Specifying a Table Input for a Process Job Node
You can specify the output table from one node as the input to the next node in a process job. In the job shown in the next display, the Work Table Reader 1 node gets the output table from Data Job 2.
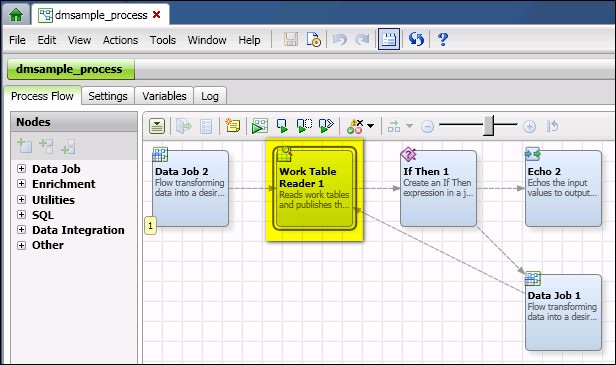
Work Table Reader 1 Gets the Output Table from Data Job 2
Perform the following steps to specify the output table from one node as the input to the next node in a process job. It is assumed that you are working in a process job with at least one node that produces an output table. If you need help with creating such a job, see Creating a Process Job.
- Open the properties dialog for a node that comes after a node that produces an output table .
- Click the Inputs tab.
- Select the row for the TABLE property, as shown in the next display.
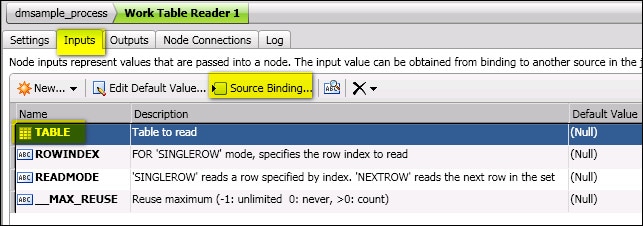
- Click Source Binding. If an input table is available, the Source Binding wizard displays.
- Select a table, as shown in the next display.
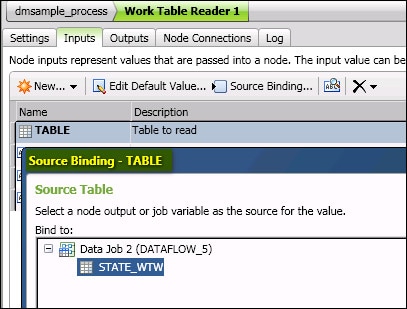
- Click Next. The Source Column page displays.
- Select the appropriate option from the Import Input Columns control, such as From Source Table. The wizard will try to map the source column to a column for the current node. In the next display, a single output column (STATE) is available from the source table, so it is automatically mapped as an input column for the current node.
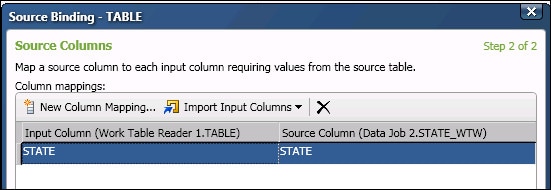
- Click Finish to apply the source binding. The next step is to specify the method for reading the table.
- Select the row for the READMODE property. Expand the row so that you can read the description of the two options for this property. SINGLEROW reads a row specified by index. NEXTROW reads the next row in the set.
- Click Edit Default Value. Enter NEXTROW unless you know that an index is available.
- Click OK to save the value for READMODE.
Typically you will not change the default for the __MAX_REUSE property. You should now have a working table input for the current node.