Step 9: Set General Preferences
Follow these steps to
set general preferences in SAS Data Loader for Hadoop:
-
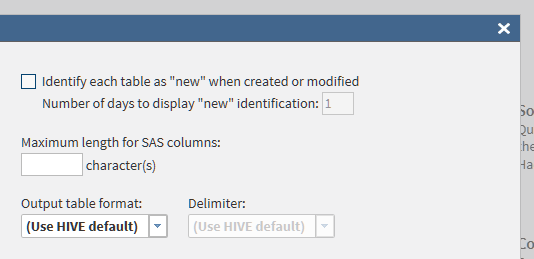
Specify a Maximum length for SAS columns. This maximum prevents errors and manages table size when character data types are read into SAS or written from SAS using SAS/ACCESS. You can specify any integer value between 1 and 32767. Use caution when setting this value, since data truncation can occur if the specified length is too small to accommodate your data.
-
Click Output table format to display the following list of available formats:Click the format that you prefer. All of the target tables that you generate will use the selected format.
-
The Hive default format is the format that is specified in the Hadoop cluster.
-
Text
-
Parquet is a structured format that supports the efficient processing of columns with Impala.
-
Orc, the Optimized Row Columnar format, improves processing efficiency in Hive.
-
Sequence, or SequenceFile, is a key-value format that is used with MapReduce.
-
-
If you prefer the text format, then you can also choose a Delimiter to separate values in tables. You can choose the Hive default, comma, tab, space, or other. If you choose Other, then you enter the delimiter of your choice. The delimiter can be any single character, or a 3-digit octal number, beginning with a backslash. Valid values range from \000 to \177 (1 to 127).

Copyright © SAS Institute Inc. All rights reserved.