Understanding the IMS Interface
IMS Interface Concepts
This section
describes concepts that are exclusive to the
SAS/ACCESS interface to the IMS engine. You must understand these concepts in order to successfully use the interface.
This section describes the following concepts:
-
flattened file concept
-
missing values
-
special fields
-
BY variables
Understanding the Flattened File Concept
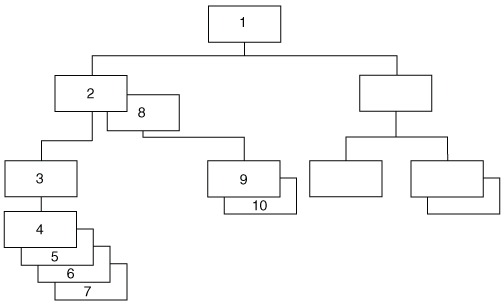
When the IMS engine creates SAS observations from a hierarchical database, it must flatten out the data. The flattened
file concept means that SAS flattens the hierarchical levels and treats one path of data, including the root segment, parent segments, and child segments, as one SAS observation. If the root segment or any parent segment has children, the parent segment is repeated for each child
segment's data. Therefore, each observation contains all the parent segments above
the child segment.
For example, if you access the data in the database shown in Flattened File Concept, the IMS engine returns data from the segments in the following table as SAS observations.
Therefore,
the view descriptor would have to define four segment types.
|
Observation
|
Segments returned
|
|---|---|
|
1
|
1 2 3 4
|
|
2
|
1 2 3 5
|
|
3
|
1 2 3 6
|
|
4
|
1 2 3 7
|
|
5
|
1 8 9 .
|
|
6
|
1 8 10 .
|
If you use the data from these observations in a SAS procedure, it appears that the
data in segment 1 occur six times rather than only once. This can result in misleading
statistics
when you use such procedures as the MEANS procedure that involves any segment except
the child segment in a database with more than two hierarchical levels. It can also
be a problem in second-level
data because root data repeats. To avoid misleading statistics that can result from
flattened files, create view descriptors that describe data in only one hierarchical
level. Or perform statistical operations using data from only the lowest level that
is accessed by the view descriptor.
Using the *U Command Code
The IMS engine generates navigational SSAs to traverse and flatten the database
hierarchy. Because sequential calls perform this task, the database's current position
is an important issue. (See Database Position for more information.)
Using a *U command code ensures the current database position on the proper parent segment as a DL/I call moves down the hierarchy to the next target segment (the segment named in the last
SSA). *U on the immediate parent of the target means that even if the parent is unqualified,
the position indicator remains there and does not move to a child (target segment)
that belongs to a different parent occurrence.
For example, when DL/I processes a Get or ISRT call, it establishes a position on the segment occurrence that satisfies the call at each level in the path of the segment (target) that you
are retrieving or inserting. A *U command code on an SSA in a Get or ISRT call tells
DL/I not to move from the established database position at the level of the SSA when
trying to satisfy the call. You use an ISRT
call and I/O or TP PCBs to insert messages to the IMS/ESA control region message queues when a SAS program is executing in a BMP region. See ISRT Calls to Message Queues.
Handling Missing Values
This
section describes how the SAS/ACCESS interface to IMS handles missing data values. It also describes how the DB Content
field affects how data is displayed and stored in the database.
If you create a view descriptor to add an IMS-DL/I database segment and fields in that segment are not defined, the IMS engine writes
low values to the database fields that are not included in the descriptor.
The engine does so because it does not know that the fields exist.
If there are missing values in a SAS data set that you use to add or update an IMS database, the IMS engine writes zeros to the
database for numeric fields and blank spaces to the database
for character fields unless you specify a special format (B, L, or H) for the DBCONTENT=
argument of the ITEM= statement. DBCONTENT= affects how the engine updates the fields.
(See ITEM= Statement for more information about special formats.)
Conversely, if a field is defined with a DBCONTENT= value and the database retrieves
that value (blanks, low values, or high values) in the field, then the
IMS engine passes missing values to SAS. In addition, if a view descriptor describes
more than one level in a database, and not all the levels exist for one
database record, the IMS engine fills the missing segment occurrence with missing
values in the SAS observation.
Using BY Variables
If you specify an IMS view descriptor as input to a SAS procedure that uses a BY variable,
you must either
-
create a SAS data file from the IMS data (that is, extract the data) and sort the data using that variable. You then specify the newly created data file in your procedure.
-
reference a SAS variable associated with a database index in the BY statement. That is, the BY variable must be defined as the index key.
Handling Special Fields
Handling Fields That Occur Multiple Times
An item or a group in an IMS database segment can occur more than one time. For example,
in the example database AcctDBD, the two
phone number fields, home phone and office phone, could be defined in your access descriptor as one fieldthat occurs two times. To do this, specify OCCURS=2 in the ITEM= statement for the
phone number field when you create the access descriptor. When you save the access
descriptor, the descriptor is expanded to show fields
for two phone numbers. When the IMS engine reads the database, it retrieves two phone
numbers for each customer.
Fields that occur multiple times in the database can be nested only three levels
deep, which creates a three-dimensional table. The
following example shows the definition of a record with fields that occur multiple
times, nested three levels deep:
01 Automatic Teller Record
02 ATM Information
03 ATM Location (occurs 20 times)
04 Location
04 ATM Transaction Information (occurs 7 times)
05 Account Type
05 Transaction Time
05 Transaction (occurs 2 times)
06 Transaction Type
06 Transaction AmountAfter you have saved an access descriptor, you cannot change the number in the OCCURS=
argument. Instead, you have to delete
an item and re-enter it with the correct number in OCCURS=.
Handling Redefined Fields
Redefined fields are fields that have been defined with more than one data type. For example, some records in a database might store character values in a certain
field, and other records in the same database might have numeric values stored in
that
same field. You could handle this by defining the field as
$11. in one access descriptor and 11. in another access descriptor based on the same database. When you create view descriptors
for the database, use a WHERE statement to retrieve only the appropriate values for
the field. This can often be done by specifying a particular record type or other code in the WHERE statement.
Handling Segments of Varying Length
If you work with a segment that contains a field that varies in length, specify
the maximum length of the varying field for SEGLNG=
when you define the segment in the access descriptor. When IMS retrieves the entire
segment, it fills in the varying portion with missing
values if it did not retrieve any data for that portion of the segment.
Handling GROUP Keys in Descriptor Files
To support a definition of a GROUP field as a key and to be able to have access
to the GROUP items, you need to define a dummy
field for this key.
In IMS, GROUPs enable the same portion of data in a buffer to be assigned different
logical names. For example, a field that begins at offset 1 for a length of 15 can
be named FIELD1. Other fields can
be defined within FIELD1, such as in FIELD2, FIELD3, and FIELD4 that begin at offsets
1, 6, and 11, respectively (where each has a length of 5).
Because no SAS variable name can be specified in the GROUP= statement, no single reference
can be made to
the group in the WHERE criteria. Therefore, even if a valid SEARCH or SEQ name exists
for the GROUP in the DBD, the IMS engine cannot qualify calls that are based on the group itself.
A simple solution is to define the entire group as an item and to assign the SAS variable
name and SEARCH name appropriately. Then you can specify a WHERE statement in your
view descriptor or application and the IMS engine builds qualified SSAs. A problem
remains if the application wants access to the
components of the GROUP. In this case, you must reference the view descriptor in
a DATA step to SUBSTR out the parts and store them in separate SAS variables.
Using Dummy Fields for GROUP Keys
You can define a dummy field in the segment for a GROUP key in order to permit
a WHERE clause reference for qualified SSAs and
to access the composite fields. The GROUP statement defines the group but you can
take it a step further. You add a dummy field to the end of the segment definition
as an ITEM with a length that is equal to the entire GROUP and a SEARCH= value equal
to the DBD SEARCH or SEQ field name from the DBD (the GROUP SEARCH= also has this
value). The
SEGLNG value is increased for this field.
By using a dummy field for the GROUP, you can specify in your view descriptor a WHERE
clause as follows:
WHERE sas-dummy-name EQ value
In this case, the IMS engine locates the dummy field in the view descriptor through
the SAS variable name in the WHERE clause. It uses its SEARCH= value to qualify the
SSA. When the data comes back to the buffer, the true data is in the GROUP portion
of
the segment definition and its component values are stored in the SAS variables that
are associated
with the items that are defined for the GROUP.
Also, by marking the GROUP itself as the key (with the KEY= argument), navigational
SSAs that are generated by the IMS engine for sequential GN calls refer to the correct
buffer location for the data. The navigational
SSAs use the correct SEARCH= value in the SSA.
CAUTION:
You must
never refer to the dummy field as the key (with KEY=) because doing
so would force the IMS engine to use the dummy buffer location to
qualify navigational SSAs for GN calls. This would cause problems.
Below is an example of an access descriptor and a view descriptor based on the AcctDBD.
The GROUP key is on home phone, which has a dummy field (GROUP STUFF) defined for
it.
proc access dbms=ims;
create work.account.access;
dbd=acctdbd dbtype=hdam;
record='customer_record' sg=customer sl=225;
item=soc_sec_number lv=2 dbf=$11. key=u
se=ssnumber;
item=customer_name lv=2 dbf=$40.
se=custname;
item=addr_line_1 lv=2 dbf=$30.
se=custadd1;
item=addr_line_2 lv=2 dbf=$30.
se=custadd2;
item=city lv=2 dbf=$28.
se=custcity;
item=state lv=2 dbf=$2.
se=custstat;
item=country lv=2 dbf=$20.
se=custland;
item=zip_code lv=2 dbf=$10.
se=custzip;
group=home_phone lv=2
se=custhphn;
item='area code' lv=3 dbf=$3.
item=filler1 lv=3 dbf=$1.
item=phone_number lv=3 dbf=$8.
item=office_phone lv=2 dbf=$12.
se=custophn;
item='group stuff' lv=2 dbf=$12.
se=custhphn;
list all;
create work.phone.view psbname=acctsam pcbindex=2;
select soc_sec_number customer_name 'area code'
'phone number' 'group stuff';
list view;
run;
proc print data=work.phone;
var soc_sec_number customer_name 'area code'
'phone number';
where 'group stuff' = '803-657-1346' or
'group stuff' = '803-657-1687';
run;The following output
shows the results.
Results of a Dummy Field for a GROUP Key
The SAS System
OBS soc_sec_number customer_name 'area code' 'phone number'
1 436-42-6394 BOOKER, APRIL M. 803 657-1346
2 178-42-6534 PATTILLO, RODRIGUES 803 657-1346
3 434-62-1234 SUMMERS, MARY T. 803 657-1687Using Filler Notation in ITEM=
It is important that access descriptor segment definitions not omit ITEM and GROUP
references for fields that are embedded in the
segment. Database segments might contain fields (contiguous or discontiguous) that
applications might not need to access. In these cases, it is correct not to define
them in SAS/ACCESS view descriptors. For performance reasons, it is recommended that applications not
define them so that the IMS engine does not invoke conversion routines to convert
data that is not used.
Sites commonly refer to undesired portions of the data buffer by using the FILLER
notation in the ITEM= statement, and by defining the DBC (DB Content) as $CHAR. If
the undesired portion of the segment lays beyond all the desired segment fields, applications
do not have to define these
portions of the segment. However, you must make sure that the SEGLNG value for the
segment is equal to the length of the entire segment and not just to the portion of
the segment that they are interested in defining.
When the undesired fields are embedded between desired fields, you must use the FILLER
notation or something similar (FILLER is a reserved word in COBOL but not in SAS).
SAS uses relative offsets to locate defined fields in the buffer when converting data
from the IMS buffer to the SAS program data vector (PDV). By using the field lengths
from the DBC, SAS determines the offset and length in the IMS buffer for
the current field as needed to map to the PDV. If a field or series of fields is undesired,
information must be supplied about placement and length so that SAS can move correctly
to the next valid field to be mapped.
FILLER fields can be coded as DBC of $CHAR, which requires no conversion if selected
for a view descriptor. In most cases FILLER fields are not selected. By preserving
the relative offsets
of fields within the buffer using FILLER definitions, the IMS engine can correctly
map data that is requested by the application or view descriptor to
the PDV.
Below is an example of a root segment for the ACCOUNT database with all of the fields
defined from the DBD.
record='customer_record' segment=customer
seglng=225;
item=soc_sec_number lv=2 dbf=$11.
search=ssnumber key=y;
item=customer_name lv=2 dbf=$40.
search=custname;
item='address info' lv=2;
item=addr_line_1 lv=3 dbf=$30.;
item=addr_line_2 lv=3 dbf=$30.;
item=city lv=3 dbf=$28.;
item=state lv=3 dbf=$2. ;
item=country lv=3 dbf=$20.;
item=zip_code lv=3 dbf=$10.;
item=home_phone lv=2 dbf=$12.;
item=office_phone lv=2 dbf=$12.;Assuming that none of
your view descriptors would ever require phone information, you could
code the following:
record='customer_record' segment=customer
seglng=225;
item=soc_sec_number lv=2 dbf=$11.
search=ssnumber key=y;
item=customer_name lv=2 dbf=$40.
search=custname;
item='address info' lv=2;
item=addr_line_1 lv=3 dbf=$30.;
item=addr_line_2 lv=3 dbf=$30.;
item=city lv=3 dbf=$28.;
item=state lv=3 dbf=$2. ;
item=country lv=3 dbf=$20.;
item=zip_code lv=3 dbf=$10.;Note that the SEGLNG=
value does not change even though two fields at the end are dropped.
By comparison, assume
that the application needs everything except the address information:
record='customer_record' segment=customer
seglng=225;
item=soc_sec_number lv=2 dbf=$11
. search=ssnumber key=y;
item=customer_name lv=2 dbf=$40.
search=custname;
item='filler' lv=2 dbf=$char60.;
item=city lv=3 dbf=$28.;
item=state lv=3 dbf=$2. ;
item=country lv=3 dbf=$20.;
item=zip_code lv=3 dbf=$10.;
item=home_phone lv=2 dbf=$12.;
item=office_phone lv=2 dbf=$12.;Here, the FILLER preserves
60 bytes so that view descriptors that reference fields past the filler
can get data mapped correctly from the IMS buffer to the PDV variables
based on the relative offset information. Once again, SEGLNG= does
not change.
Copyright © SAS Institute Inc. All rights reserved.