About Template Jobs
Template jobs are provided for processing
both standard Web logs as well as SAS page tag logs. All template
jobs are parameterized jobs that enable you to process multiple clickstream
logs from the same or multiple servers. They also enable you to optimize
processing time through the use of symmetric multi- processing using
SAS MP Connect or grid computing. Finally, the templates manage outputs
and resources to avoid contention.
Note: The SAS Data
Surveyor for Clickstream included a template for processing subsites
in clickstream data through version 2.1. As of version 2.2, this template
is available only in legacy form, as a separate download.
These
multiple template jobs use the same Clickstream Log, Clickstream Parse,
and Clickstream Sessionize transformations that are used in the tutorial
template jobs. The multiple clickstream log files are sent through
a series of loops that are enclosed in the standard SAS Data Integration
Studio Loop and Loop End transformations. In addition, several specialized
transformations prepare the data and parameter values for the loops,
group them to be sessionized, create detailed output, and generate
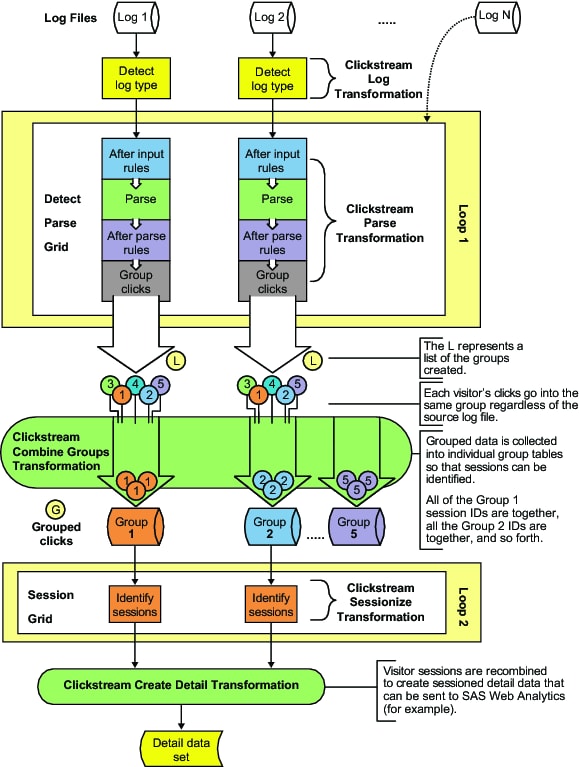
an output table. The Directory Contents transformation generates a
list of raw Web logs to be passed into the first loop. Each iteration
of the loop processes one Web log. Because they can handle more than
one log, you will want to use them in your production environments.
The data
is accessed from the raw Web logs by each parallel SAS session running
in the first loop. Within the first loop, the Clickstream Log transformation
reads a small number of the raw Web log records in order to determine
the Web log type. Once the Web log type is determined, the transformation
creates a SAS DATA step view that is used to read the raw Web log
data. Still within the first loop, the Clickstream Parse transformation
accesses the view built by the Clickstream Log transformation, and
begins to process each incoming click observation as follows:
-
Each observation is placed into an appropriate output group. The output group is decided using a grouping algorithm based on the Visitor ID or Client IP. (The algorithm also uses the User Agent when no Visitor ID value is supplied.) This practice ensures that all of the observations for a specific visitor session are stored in the same group. A list of group files created within each session is represented by L in Standard Clickstream Log Job Process Flow.
The Clickstream Combine Groups generated transformation
reads the group listing files and creates a SAS DATA step view that
combines all the individual group files for a particular group. For
example, the Group 1 data view accesses all of the group 1 data tables
created during processing of the first loop. This transformation also
creates a data table that is represented by G in Standard Clickstream Log Job Process Flow. This data
table contains the list of data views that were created. This list
is used to drive the second loop.
The second
loop again takes advantage of symmetrical multi-processing to identify
visitor sessions and to complete the visitor ID value from the start
to the end of those sessions. This is accomplished using the Clickstream
Sessionize transformation.
The completion
of the visitor ID ensures that the visitor ID value that is assigned
to users after they log on is present on every record of the session.
This persistence holds even when the users browse the site for a period
of time before logging in and after they log off. The visitor ID value
is useful for connecting referring sites (purchased advertising, for
example) to specific visitors and their final activity on the site
(such as completing an online purchase).
Each parallel
session reads observations from one of the group views created by
the Clickstream Combine Groups transformation. Then it creates a single
output data table in which sessions have been identified and visitor
IDs have been completed.
After
the second loop finishes, the Clickstream Create Detail transformation
combines each output from the second loop to create the final composite
detail data table.
The following figure
illustrates the process flow for the standard Web log templates that
are used to process multiple clickstream logs.
Standard Clickstream Log Job Process Flow
When you
process SAS page tag logs, Loop 1 contains two Clickstream Parse transformations.
Sections of this figure are included in the descriptions of each stage
of the template's processing.
Note: This description
of multiple Web log processing is based on the template used to process
a standard Web log. The process for the page-tagging template is slightly
different, as noted in Stages in Template Jobs.