| Sample Size and Power Calculations |
Equivalence Tests
In a test of equivalence, a treatment mean and a reference mean are compared to each other. Equivalence is taken to be the alternative hypothesis, and the null hypothesis is nonequivalence. The power of a test is the probability of rejecting the null hypothesis when the alternative is true, so in this case, the power is the probability of failing to reject equivalence when the treatments are in fact equivalent, that is, the treatment difference or ratio is within the prespecified boundaries.
The computational details for the power of an equivalence test (refer to Phillips 1990 for the additive model; Diletti, Hauschke, and Steinijans 1991 for the multiplicative) are as follows:
Owen (1965) showed that (t1, t2) has a bivariate noncentral t distribution that can be calculated as the difference of two definite integrals (Owen's Q function):
where ![]() is the
is the ![]() quantile of a t distribution with
quantile of a t distribution with ![]() df.
df.
and
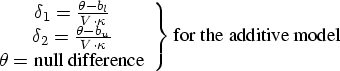
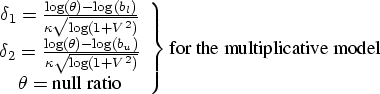
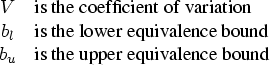
For equivalence tests, alpha is usually set to 0.05, and power ranges from 0.70 to 0.90 (often set to 0.80).
For the additive model of equivalence, the values you must enter for the null difference, the coefficient of variation (c.v.), and the lower and upper bioequivalence limits must be expressed as percentages of the reference mean. More information on specifications follow:
- Calculate the null difference as
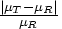 , where
, where 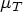 is the hypothesized treatment mean and
is the hypothesized treatment mean and 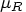 is the hypothesized reference mean. The null difference is often in the range of 0 to 0.20.
is the hypothesized reference mean. The null difference is often in the range of 0 to 0.20. - For the coefficient of variation value,
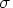 can be estimated by
can be estimated by 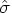 , where
, where 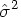 is the residual variance of the observations (MSE). Enter the c.v. as a percentage of the reference mean, so for the c.v., enter
is the residual variance of the observations (MSE). Enter the c.v. as a percentage of the reference mean, so for the c.v., enter 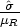 , or
, or 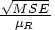 . This value is often in the range of 0.05 to 0.30.
. This value is often in the range of 0.05 to 0.30. - Enter the bioequivalence lower and upper limits as percentages of the reference mean as well. That is, for the bounds, enter
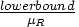 and
and 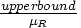 . These values are often -0.2 and 0.2, respectively.
. These values are often -0.2 and 0.2, respectively.
For the multiplicative model of equivalence, calculate the null ratio as ![]() , where
, where ![]() is the hypothesized treatment mean and
is the hypothesized treatment mean and ![]() is the hypothesized reference mean. This value is often in the range of 0.80 to 1.20. More information on specifications follow:
is the hypothesized reference mean. This value is often in the range of 0.80 to 1.20. More information on specifications follow:
- The coefficient of variation (c.v.) is defined as
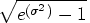 . You can estimate by , where is the residual variance of the logarithmically transformed observations. That is, can be estimated by
. You can estimate by , where is the residual variance of the logarithmically transformed observations. That is, can be estimated by 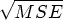 from the ANOVA of the transformed observations. The c.v. value is often in the range of 0.05 to 0.30.
from the ANOVA of the transformed observations. The c.v. value is often in the range of 0.05 to 0.30. - The bioequivalence lower and upper limits are often set to 0.80 and 1.25, respectively.
Copyright © 2007 by SAS Institute Inc., Cary, NC, USA. All rights reserved.