Model Nodes
Extension nodes that
perform predictive modeling have special requirements. Before proceeding
with this section, it is recommended that you read the Appendix 3: Predictive Modeling documentation. In particular, read
the sections entitled Predicted Values and Posterior
Probabilities and Input and Output Data Sets. The discussion below assumes familiarity
with that subject matter.
Integrating a modeling
node into the Enterprise Miner environment requires that you write
scoring code that generates predicted or posterior variables with
appropriate names. The attributes of the variables and assessment
variables for each target variable are stored in SAS data sets. The
names of the data sets can be found in WORK.EM_TARGETDECINFO. Consider
the following process flow diagram:

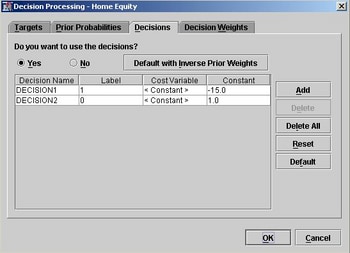
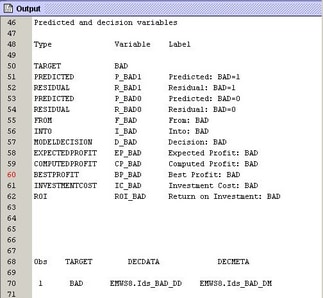
The output, by default,
displays the names of the variables that you want to create. For example,
after you train your model, you need to generate two variables that
represent the predictions for the target variable, BAD. The output
above tells you that the names of the variables, in this example,
should be P_BAD1 and P_BAD0; P_BAD1 is the probability that BAD =
1 and P_BAD0 is the probability that BAD = 0. The source of that information
is the DECMETA data set for the target, BAD. The result of the PROC
PRINT statement that is displayed at the bottom of the output informs
us that the name of the DECMETA data set is EMWS8.Ids_BAD_DM. Using
Explorer, we can view the data set:
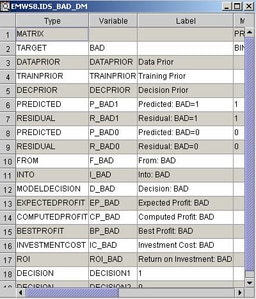
At run time, when there
is only one target variable, the &EM_DEC_DECMETA macro variable
is assigned the name of the decision metadata data set for the target
variable. In this example, &EM_DEC_DECMETA resolves to EMWS8.Ids_BAD_DM.
Using &EM_DEC_DECMETA enables you to retrieve the information
programmatically. For example, the code below creates two macro arrays,
pred_vars and pred_labels, that contain the names and labels, respectively,
of the posterior or predicted variables. The numLevels macro variable
identifies the number of levels for a class target variable.
data _null_;
set &em_dec_decmeta end=eof;
where _TYPE_='PREDICTED';
call symput('pred_vars'!!strip(put(_N_,BEST.)),
strip(Variable));
call symput('pred_labels'!!strip(put(_N_,BEST.)),
strip(tranwrd(Label,"'","''")));
if eof then
call symput('numLevels', strip(put(_N_,BEST.)));
run;You can loop through
the macro arrays using the numLevels macro variable as the terminal
value for the loop.
If more than one target
variable is used, then &EM_DEC_DECMETA is blank. In that case, you
need to retrieve the names of the decisions data sets (one per target)
from the WORK.EM_TARGETDECINFO data set. The code below demonstrates
how this can be accomplished:
data _null_;
set WORK.EM_TARGETDECINFO;
where TARGET = 'target-name';
call symput('EM_DEC_DECMETA', decmeta);
run;For example, suppose
we modify the attributes of the Home Equity data set making JOB a
target variable in addition to the variable BAD. Then suppose we give
it the following decision profile:
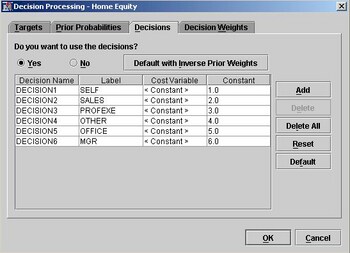
Note: The profile above is for
demonstration purposes only; the values are not intended to represent
a realistic decision profile for business purposes.
data _null_;
set work.em_targetdecinfo;
where TARGET = "JOB";
call symput("em_dec_decmeta", decmeta);
run;This code then causes
the macro variable, &EM_DEC_DECMETA, to resolve to the value,
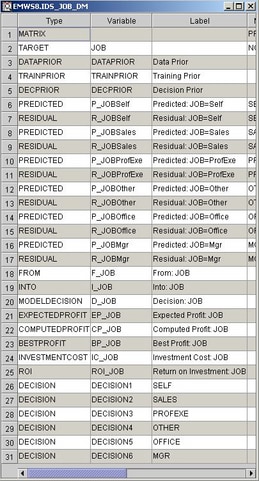
EMWS8.Ids_JOB_DM. Using Explorer once again, you can view the DECMETA
data set for the target variable, JOB:
You would use this code
once for each target variable, making the appropriate substitution for the target-name in the WHERE statement.
If the data sets exported
by the node contain the appropriate predicted variables, the %EM_MODEL
macro can be used to notify the Enterprise Miner environment to compute
fit statistics. It can also generate scoring code that computes classification
(I_, F_, and U_ variables), decision, and residual variables (R_ variables).
Assessment statistics are produced by default, provided those variables
are available.