Impute Missing Values
For decision
trees, missing values are not problematic. Surrogate splitting rules
enable you to use the values of other input variables to perform a
split for observations with missing values. In SAS
Enterprise Miner, however, models such as regressions and neural networks
ignore observations altogether that contain missing values, which
reduces the size of the training data set. Less training data can
substantially weaken the predictive power of these models. To overcome
this obstacle of missing data, you can impute missing values before
you fit the models.
Tip
It is a particularly
good idea to impute missing values before fitting a model that ignores
observations with missing values if you plan to compare those models
with a decision tree. Model comparison is most appropriate between
models that are fit with the same set of observations.
-
The default input method specifies which is the default statistic to use to impute missing values. In this example, the values of missing interval variables are replaced by the median of the nonmissing values. This statistic is less sensitive to extreme values than the mean or midrange and is therefore useful for imputation of missing values from skewed distributions. The values of missing class variables, in this example, are imputed using predicted values from a decision tree. For each class variable, SAS Enterprise Miner builds a decision tree (in this case, potentially using surrogate splitting rules) with that variable as the target and the other input variables as predictors.
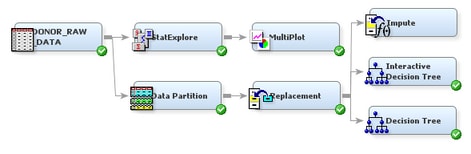
Note: In the data
that is exported from the Impute node, a new variable is created for
each variable for which missing values are imputed. The original variable
is not overwritten. Instead, the new variable has the same name as
the original variable but is prefaced with IMP_. The original version
of each variable also exists in the exported data and has the role
Rejected. In this example, SES and URBANICITY have
values replaced and then imputed. Therefore, in addition to the original
version, each of these variables has a version in the exported data
that is prefaced by IMP_REP_.