is used when you specify DFMIXTURE=FULL option. The default method is DFMIXTURE=MEAN, which uses a distribution with scale equal to the mean of
scale values. It is significantly faster than the FULL method. The other two methods construct a mixture of 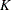 distributions each with one of scale values, which are either the
distributions each with one of scale values, which are either the 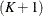 -quantiles from the sample of scale values (DFMIXTURE=QUANTILE) or the scale values implied by randomly chosen observations (DFMIXTURE=RANDOM). For
-quantiles from the sample of scale values (DFMIXTURE=QUANTILE) or the scale values implied by randomly chosen observations (DFMIXTURE=RANDOM). For 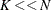 , the QUANTILE and RANDOM methods can be significantly faster than the FULL method.
, the QUANTILE and RANDOM methods can be significantly faster than the FULL method.
-
The DIST statement now supports two more keywords in addition to the _PREDEFINED_ keyword. If you specify the _USER_ keyword, then PROC SEVERITY includes all the custom distributions that you have defined in the libraries specified in the CMPLIB= system option. The _ALL_ keyword includes all the predefined distributions and your custom distributions. It also includes the Tweedie and scaled-Tweedie distributions that are not included by the _PREDEFINED_ keyword.
The DIST statement also has two new options, LISTONLY and VALIDATEONLY. The LISTONLY option lists the names of the distributions that you have specified in the DIST statement and the distributions implied by any keywords that you specify. This option is especially useful in conjunction with the keywords. The VALIDATEONLY option validates all the specified distributions and writes the distribution’s information to the OUTMODELIFO= data set and a new ODS table, DistributionInfo. This option is especially useful in conjunction with your custom distributions, because it enables you to check whether the definitions of the functions and subroutines that make up your distribution satisfy PROC SEVERITY’s requirements.