预测回归模型


对数据进行分区
如果您有足够的数据,则可以将数据分为三个部分:训练数据、验证数据和测试数据。在选择过程期间,模型在训练数据的基础上进行拟合,而模型的预测误差则是使用验证数据进行确定。此预测误差既可用于确定选择过程的终止时间,也可用于确定在选择过程期间包括哪些效应。最后,在模型选定后,测试数据可用于评估选定模型如何概括对模型选择不起任何作用的数据。
您可以选择以下一种方式对数据进行分区:
-
您可以指定一定比例的验证数据或测试数据。此比例可用于按抽样对输入数据进行划分。
-
如果输入数据集中包含的变量的值可指明观测是验证观测还是测试观测,则可以指定在对数据进行分区时使用的变量。在指定变量时,还需要选择验证观测或测试观测的相应值。系统使用下列值将输入数据集分入各个分区。
向角色分配数据
要运行“预测回归模型”任务,必须向因变量角色分配列,并向分类变量角色或连续变量角色分配列。
|
角色
|
说明
|
|---|---|
|
角色
|
|
|
因变量
|
指定用作回归分析的因变量的数值变量。
|
|
分类变量
|
指定在分析中用于分组(分类)数据的变量。分类变量是指通过水平(而不是值)进入统计分析或统计模型的变量。将变量值与水平相关联的过程称为水平化。
|
|
效应参数化
|
|
|
编码
|
指定分类变量的参数化方法。设计矩阵列根据选定编码模式从分类变量中创建。
可以从以下编码模式中进行选择:
|
|
缺失值处理
|
|
|
若模型中任何变量包含缺失值,观测将从分析中排除。另外,如果此表中之前指定的任何分类变量包含缺失值,无论其是否在模型中使用,系统都会排除观测。
|
|
|
连续变量
|
为回归模型指定独立协变量(回归变量)。如果没有指定连续变量,则此任务拟合仅包含截距的模型。
|
|
其他角色
|
|
|
频数计数
|
列出其值代表观测频数的数值型变量。如果向此角色分配一个变量,则任务将假设每个观测代表 n 个观测,其中 n 表示频数变量值。如果 n 不是整数,则 SAS 会将其截断。如果 n 小于 1 或缺失,则系统会从分析中排除观测。频数变量的总和代表总观测数。
|
|
权重
|
指定用作对数据执行权重分析所需的权重的数值列。
|
|
分析分组依据
|
指定创建每组观测的单独分析。
|
选择模型
|
选项名称
|
说明
|
|---|---|
|
模型选择
|
|
|
选择方法
|
默认情况下,指定的完整模型将用于拟合模型。不过,也可以使用以下选择方法之一:
|
|
选择方法(续)
|
向前选择
指定向前选择。该方法以模型中无任何效应开始并添加效应。
向后消除
指定向后消除。此方法最初在模型中添加所有效应,然后删除效应。
逐步回归
指定逐步回归,此方法与向前选择方法类似,不同之处在于不必保留模型中的现有效应。
LASSO
指定 LASSO 方法,此方法根据普通最小二乘版本添加和删除参数,在最小二乘版本中,绝对回归系数的总和已被约束。若模型包含分类变量,则这些分类变量是拆分变量。
适应 LASSO
要求将自适应权重应用于 LASSO 方法中的每个系数。模型中参数的普通最小二乘估计用于形成自适应权重。
|
|
选择方法(续)
|
弹性网络
指定弹性网络方法,该方法属于 LASSO 的延伸。弹性网络方法基于普通最小二乘版本估计参数,在最小二乘版本中,绝对回归系数和以及回归系数平方和已被约束。若模型包含分类变量,则这些分类变量是拆分变量。
最小角度回归
指定最小角度回归。该方法以模型中无任何效应开始并添加效应。当与相对应的最小二乘估计比较时,任何步骤的参数估计都会“收缩”。若模型包含分类变量,则这些分类变量是拆分变量。
|
|
添加/删除效应
|
指定用于确定应该添加还是从模型中删除效应的准则。
|
|
停止添加/删除效应
|
指定用于确定应该停止添加还是从模型中删除效应的准则。
|
|
选择最佳模型的方法
|
指定用于确定最佳拟合模型的准则。
|
|
选择统计量
|
|
|
模型拟合统计量
|
指定要在拟合汇总表和拟合统计量表中显示的模型拟合统计量。若选择默认拟合统计量,在这些表中显示的统计量的默认设置包括所有用于模型选择的准则。
下面是您可以在结果中包括的其他拟合统计量:
|
|
选择图
|
|
|
准则图
|
显示以下准则的图:调整 R 方、Akaike 的信息准则、小样本偏差的校正的 Akaike 信息准则和用于选择最佳拟合模型的准则。您可以选择是在面板中显示这些图还是单独显示。
|
|
系数图
|
显示以下图:
|
|
详细信息
|
|
|
选择过程详细信息
|
指定要包括在结果中的关于选择过程的信息量。可以显示汇总、选择过程每个步骤的详细信息或关于选择过程的全部信息。
|
|
添加/删除分类效应
|
指定哪些分类变量作为一个或多个实际变量纳入模型中。变量数与分类变量的水平数相关。例如,如果一个分类变量有三个水平(young、middle-aged、old),则有
3 个变量代表分类变量。每个变量是一个单自由度效应。
可从下列选项中选择:
|
|
模型效应层次
|
|
|
模型效应层次
|
指定模型层次要求应用的方式以及每次仅单一效应或多效应可以进入或离开模型。例如,假设您在模型中指定主效应 A 和 B 与交互效应 A*B。在选择过程的第一步中,A 或
B 其中一个进入模型。在第二步中,另一个主效应进入模型。仅当两个主效应均已进入模型后,交互效应才可以进入模型。而且,从模型删除 A 或 B 之前,必须先删除 A*B
交互。
模型层次指以下要求:对于任何将进入模型的项,所包含的所有效应必须呈现在模型中。例如,若交互 A*B 要进入模型,则主效应 A 和 B必须在模型中。同样,交互 A*B
在模型中时,效应 A 和 B 都无法离开模型。
|
|
受限于层次要求的模型效应
|
指定是将模型层次要求应用于模型中的分类和连续效应还是仅用于分类效应。
|
设置最终模型选项
|
选项名称
|
说明
|
|---|---|
|
选定模型的统计量
|
|
|
您可以选择是在结果中包含默认统计量还是包含其他统计量(如标准化回归系数)。标准化回归系数通过将参数估计除以因变量样本标准差与回归变量样本标准差的比率计算得出。
|
|
|
共线性
|
|
|
共线性分析
|
获取回归变量之间的详细的共线性分析。包括特征值、条件指数和有关每个特征值的估计的方差分解。
|
|
估计的容差值
|
生成估计的容差值。变量容差值定义为
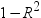 ,其中 R 方是通过此变量对模型中其他所有回归变量进行回归分析计算得出的。 ,其中 R 方是通过此变量对模型中其他所有回归变量进行回归分析计算得出的。
|
|
方差膨胀因子
|
生成具有参数估计的方差膨胀因子。方差膨胀是容差的倒数。
|
|
选定模型的图
|
|
|
诊断图和残差图
|
|
|
您必须指定是否在结果中包括默认诊断图。也可以指定是否包含每个解释变量的残差图。
|
|
|
其他诊断图
|
|
|
预测值-RStudent 统计量
|
预测值学生化残差图。如果选择为极值点添加标签选项,则区间之外参考线之间包含学生化残差的观测值
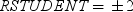 被视为是离群值。 被视为是离群值。
|
|
按观测号划分的 DFFITS 统计量
|
绘制按观测号划分的 DFFITS 统计量图。如果选择为极值点添加标签选项,则 DFFITS 统计量在量值上大于
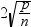 的观测被视为有影响。使用的观测号为n,回归变量数为p。 的观测被视为有影响。使用的观测号为n,回归变量数为p。
|
|
依据每个解释变量观测号的 DFBETAS 统计量
|
生成模型中依据回归变量观测号的 DFBETAS 面板。您可将这些图作为面板查看,也可作为单个图查看。如果选择为极值点添加标签选项,则 DFBETAS 统计量在量值上大于
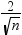 的观测值被视为对该回归变量有影响。所使用的观测数为 n。 的观测值被视为对该回归变量有影响。所使用的观测数为 n。
|
|
为极值点添加标签
|
识别每个不同类型图的极值。
|
|
散点图
|
|
|
依据预测值的观测值
|
生成观测值与预测值的散点图
|
|
每个解释变量的偏回归
|
生成每个回归变量的偏回归。如果在面板中显示这些图,那么每个面板最多显示六个回归变量。
|
|
最大图点数
|
指定包含于每个图中的最大点数。
|