SAS Representation of CDISC ADaM Metadata
The SAS Clinical Standards
Toolkit provides a SAS metadata representation of each supported standard.
The SAS Clinical Standards Toolkit implementation of the CDISC ADaM
2.1 standard provides an interpretation of the Analysis
Data Model (ADaM), Version 2.1 document and the Analysis
Data Model (ADaM) Implementation Guide, Version 1.0. The
Analysis Data Model identifies four types of ADaM metadata that are
captured and supported by the SAS Clinical Standards Toolkit.
The specific sources
from the ADaM document for each metadata type are shown in the following
table:
|
Metadata Type
|
ADaM Document Source
|
|---|---|
|
Analysis Data Set
|
Section 5.1, Analysis
Data Set Metadata, Table 5.1.1
|
|
Analysis Variable
|
Section 5.2, Analysis
Variable Metadata, Table 5.2.1
|
|
Analysis Parameter
|
Section 5.2.1, Analysis
Parameter Value-Level Metadata
|
|
Analysis Results
|
Section 5.3, Analysis
Results Metadata, Table 5.3.1
|
In the SAS Clinical
Standards Toolkit, the Analysis data set metadata is captured in the
reference_tables and class_tables data sets, which are located here:
global standards library directory/standards/cdisc-adam-2.1-1.7/metadataThe SAS Clinical Standards
Toolkit captures more metadata than might be specified for a standard.
This helps support SAS Clinical Standards Toolkit functionality and
provides greater consistency across supported standards.
The following table
shows the mapping of the Analysis data set metadata defined by the
CDISC ADaM team to the SAS metadata representation in the reference_tables
data set:
|
Analysis Data Set Metadata
Field**
|
Description**
|
reference_tables Column
Mapping
|
|---|---|---|
|
DATASET NAME
|
The file name of the
dataset, hyperlinked to the corresponding analysis dataset variable
descriptions (that is, the data definition table) within the define
file.
|
table
|
|
DATASET DESCRIPTION
|
A short descriptive
summary of the contents of the dataset
|
label
|
|
DATASET LOCATION
|
The folder and filename
where the dataset can be found, ideally hyperlinked to the actual
dataset (that is, XPT file)
|
xmlpath
|
|
DATASET STRUCTURE
|
The level of detail
represented by individual records in the dataset (for example,, “One
record per subject,” “One record per subject per visit,”
“One record per subject per event”).
|
structure
|
|
KEY VARIABLES OF DATASET
|
A list of variable names
that parallels the structure, ideally uniquely identifies and indexes
each record in the dataset.
|
keys
|
|
CLASS OF DATASET
|
Identification of the
general class of the dataset using the name of the ADaM structure
(that is, “ADAE”, “ADSL,” “BDS”)
or “OTHER” if not an ADaM-specified structure
|
class
|
|
DOCUMENTATION
|
Description of the source
data, processing steps, and analysis decisions pertaining to the creation
of the dataset. Software code of various levels of functionality and
complexity, such as pseudo-code or actual code fragments might be
provided. Links or references to external documents (for example,
protocol, statistical analysis plan, software code) might be used.
|
documentation
|
**Source: Analysis
Data Model (ADaM), Version 2.1, Section 5.1, Analysis
Dataset Metadata, Table 5.1.1
The reference_tables
data set provided with the SAS Clinical Standards Toolkit contains
three records for the ADaM ADAE data set, ADaM ADSL data set, and
a representative ADaM BDS data set. CDISC ADaM specifies that only
the ADSL data set is required. Any number of BDS data sets can be
defined as required for each study.
In the SAS Clinical
Standards Toolkit, Analysis Variable metadata is captured in the reference_columns
and class_columns data sets in the global standards library folder:
global standards library directory/standards/cdisc-adam-2.1-1.7/metadataThe following table
shows the mapping of Analysis Variable metadata defined by the CDISC
ADaM team to the SAS metadata representation in the reference_columns
data set:
|
Analysis Variable Metadata
Field**
|
Description**
|
reference_columns Column
Mapping
|
|---|---|---|
|
DATASET NAME
|
The filename of the
analysis dataset
|
table
|
|
VARIABLE NAME
|
The name of the variable
|
column
|
|
VARIABLE LABEL
|
A brief description
of the variable
|
label
|
|
VARIABLE TYPE
|
The variable type. Valid
values are as defined in the Case Report Tabulation Data Definition
Specification Standard (for example, in version 1.0.0 they include
“text,” “integer,” and “float”).
|
xmldatatype
|
|
DISPLAY FORMAT
|
The variable display
information (that is, the format used for the variable in a tabular
or graphical presentation of results). It is suggested that the syntax
be consistent with the format terminology incorporated in the software
application used for analysis (for example, $16 or 3.1 if using SAS).
|
displayformat
|
|
CODELIST / CONTROLLED
TERMS
|
A list of valid values
or allowable codes and their corresponding decodes for the variable.
The field can include a reference to an external codelist (identified
by name and version) or a hyperlink to a list of the values in the
codelist/controlled terms section of the define file.
|
xmlcodelist
|
|
SOURCE / DERIVATION
|
Provides details about
the variable’s lineage – what was the predecessor, where
the variable came from in the source data (SDTM or other analysis
dataset) or how the variable was derived. This field is used to identify
the immediate predecessor source and/or a brief description of the
algorithm or process applied to that sourceand can contain hyperlinked
text that refers readers to additional information. The source /
derivation can be as simple as a two-level name (for example, ADSL.AGEGR)identifying
the data file and variable that is the source of the variable (that
is, a variable copied with no change). It can be a simple description
of a derivation and the variable used in the derivation (for example,
“categorization of ADSL.BMI”). It can also be a complex
algorithm, where the element contains a complete description of the
derivation algorithm and/or a link to a document containing it and/or
a link to the analysis dataset creation program.
|
origin
comment
(supplemented by origin
and algorithm from the source metadata, such as SDTM)
|
**Source: Analysis
Data Model (ADaM), Version 2.1, Section 5.2, Analysis
Variable Metadata, Table 5.2.1
The reference_columns
data set provided with the SAS Clinical Standards Toolkit contains
one record for each column in each of the three data sets (ADSL, BDS,
and ADAE) in the reference_tables data set. This results in 63 records
(columns) for ADSL, 142 records (columns) for BDS, and 85 records
(columns) for the ADAE data set.
Core reference_columns
metadata for each column is in the Analysis Data Model
(ADaM) Implementation Guide, Version 1.0. ADSL Columns as Specified in the Analysis Data Model (ADaM) Implementation Guide provides an excerpt of ADSL column metadata as itemized
in Table 3.1.1 of the Analysis Data Model (ADaM) Implementation
Guide, Version 1.0. This metadata has
been translated into the SAS representation of ADSL as shown in ADSL Columns as Defined in reference_columns Data Set.
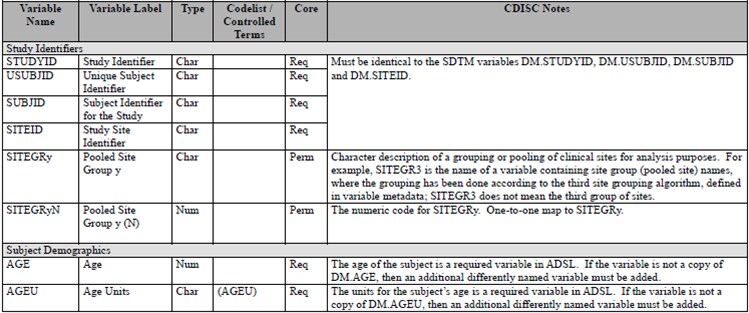
ADSL Columns as Specified in the Analysis Data Model (ADaM)
Implementation Guide
ADSL Columns as Defined in reference_columns Data Set
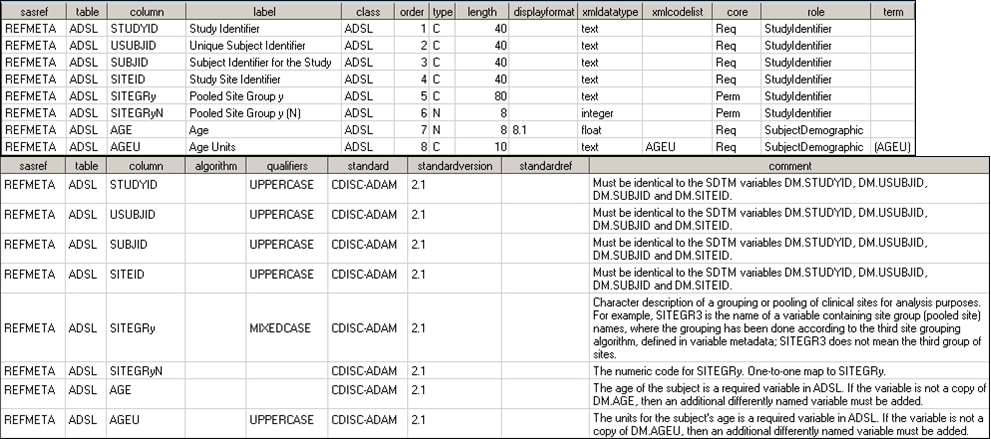
The SAS representation
of ADaM analysis metadata in reference_tables and reference_columns
provides a study template based on the Analysis Data Model
(ADaM), Version 2.1 document and the Analysis
Data Model (ADaM) Implementation Guide, Version 1.0. Each
specific study implementation of ADaM creates multiple BDS data sets.
The number of data sets is determined by the study design, the statistical
analysis plan, and the available source data (for example, SDTM).
Each analysis data set (including ADSL) might contain a different
subset of columns defined by the CDISC ADaM model.
The SAS implementation
makes assumptions about the data type and length of each column. These
assumptions represent a typical implementation consistent with SDTM
metadata and conventions for specific types of columns. For example,
most identifiers have a default length of 40, most flags have a length
of 1, and columns using controlled terminology are defined with a
length that is long enough to capture the longest controlled term.
A third type of metadata
identified in the Analysis Data Model (ADaM), Version 2.1 (see ADaM Document Sources for Each Metadata Type) is analysis
parameter value-level metadata. As noted in the ADaM document:
“Each BDS data
set can contain multiple analysis parameters. In a BDS analysis dataset,
the variable PARAM contains a unique description for every analysis
parameter included in that dataset. Each value of PARAM identifies
a set of one or more rows in the dataset. To describe how variable
metadata vary by PARAM/PARAMCD, the metadata element PARAMETER IDENTIFIER
is required in variable-level metadata for a BDS analysis dataset.
This PARAMETER IDENTIFIER metadata element identifies which variables
have metadata that vary depending on PARAM/PARAMCD, and links the
metadata for a variable to the appropriate value of PARAM/PARAMCD.”
The SAS Clinical Standards
Toolkit CDISC ADaM sample study provides a source_values data set
that captures analysis parameter information. This data set offers
a consistent approach for all CDISC standards that contribute metadata
to the derivation of CRT-DDS (ADaM, SDTM, and SEND).
The following display
shows an excerpt of the sample ADaM source_values data set:
Excerpt of the Sample source_values Data Set
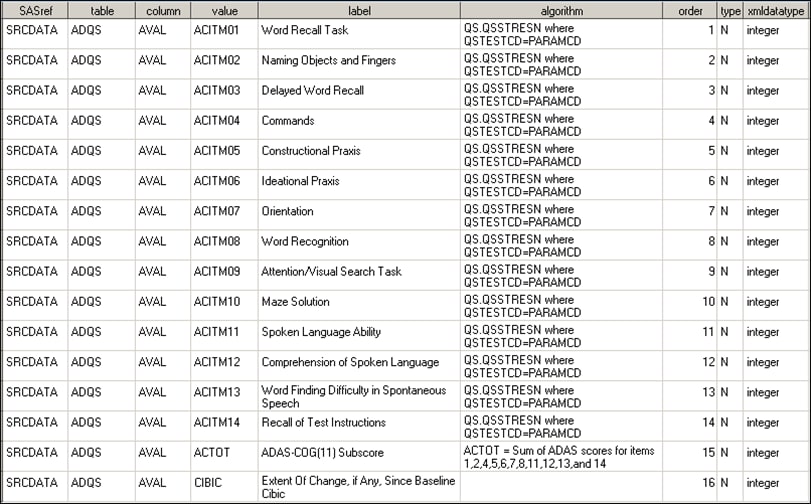
This data set can be
found in
sample study library directory/cdisc-adam-2.1-1.7/sascstdemodata/metadata.
For more information
about analysis parameter value-level metadata, see sections 5.2.1
and 5.2.2 of the Analysis Data Model (ADaM) Version 2.1 document.
The final set of metadata
prescribed by the Analysis Data Model (ADaM) Version 2.1 document
is analysis results metadata. Analysis results metadata is described
in the ADaM document:
“These metadata
provide traceability from a result used in a statistical display to
the data in the analysis data sets. Analysis results metadata are
not required. Analysis results metadata describe the major attributes
of a specified analysis result found in a clinical study report or
submission.”
The metadata fields
used to describe an analysis result are listed in Analysis Results Metadata. The analysis results metadata is illustrated in the SAS
Clinical Standards Toolkit CDISC ADaM sample study analysis_results.sas7bdat
data set found in
sample study library directory/cdisc-adam-2.1-1.7/sascstdemodata/metadata. This sample file
can serve as a template to initialize your analysis results data set,
or see ADaM Data Set Templates.|
Analysis Results Metadata
Field**
|
Description**
|
analysis_results Data
Set Column Mapping
|
|---|---|---|
|
DISPLAY IDENTIFIER
|
A unique identifier
for the specific analysis display (such as a table or figure number)
|
dispid
|
|
DISPLAY NAME
|
Title of display, including
additional information if needed to describe and identify the display
(for example, analysis population)
|
dispname
|
|
RESULT IDENTIFIER
|
Identifies the specific
analysis result within a display. For example, if there are multiple
p-values on a display and the analysis results metadata specifically
refers to one of them, this field identifies the p-value of interest.
When combined with the display identifierprovides a unique identification
of a specific analysis result.
|
resultid
|
|
PARAM
|
The analysis parameter
in the BDS analysis dataset that is the focus of the analysis result.
Does not apply if the result is not based on a BDS analysis dataset.
|
param
|
|
PARAMCD
|
Corresponds to PARAM
in the BDS analysis dataset. Does not apply if the result is not based
on a BDS analysis dataset.
|
paramcd
|
|
ANALYSIS VARIABLE
|
The analysis variable
being analyzed
|
analvar
|
|
REASON
|
The rationale for performing
this analysis. It indicates when the analysis was planned (for example,
“Pre-specified in Protocol,” “Pre-specified in
SAP,” “Data Driven,” “Requested by Regulatory
Agency”) and the purpose of the analysis within the body of
evidence (for example,, “Primary Efficacy,” “Key
Secondary Efficacy,” “Safety”). The terminology
used is sponsor defined. An example of a reason is “Primary
Efficacy Analysis as Pre-specified in Protocol.”
|
reason
|
|
DATASET
|
The name of the dataset
used to generate the analysis result. In most cases, this is a single
dataset. However, if multiple datasets are used, they are all listed
here.
|
datasets
|
|
SELECTION CRITERIA
|
Specific and sufficient
selection criteria for analysis subset and / or numerator–
a complete list of the variables and their values used to identify
the records selected for the analysis. Though the syntax is not ADaM-specified,
the expectation is that the information could easily be included in
a WHERE clause or something equivalent to ensureselecting the exact
set of records appropriate for an analysis. This information is required
if the analysis does not include every record in the analysis dataset.
|
selcrit
|
|
DOCUMENTATION
|
Textual description
of the analysis performed. This information could be a text description,
pseudo code, or a link to another document such as the protocol or
statistical analysis plan, or a link to an analysis generation program
(that is, a statistical software program used to generate the analysis
result). The contents of the documentation metadata element contains
depends on the level of detail required to describe the analysis itself,
whether the sponsor is providing a corresponding analysis generation
program, and sponsor-specific requirements and standards. This documentation
metadata element will remain free form, meaning it will not become
subject to a rigid structure or controlled terminology.
|
document
|
|
PROGRAMMING STATEMENTS
|
The software programming
code used to perform the specific analysis. This includes, for example,
the model statement (using the specific variable names) and all technical
specifications needed for reproducing the analysis (for example, covariance
structure). The name and version of the applicable software application
should be specified either as part of this metadata element or in
another document, such as a Reviewer’s Guide. (See Appendix
B for more information about a Reviewer ’s Guide.)
|
progstmt
|
**Source: Analysis
Data Model (ADaM), Version 2.1, Section 5.3, Analysis
Results Metadata, Table 5.3.1
Note: The structure of the analysis
results metadata as described in Analysis Results Metadata is different from the structure of the metadata that is
needed for creating Analysis Results Metadata 1.0 for Define-XML 2.0
because the latter is based on the 2013 implementation for Define-XML
v2.
Copyright © SAS Institute Inc. All Rights Reserved.