Sort and De-Duplicate Data in Hadoop
Introduction

Example
Follow these steps to
use the Sort and De-Duplicate directive:
-
Open SAS Data Loader, as described in Get Started.
-
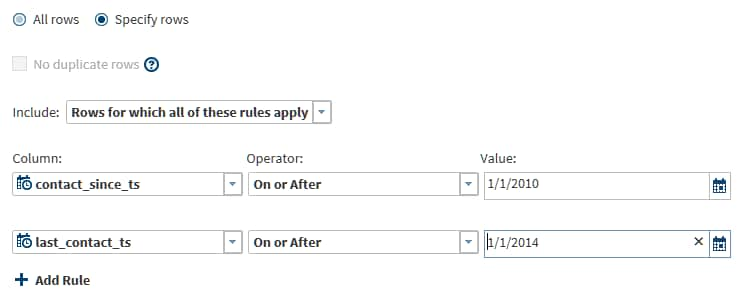
Filter rules are simple expressions that evaluate the values in specified columns. If the expression evaluates to true, then the source row can be written to the target. You can define multiple rules. If you have multiple rules, and if all rules must evaluate to true to write a row to the target, then accept the default value for the Include field.If rows are to be written to the target when one or more rules are true, then select the value Rows for which any of these rules apply. Click Add rule as needed.
-
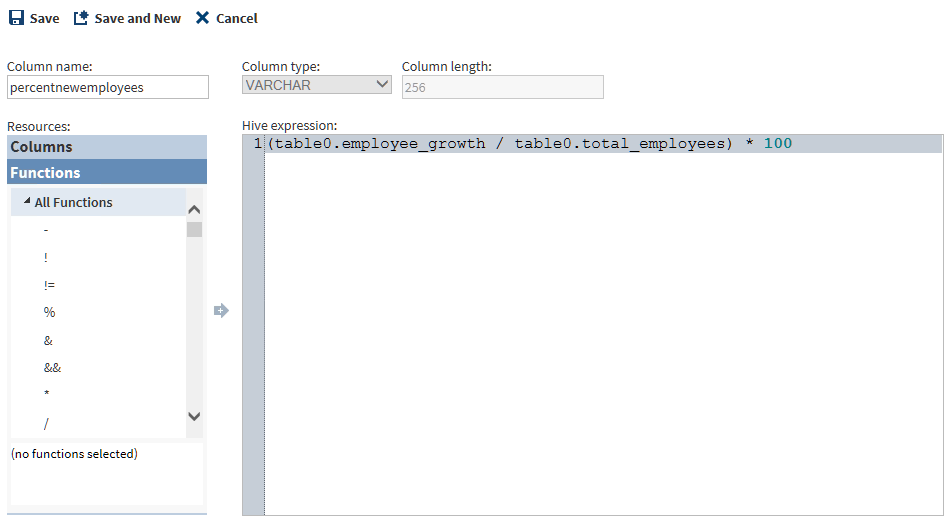
You can generate values for the target table using HiveQL expressions. The values of those expressions can go into existing columns (replacing the source data in those columns,) or the values can go into new columns. You can create the HiveQL expressions by entering or pasting them directly into the Hive Expression column. You can also use the Advanced Editor to generate HiveQL expressions for new or existing target columns. To generate a new column that will contain a HiveQL expression that you create in the Advanced Editor, click
 .
.
-
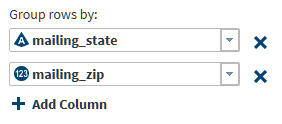
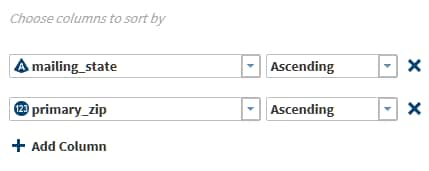
When the target columns are complete, click Next. If you have not defined any summaries in the Summarize Rows page, then the Sort page enables you to group rows based on ascending or descending values in specified columns. If you defined summaries, then the Target Table page enables you to select an existing target table or create a new target table.

Copyright © SAS Institute Inc. All rights reserved.