MODEL Statement
MODEL dependent = regressors < / options > ;
The MODEL statement specifies the dependent variable and independent regressor variables for the regression model. When the nested logit model is estimated, regressors in the UTILITY statement are used for estimation.
The following options can be used in the MODEL statement after a slash (/).
-
CHOICE=( variables )
CHOICE=( variable numbers ) -
specifies the variables that contain possible choices for each individual. Choice variables must have integer values. Multiple choice variables are allowed only for nested logit models and must be specified in order from the highest level to the lowest level. For example, CHOICE=(
upmode,mode) indicates that the nested logit model has two levels. The choices at the upper level are described by theupmodevariable, and the choices at the lower level are described by themodevariable. If all possible alternatives are written with the variable name, the MDC procedure checks all values of the choice variable. CHOICE=(X 1 2 3) implies that the value of X should be 1, 2, or 3. On the other hand, the CHOICE=(X) considers all distinctive nonmissing values of X as elements of the choice set. - CONVERGE=number
-
specifies the convergence criterion. The CONVERGE= option is the same as the ABSGCONV= option in the NLOPTIONS statement. The ABSGCONV= option in the NLOPTIONS statement overrides the CONVERGE= option. The default value is 1E–5.
- HALTONSTART=number
-
specifies the starting point of the Halton sequence. The specified number must be a positive integer. The default is HALTONSTART=11.
- HEV=( option-list )
-
specifies options that are used to estimate the HEV model. The HEV model with a unit scale for the alternative 1 is estimated using the following SAS statement:
model y = x1 x2 x3 / hev=(unitscale=1);
The following options can be used in the HEV= option. These options are listed within parentheses and separated by commas.
- INTORDER=number
-
specifies the number of summation terms for Gaussian quadrature integration. The default is INTORDER=40. The maximum order is limited to 45. This option applies only to the INTEGRATION=LAGUERRE method.
- UNITSCALE=number-list
-
specifies restrictions on scale parameters of stochastic utility components.
- INTEGRATE=LAGUERRE | HARDY
-
specifies the integration method. The INTEGRATE=HARDY option specifies an adaptive integration method, while the INTEGRATE=LAGUERRE option specifies the Gauss-Laguerre approximation method. The default is INTEGRATE=LAGUERRE.
- MIXED=( option-list )
-
specifies options that are used for mixed logit estimation. The mixed logit model with normally distributed random parameters is specified as follows:
model y = x1 x2 x3 / mixed=(normalparm=x1);
The following options can be used in the MIXED= option. The options are listed within parentheses and separated by commas.
- LOGNORMALPARM=variables
-
specifies the variables whose random coefficients are lognormally distributed. LOGNORMALPARM= variables must be included on the right-hand side of the MODEL statement.
- NORMALEC=variables
-
specifies the error component variables whose coefficients have a normal distribution
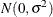 .
.
- NORMALPARM=variables
-
specifies the variables whose random coefficients are normally distributed. NORMALPARM= variables must be included on the right-hand side of the MODEL statement.
- UNIFORMEC=variables
-
specifies the error component variables whose coefficients have a uniform distribution
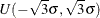 .
.
- UNIFORMPARM=variables
-
specifies the variables whose random coefficients are uniformly distributed. UNIFORMPARM= variables must be included on the right-hand side of the MODEL statement.
- NCHOICE=number
-
specifies the number of choices for multinomial choice models when all individuals have the same choice set. When individuals have different number of choices, the NCHOICE= option is not allowed, and the CHOICE= option should be used. The NCHOICE= and CHOICE= options must not be used simultaneously, and the NCHOICE= option cannot be used for nested logit models.
- NSIMUL=number
-
specifies the number of simulations when the mixed logit or multinomial probit model is estimated. The default is NSIMUL=100. In general, you need a smaller number of simulations with RANDNUM=HALTON than with RANDNUM=PSEUDO.
- RANDNUM=value
-
specifies the type of the random number generator used for simulation. RANDNUM=HALTON is the default. The following option values are allowed:
- PSEUDO
-
specifies pseudo-random number generation.
- HALTON
-
specifies Halton sequence generation.
-
RANDINIT
RANDINIT=number -
specifies that initial parameter values be perturbed by uniform pseudo-random numbers for numerical optimization of the objective function. The default is
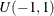 . When the RANDINIT=
. When the RANDINIT= option is specified,
option is specified, 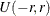 pseudo-random numbers are generated. The value should be positive. With a RANDINIT or RANDINIT= option, there are pure random searches for a given number of trials (1,000
for conditional or nested logit, and 500 for other models) to get a maximum (or minimum) value of the objective function.
For example, when there is a parameter estimate with an initial value of 1, the RANDINIT option adds a generated random number
pseudo-random numbers are generated. The value should be positive. With a RANDINIT or RANDINIT= option, there are pure random searches for a given number of trials (1,000
for conditional or nested logit, and 500 for other models) to get a maximum (or minimum) value of the objective function.
For example, when there is a parameter estimate with an initial value of 1, the RANDINIT option adds a generated random number
 to the initial value and computes an objective function value by using
to the initial value and computes an objective function value by using 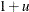 . This option is helpful in finding the initial value automatically if there is no guidance in setting the initial estimate.
. This option is helpful in finding the initial value automatically if there is no guidance in setting the initial estimate.
- RANK
-
specifies that the dependent variable contain ranks. The numbers must be positive integers starting from 1. When the dependent variable has value 1, the corresponding alternative is chosen. This option is provided only as a convenience to the user; the extra information contained in the ranks is not currently used for estimation purposes.
- RESTART=( option-list )
-
specifies options that are used for reiteration of the optimization problem. When the ADDRANDOM option is specified, the initial value of reiteration is computed using random grid searches around the initial solution, as follows:
model y = x1 x2 / type=clogit restart=(addvalue=(.01 .01));The preceding SAS statement reestimates a conditional logit model by adding ADDVALUE= values. If the ADDVALUE= option contains missing values, the RESTART= option uses the corresponding estimate from the initial stage. If no ADDVALUE= value is specified for an estimate, a default value equal to (|estimate| * 1e-3) is added to the corresponding estimate from the initial stage. If both the ADDVALUE= and ADDRANDOM(=) options are specified, ADDVALUE= is ignored.
The following options can be used in the RESTART= option. The options are listed within parentheses.
- ADDMAXIT=number
-
specifies the maximum number of iterations for the second stage of the estimation. The default is ADDMAXIT=100.
- ADDRANDOM | ADDRANDOM=value
-
specifies random added values to the estimates from the initial stage. With the ADDRANDOM option,
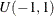 random numbers are created and added to the estimates obtained in the initial stage. When the ADDRANDOM= option is specified, random numbers are generated. The restart initial value is determined based on the given number of random searches (1,000
for conditional or nested logit, and 500 for other models).
random numbers are created and added to the estimates obtained in the initial stage. When the ADDRANDOM= option is specified, random numbers are generated. The restart initial value is determined based on the given number of random searches (1,000
for conditional or nested logit, and 500 for other models).
- ADDVALUE=( value-list )
-
specifies values added to the estimates from the initial stage. A missing value in the list is considered as a zero value for the corresponding estimate. When the ADDVALUE= option is not specified, default values equal to (|estimate| * 1e-3) are added.
- SAMESCALE
-
specifies that the parameters of the inclusive values be the same within a group at each level when the nested logit is estimated.
- SEED=number
-
specifies an initial seed for pseudo-random number generation. The SEED= value must be less than
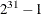 . If the SEED= value is negative or zero, the time of day from the computer’s clock is used to obtain the initial seed. The
default is SEED=0.
. If the SEED= value is negative or zero, the time of day from the computer’s clock is used to obtain the initial seed. The
default is SEED=0.
- SPSCALE
-
specifies that the parameters of the inclusive values be the same for any choice with only one nested choice within a group, for each level in a nested logit model. This option is useful in analyzing stated preference data.
- TYPE=value
-
specifies the type of model to be analyzed. The following model types are supported:
- CONDITIONLOGIT | CLOGIT | CL
-
specifies a conditional logit model.
- HEV
-
specifies a heteroscedastic extreme-value model.
- MIXEDLOGIT | MXL
-
specifies a mixed logit model.
- MULTINOMPROBIT | MPROBIT | MP
-
specifies a multinomial probit model.
- NESTEDLOGIT | NLOGIT | NL
-
specifies a nested logit model.
- UNITVARIANCE=( number-list )
-
specifies normalization restrictions on error variances of multinomial probit for the choices whose numbers are given in the list. If the UNITVARIANCE= option is specified, it must include at least two choices. Also, for identification, additional zero restrictions are placed on the correlation coefficients for the last choice in the list.
- COVEST=value
-
specifies the type of covariance matrix. The following types are supported:
- OP
-
specifies the covariance from the outer product matrix.
- HESSIAN
-
specifies the covariance from the Hessian matrix.
- QML
-
specifies the covariance from the outer product and Hessian matrices.
When COVEST=OP is specified, the outer product matrix is used to compute the covariance matrix of the parameter estimates. The COVEST=HESSIAN option produces the covariance matrix by using the inverse Hessian matrix. The quasi-maximum likelihood estimates are computed with COVEST=QML. The default is COVEST=HESSIAN when the Newton-Raphson method is used. COVEST=OP is the default when the OPTMETHOD=QN option is specified.
Printing Options
Estimation Control Options
You can also specify detailed optimization options in the NLOPTIONS statement. The OPTMETHOD= option overrides the TECHNIQUE= option in the NLOPTIONS statement. The NLOPTIONS statement is ignored if the OPTMETHOD= option is specified.