Usage Note 22601: Adjusting for oversampling the event level in a binary logistic model
 |  |  |
Introduction
This situation is also called oversampling, retrospective sampling, biased sampling, or choice-based sampling. In the biological sciences, studies using this kind of sampling are known as case-control studies.
Parameter and odds ratio estimates of the covariates (and their confidence limits) are unaffected by this type of stratified sampling, so no weighting is needed. However, the intercept estimate is affected by the sampling, so any computation that is based on the full set of parameter estimates is incorrect, such as the predicted event probabilities, differences or ratios of event probabilities (the ratio is called the relative risk), and false positive and negative rates. If you know the probabilities of events and nonevents in the population, then you can adjust the intercept either by weighting or by using an offset.
Adjusting the Intercept
To adjust by weighting, add a variable to your data set that takes the value p1/r1 in event observations, and the value (1-p1)/(1-r1) in nonevent observations, where p1 is the probability of an event in the population and r1 is the proportion of events in your data set. Specify this variable in the WEIGHT statement in PROC LOGISTIC.
Or, to adjust by using an offset, add a variable to your data set defined as log[(r1*(1-p1)) / ((1-r1)*p1)], where log represents the natural logarithm. Specify this variable in the OFFSET= option of the MODEL statement in PROC LOGISTIC.
These two methods are not equivalent. The weighting method seems to perform better when the model is not correctly specified. For details, see Scott and Wild (1986), "Fitting Logistic Models under Case-Control or Choice-Based Sampling," Journal of the Royal Statistical Society B, 48.
Adjusting the Predicted Probabilities
The weighting method also has the advantage of directly providing properly adjusted predicted probabilities via the PREDICTED= or PREDPROBS= option in the OUTPUT statement. Prior to SAS® 9, the offset method requires using PROC SCORE to obtain predicted logits, ignoring the offset, followed by a DATA step to transform the logits to probabilities. This is somewhat inefficient computationally, which could be a problem with large data sets. But beginning with SAS 9, you can use the PRIOR= or PRIOREVENT= option in the SCORE statement to input the population event and nonevent probabilities and obtain predicted probabilities that are equivalent to those produced by the offset method. These methods are illustrated below.
For more information about analyzing data from stratified sampling, see Hosmer and Lemeshow (2000) or Collett (2003).
Example
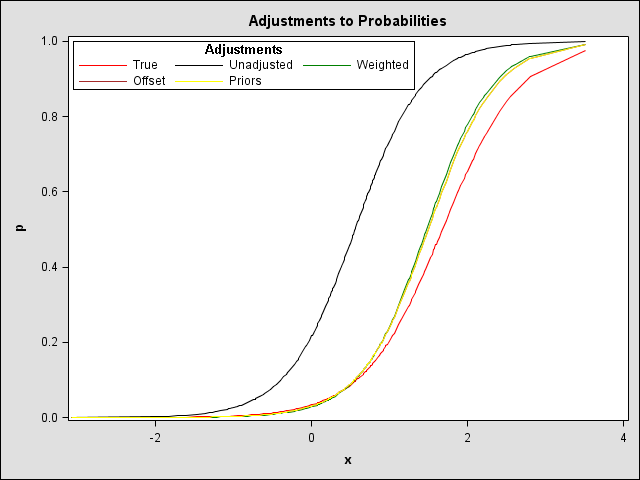
The following example illustrates obtaining predicted probabilities adjusted for oversampling. Data set FULL is created containing a binary response, Y (with event=1 and nonevent=0), and predictor, X. The true model from which the data is generated is logit(p) = -3.35 + 2*X, resulting in approximately a 0.1 overall proportion of events. A subset (data set SUB) of this data set is obtained by oversampling—all Y=1 observations and one-ninth of the Y=0 observations are retained resulting in a sample with approximately equal numbers of events and nonevents. The offset (OFF) and weights (W) are computed as discussed above using the known population and sample event probabilities. An unadjusted logistic regression and offset- and weight-adjusted logistic regressions are run yielding corrected intercepts. Predicted probabilities are computed as discussed above and a plot is presented of the true, unadjusted, offset-adjusted and weight-adjusted probabilities. All results are accumulated in data set OUT.
data full;
do i=1 to 1000;
x=rannor(12342);
p=1/(1+exp(-(-3.35+2*x)));
y=ranbin(98435,1,p);
drop i;
output;
end;
run;
data sub;
set full;
if y=1 or (y=0 and ranuni(75302)<1/9) then output;
run;
proc freq data=full;
table y / out=fullpct(where=(y=1) rename=(percent=fullpct));
title "response counts in full data set";
run;
proc freq data=sub;
table y / out=subpct(where=(y=1) rename=(percent=subpct));
title "Response counts in oversampled, subset data set";
run;
data sub;
set sub;
if _n_=1 then set fullpct(keep=fullpct);
if _n_=1 then set subpct(keep=subpct);
p1=fullpct/100; r1=subpct/100;
w=p1/r1; if y=0 then w=(1-p1)/(1-r1);
off=log( (r1*(1-p1)) / ((1-r1)*p1) );
run;
proc logistic data=sub;
model y(event="1")=x;
output out=out p=pnowt;
title "True Parameters: -3.35 (intercept), 2 (X)";
title2 "Unadjusted Model";
run;
proc logistic data=out;
model y(event="1")=x; weight w;
output out=out p=pwt;
title2 "Weight-adjusted Model";
run;
proc logistic data=out;
model y(event="1")=x / offset=off;
output out=out xbeta=xboff;
title2 "Offset-adjusted Model";
run;
data out;
set out;
poff=logistic(xboff-off);
run;
proc freq data=full noprint;
table y / out=priors(drop=percent rename=(count=_prior_));
run;
proc logistic data=out;
model y(event="1")=x;
score data=sub prior=priors out=out2;
title2 "Unadjusted Model; Prior-adjusted probabilities";
run;
data out;
merge out out2;
drop _lev:;
run;
These statements produce the following graph of adjusted probabilities using PROC SGPLOT.NOTE
proc sort data=out;
by x;
run;
proc sgplot data=out;
title "Adjustments to Probabilities";
series y=p x=x / name="p" legendlabel="True" lineattrs=(color=red pattern=solid);
series y=pnowt x=x / name="pnowt" legendlabel="Unadjusted" lineattrs=(color=black pattern=solid);
series y=pwt x=x / name="pwt" legendlabel="Weighted" lineattrs=(color=green pattern=solid);
series y=poff x=x / name="poff" legendlabel="Offset" lineattrs=(color=brown pattern=solid);
series y=p_1 x=x / name="p_1" legendlabel="Priors" lineattrs=(color=yellow pattern=solid);
keylegend "p" "pnowt" "pwt" "poff" "p_1" /
position=topleft across=3 down=3 border title="Adjustments" location=inside;
run;
Note that the offset-adjusted probabilities match those from using the PRIOR= option in the SCORE statement. Both the offset and the weight adjustments come closer to the true probabilities than the unadjusted probabilities which are incorrect because of the unadjusted intercept. The offset adjustment seems slightly better than the weight adjustment in this case, possibly because the correct model is specified. With a larger initial data set (say, 10000) and sample (1000 events and nonevents), both adjustment methods yield very similar probabilities very close to the true probabilities.
 |
__________
Note: These statements produce the same graph in SAS 9 or later using a custom graph template.
ods select all;
ods html;
ods graphics on;
proc template;
define statgraph LOGAdj / store = SASUSER.TEMPLAT;
notes "plot of various adjustments for oversampling";
layout overlay;
series y=p x=x / sort=x name="p"
legendlabel="True" linecolor=red;
series y=pnowt x=x / sort=x name="pnowt"
legendlabel="Unadjusted" linecolor=black;
series y=pwt x=x / sort=x name="pwt"
legendlabel="Weighted" linecolor=green;
series y=poff x=x / sort=x name="poff"
legendlabel="Offset" linecolor=brown;
series y=p_1 x=x / sort=x name="p_1"
legendlabel="Priors" linecolor=yellow;
discretelegend "p" "pnowt" "pwt" "poff" "p_1" /
halign=left valign=top across=3 down=3 border=on
title="Adjustments" titleborder=on;
endlayout;
end;
run;
title "Adjustments To Probabilities";
title2;
data _null_;
set out;
file print ods=(template='LOGAdj');
put _ods_;
run;
ods graphics off;
ods html close;
Operating System and Release Information
| Product Family | Product | System | SAS Release | |
| Reported | Fixed* | |||
| SAS System | SAS/STAT | All | n/a | |
| Type: | Usage Note |
| Priority: | low |
| Topic: | SAS Reference ==> Procedures ==> LOGISTIC Analytics ==> Categorical Data Analysis Analytics ==> Regression |
| Date Modified: | 2017-04-20 09:56:24 |
| Date Created: | 2002-12-16 10:56:38 |