IMS Engine Calls to the Database
Creating the ACCESS Descriptor
To create an access descriptor using the ACCESS procedure, you must first enter the database definition. IMS does not store descriptive information about databases in a dictionary
or database. After you have created an access descriptor, you can select variables
from one path of data when you create a view descriptor. The IMS engine is designed to get its information to build its own SSAs from the view descriptors
and any supplied WHERE clause; these views are based on access descriptors that define
the DL/I databases. The IMS engine uses the information stored in the view descriptor to
generate DL/I calls and to format the results of those calls into SAS observations.
By design, view descriptors cannot access IMS/ESA control region message queues. Therefore, the IMS engine interface is not able to access the message
queues if it is executing in a BMP region.
Data Retrieval
The IMS engine sequentially processes database data in order to flatten IMS records
when no WHERE criteria exist. All data in the
path specified by the view descriptor is returned in the order in which it was stored
in the database when you use unqualified
Get-Next (GN) processing. Therefore, the IMS engine uses qualified segment search arguments (SSAs) to navigate the database path and maintain proper positioning,
basing all qualified Get calls on the results of the previous call. You can use SAS
WHERE statements to perform some level of direct access to a database.
You can see an example of this process by using the view descriptor Vlib.ChkDeb,
which describes the CUSTOMER, CHCKACCT, and CHCKDEBT segments in the
AcctDBD database. First, the IMS engine issues an unqualified Get Unique (GU) call
to position itself at the beginning of
the database. If the CUSTOMER segment were the only segment in the AcctDBD database,
the IMS engine would then issue qualified
Get Next (GN) calls for CUSTOMER until it reached the end of the database. However,
because the AcctDBD database is a multilevel database and the view descriptor defines
more than the root segment, the processing is more difficult. To obtain the dependent segment, the IMS engine must use the value returned in the I/O area for the field designated as the key in order to build a qualified SSA for the parent segment (in this case the root segment).
Next, the IMS engine issues a Get Next Within Parent (GNP) call by concatenating
the qualified SSA for the root segment with an unqualified SSA for the next level down in the hierarchy. The engine then takes the value of the
field designated as the key field of that segment (as defined originally in the access descriptor) from the I/O area to generate a qualified SSA for that level. The next database call is a GNP with the two qualified SSAs concatenated
with an unqualified SSA for
the next level down in the hierarchy. The engine continues to combine qualified SSAs
with an unqualified SSA for the next lowest level down the hierarchy until the lowest
level (as defined in the view descriptor) is retrieved, or until a status of GE is
returned; GE indicates no segment occurrence.
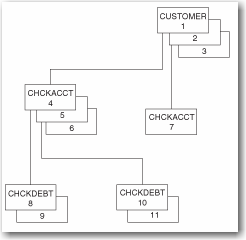
The following figure shows the segments that are described by the view descriptor,
Vlib.ChkDeb, and the order in which the segments are accessed by IMS. The calls
that are generated by the IMS engine to navigate the database are also described.
Note that one SAS observation consists of one complete path of data. If there is no child segment, the IMS engine
passes missing values in the fields for that segment to SAS.
Shown below is the call output that is generated by the IMS engine when it navigates
the database (based on the preceding figure). It is printed to the SAS log by using
SAS IMSDEBUG=Y.
It shows how the IMS engine uses the *U command code to maintain parentage in cases where no key field has been defined for one or more
hierarchical levels in the view descriptor. See Using the *U Command Code for more information.
GU gets CUSTOMER 1 Status Code= GNP CUSTOMER*U-(SSNUMBEREQ667-73-8275) gets CHCKACCT 4 CHCKACCT*-- Status Code= GNP CUSTOMER*U-(SSNUMBEREQ667-73-8275) gets CHCKDEBT 8 CHCKACCT*U-(ACNUMBEREQ345620145345) CHCKDEBT*-- Status Code= GNP CUSTOMER*U-(SSNUMBEREQ667-73-8275) gets CHCKDEBT 9 CHCKACCT*U-(ACNUMBEREQ345620145345) CHCKDEBT*-- Status Code= GNP CUSTOMER*U-(SSNUMBEREQ667-73-8275) CHCKACCT*U-(ACNUMBEREQ345620145345) CHCKDEBT*-- Status Code=GE GNP CUSTOMER*U-(SSNUMBEREQ667-73-8275) gets CHCKACCT 5 CHCKACCT*-- Status Code= GNP CUSTOMER*U-(SSNUMBEREQ667-73-8275) gets CHCKDEBT 10 CHCKACCT*U-(ACNUMBEREQ345620154633) CHCKDEBT*-- Status Code= GNP CUSTOMER*U-(SSNUMBEREQ667-73-8275) gets CHCKDEBT 11 CHCKACCT*U-(ACNUMBEREQ345620154633) CHCKDEBT*-- Status Code= GNP CUSTOMER*U-(SSNUMBEREQ667-73-8275) CHCKACCT*U-(ACNUMBEREQ345620145345) CHCKDEBT*-- Status Code=GE GNP CUSTOMER*U-(SSNUMBEREQ667-73-8275) gets CHCKACCT 6 CHCKACCT*-- Status Code= GNP CUSTOMER*U-(SSNUMBEREQ667-73-8275) CHCKACCT*U-(ACNUMBEREQ345620180723) CHCKDEBT*-- Status Code=GE GNP CUSTOMER*U-(SSNUMBEREQ667-73-8275) CHCKACCT*-- Status Code=GE GN CUSTOMER*-- gets CUSTOMER 2 Status Code= GNP CUSTOMER*U-(SSNUMBEREQ434-62-1234) gets CHCKACCT 7 CHCKACCT*-- Status Code= GNP CUSTOMER*U-(SSNUMBEREQ434-62-1234) CHCKACCT*U-(ACNUMBEREQ345620104732) CHCKDEBT*-- Status Code=GE GNP CUSTOMER*U-(SSNUMBEREQ434-62-1234) CHCKACCT*-- Status Code=GE GN CUSTOMER*-- gets CUSTOMER 3 Status Code= GNP CUSTOMER*U-(SSNUMBEREQ436-42-6394) CHCKACCT*-- Status Code=GE GN CUSTOMER*-- Status Code=GB
Note: The data retrieval process
for GSAM databases is somewhat different. After issuing an initial
close call (CLSE) to establish position at the beginning of the database,
the IMS engine uses unqualified GN calls to retrieve all the data
in the database.
WHERE Statement Processing
There
are many ways to subset data in SAS by using the following tools:
-
a WHERE statement in a view descriptor
-
a SAS WHERE statement in a PROC or DATA step
-
a PROC SQL SELECT statement's WHERE clause
-
a WHERE command in the SAS/FSP procedures
-
a SAS data set WHERE option
These all use SAS WHERE statement syntax. You do not have to use IMS SSA syntax with
the IMS engine that runs under SAS 7 and later.
The IMSI engine attempts to build SSAs from the WHERE conditions that you enter; condition refers to the expression(s) in the WHERE statement, clause, command, or option. The
engine uses these SSAs to qualify each call to the database. Therefore, IMS returns
to SAS only those observations that meet your conditions.
However, if the IMS engine cannot convert the WHERE condition into SSAs, it passes
all database segments referenced by the view descriptor to SAS, which then subsets
and processes the data. Because it uses more resources
to have SAS process WHERE conditions, you should try to use WHERE conditions that
can be turned into valid SSAs when resources are a concern.
To specify WHERE conditions that the IMS engine can use to generate SSAs, use one
of the operators supported by IMS. In the access descriptor, define search field names from the DBD for all the variables included in your WHERE condition when possible. See Writing Efficient WHERE Statements for a list of the operators IMS
supports.
Note: IMS SSAs do not support conditions
that use OR and combine elements from two different segments.
The engine uses the search field names that are entered in the view descriptor for
the field names in the SSAs. Therefore, if you use a SAS variable in a WHERE condition for which you have not defined a search field, the IMS engine
cannot generate SSAs for that WHERE condition.
If the WHERE statement or clause contains multiple conditions and any one of the conditions
cannot generate a qualified SSA, then no qualified SSA is generated from the statement
or clause.
If the IMS engine can handle a WHERE condition, it uses the SEARCH= argument in the
ITEM= statement
to generate a qualified SSA. If possible, the engine combines the qualified SSAs that
it generated to navigate
the database with any WHERE condition SSAs. If both SSAs involve the same field, only
the WHERE SSA is used to avoid a mutually exclusive situation. The engine then issues
a path call to obtain the segments in the hierarchy down to the lowest level with an item specified
in the WHERE condition. All segments in the path are retrieved and passed to SAS.
Therefore, if you use a WHERE condition from which
the IMS engine can generate SSAs, the Program Specification Block (PSB) specified in that view descriptor must let the path calls for the segments in the
hierarchy above and including segments
with variables in the WHERE condition.
For example, if you
enter the WHERE condition
WHERE CHCKACCT = 345620145345
the IMS engine passes the following SSAs to IMS:
CUSTOMER*D- CHCKACCT*--(ACNUMBERREQ345620145345)
The IMS engine uses the results of this call to generate SSAs to navigate the database
further and to flatten out the IMS record as defined in the view descriptor. The
engine combines these navigational SSAs with the SSA that it generated from the WHERE
condition for the CHCKACCT segment. The engine continues processing and retrieves
the view descriptor's lowest level
segment (CHCKDEBT), which is a child of the CHCKACCT segment. CHCKACCT has an ACNUMBER
value that is equal to 345620145345 until the engine does not find another CHCKDEBT
segment (status code GE).
To improve the efficiency of using a WHERE condition to subset your data, use the
operators supported by IMS. Enter the search field names of all variables in the
WHERE condition so that the IMS engine can pass only a subset of data to SAS for further
processing. Use the SAS system
option IMSDEBUG=Y to see whether your WHERE condition is generating SSAs directly.
Note: For GSAM databases, the
IMS engine always passes WHERE clauses to SAS for processing.
Data Retrieval by Using a Secondary Index
The SAS/ACCESS interface enables you to take advantage of secondary indexes in IMS. A secondary
index enables a SAS application to complete the following tasks:
-
Access a segment type in the database in a sequence other than the sequence that is specified by the key field. For example, the application might need to access a database by phone numbers—a field in the root segment of the database—rather than by the Social Security number, which is the segment's key.
-
Change the view of the database data based on a condition in a dependent segment in the database. For example, a banking application might need to access the database (normally accessed by the Social Security number, the root segment's key field) by the checking account number or the savings account number, which are key fields in dependent segments to the root segment.
Because IMS stores root segments in the sequence of their key fields, an application
that accesses the data in another order would be inefficient. A database administrator
(DBA), in conjunction with the SAS application user analyst or programmer, determines
whether a secondary index is needed and assists in laying out the secondary index.
By using secondary indexing,
IMS can go directly to a segment based on a field that is not the key field.
You can define your
access descriptors and view descriptors so that they can access secondary
indexes, as described in this section.
In IMS, when an application requests that a segment be returned based on the database
call and SSA combination, the segment that is returned is called the target segment. If an application requests only one segment, that segment becomes the target segment.
If a sequence of SSAs is used, then the
lowest level segment retrieved in the hierarchy is the target segment. If you issue
a path call for multiple segments, all the segments are returned to the I/O area.
To use secondary indexes with SAS applications, you have to assign certain IMS parameters
and use certain arguments when you create an access descriptor. The PCB that you use must specify the PROCSEQ parameter, which causes IMS to use the secondary
index. You also might need to use the PCBINDX= argument when you create a view descriptor
so that the correct PCB is used by the engine. The secondary index is automatically
accessed when these parameters are assigned.
To create a secondary index, the DBD for the database must contain XDFLD statements
that do the following:
-
define the name of an indexed field that is associated with an index target segment type
-
identify the index source segment type
-
identify the index source segment fields that are used in creating a secondary index.
One XDFLD statement is required for each secondary index relationship.
Combining Segments to Define Descriptors
This section lists ways in which target and source segments can be related and,
therefore,
how you should define your descriptors in order to access the IMS data through a secondary
index.
-
When the source segment and the target segment are the same, and the target segment is the root segment the following is true:The source segmentsupplies the field(s) values that comprise the secondary index. The secondary index stores these values in order with other information that specifies where the target segment is located for any value of the secondary index.The XDFLD statement contains the NAME= value that is used in the SEARCH= argument, because doing so gives the secondary index the same name to be used in the application's SSAs.
-
When the source segment and the target segment are the same, and the target segment is not the root segment the following is true:The database is conceptually restructured. The DBA and the SAS applications analyst or programmer lay out how the database looks conceptually. Physically, the database is still the same. This causes the SAS application to access the data by using the secondary index data structure of the database. For this case, in addition to the scenario described in the first item of this list, the entire access descriptor definition must describe the secondary index data structure and not the primary structure.
-
When the source segment and the target segment are not the same, and the target segment is the root segment the following is true:There is no secondary index data structure because the target segment is the root segment. However, the target and source segments are separate segments in the database.In order for you to create an access descriptor using separate segments, you must add a dummy field to the end of the root segment. This dummy field must contain a length that matches the field(s) length for the target segment key value. In addition, the SEGLNG value for the entire root segment must be increased in the DBD for this additional field. Any valid SAS name can be assigned to this dummy field, but the SEARCH= value must be the XDFLD name for the field from the DBD.In essence, the dummy field is a virtual field in the access descriptor definition for the root. It does not physically exist there, but a SAS application can submit SSA references for the target (in this case the root) that is qualified on this field.For example, consider a SAS application that uses the following WHERE statement:
WHERE sasname EQ value
Sasname is the SAS variable name for the virtual field and value is a value for the field in the source segment. The IMS engine properly builds an SSA for the target (root) that is qualified by using the XDFLD name for the field and the value from the WHERE clause. -
When the source segment and the target segment are not the same, and the target segment is not the root the following is true:This is the most complicated. It combines the scenarios described in the previous two list items. The same dummy field must be added to the target segment as in the previous list item. In addition, the entire access descriptor must map to or define the secondary data structure that results from the target not being the root.
Data Modification Processing
Modifying a hierarchical database such as an IMS database can be complicated. Therefore, you need to know how the IMS
engine operates in order to perform database modifications.
If you plan to use a view descriptor to update the database, the IMS engine requires
that you designate one search field as a key (that is, one key field) for each hierarchical
level in the database. You designate the key field when you create the access descriptor
on which the view descriptor is based. The key fields must be selected in the view
descriptor.
Note: The search field that you
designate as the key must be defined in the DBD as a key field. Otherwise,
updating results might be unpredictable. In addition, you cannot
skip hierarchical levels in a view descriptor that you want to use
to update the database. Because the IMS engine uses path calls to
perform most updates, no ROLB (ROLLBACK) calls are required. If a
path call fails, the engine returns an error to SAS and no update
is performed.
The engine, by default, issues checkpoints at the beginning and end of the update
process.
You can use the AUTOSAVE option with SAS/FSP software to increase the frequency of issuing checkpoints. Your update PSB must
enable path call processing, and an I/O PCB must be included for checkpoint calls.
The only time an update is performed with multiple DL/I calls is when you request
both an update and an insert. For example, you could use
the FSEDIT procedure to update a CUSTOMER segment and, on the same display, enter
information to insert a new CHCKACCT segment under
the CUSTOMER parent segment you just modified. In this case, if the insert call fails
after the engine has processed the modification, the IMS engine issues another update call that replaces the modified parent segment with the original data in that segment.
This process uses fewer resources than a ROLB call. (See How to Use the IMS DATA Step Interface for information about ROLB and other non-database access calls.)
Delete Processing
You can delete only the lowest existing segment defined in the view descriptor.
CAUTION:
If you
delete a segment that has children that are not defined in the view
descriptor, the children are also deleted.
For example, if your view includes the CUSTOMER and CHCKACCT segments only and you
delete a CHCKACCT segment, any CHCKDEBT segments under CHCKACCT are also deleted even
though they are not defined
in the view descriptor.
If your view descriptor includes all the hierarchical levels but a particular segment
has no children, the lowest existing segment is deleted. For example, if a CUSTOMER
segment occurrence has no CHCKDEBT segments under a CHCKACCT segment, issuing the
DELETE command deletes
the CHCKACCT segment. If you then have only a CUSTOMER segment and you issue the
DELETE command, the CUSTOMER segment is deleted.
Note: You cannot delete segments
in a GSAM database.
Add Processing
SAS/FSP software provides three ways to insert new data into an IMS database:
-
To add a path of data to your database, enter the new data using the FSVIEW procedure (with the MODIFY command) or the FSEDIT procedure, and issue the ADD command. The IMS engine adds all the data that you entered as a new path of data in your database.
-
To add a new child segment under an existing root segment that does not have any children, use PROC FSVIEW (with the MODIFY command) or PROC FSEDIT to display the existing segment. Enter the child data on the screen below the existing parent segment.
-
To add a twin segment to an existing child segment, you must first use PROC FSVIEW (with the MODIFY command) or PROC FSEDIT to display the segment to which you want to add a twin. Enter the new data by typing over the existing child, making sure you change the key field of the segment to which you want to add a twin. The IMS engine then inserts a twin segment. Any segments that appear on the screen under the changed segment are also added under the new twin segment in a path call.Note that you can add segments only at the end of a GSAM database.
You can also use the APPEND procedure, DATA step MODIFY statement, or an INSERT statement
in the SQL procedure to add data to an IMS database. To insert a path of data, use
a view descriptor that describes the entire path to be inserted. To insert child
segments under a
parent segment, enter the key field value of the parent segment. The new data is inserted
under the existing parent.
Update Processing
The IMS engine compares the data that you entered to the data that is stored in
the I/O area from the last call. If you change any data in a path of data, the engine replaces
only the segments that have changed in the path. If
you change the key field defined in the view descriptor, the IMS engine inserts a
twin segment occurrence under the current parent segment.
Note: You cannot update segments
in a GSAM database.
Copyright © SAS Institute Inc. All rights reserved.