Rapid Predictive Modeler
关于 Rapid Predictive Modeler
Rapid Predictive Modeler 概述
SAS Rapid Predictive Modeler 旨在帮助以下类型的数据挖掘分类和回归问题建立模型:
-
预测离散变量值的分类模型。例如,用于预测变量值(如 True 或 False、Purchase 或 Decline、High/Medium/Low,以及 Churn 或 Continues)的一些分类模型。
-
预测连续变量值的回归模型。一些回归模型示例可使用连续值来预测收益、销售额或成功率之类的数量。
要使用 SAS Rapid Predictive Modeler 建模,您必须提供一个数据集,其中每行包含一组预测自变量(即输入)和至少一个因变量(即目标)。SAS
Rapid Predictive Modeler 决定变量是连续的还是分类的,并选择应包括在模型中的输入变量。
您的模型可以保存为 SAS 代码,然后部署在 SAS 环境中。您可以使用 SAS 模型代码为新数据评分,然后用这些结果做出更明智的业务决策。这一过程称为模型评分。例如,您可以使用评分数据来决定选择流失哪些客户,或者发现可能涉嫌欺诈的交易。
SAS Rapid Predictive Modeler 的抽样策略
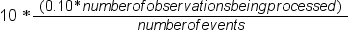
为 SAS Rapid Predictive Modeler 组织数据
在建立模型之前,需要输入能够用于预测且代表历史事件和特征的数据。您还需要能够代表想要预测的事件或值的目标数据。在很多情况下,输入数据源自一个时间期间,而目标数据源自随后的一个时间期间。用于建立模型的输入和目标数据组合称为训练数据。
例如,您可以通过挖掘上年的销售收入来预测来年的预计收入,或是预测哪些客户会响应特惠信息。利用以往事件的历史数据来预测未来事件的表现被为模型训练。
要获得最佳模型结果,您的模型训练应包含大量存储为数据行的观测。例如,许多零售客户模型使用包含数以万计观测的输入数据。
如果您的目标变量包含稀有事件(例如,可能只有 1% 的客户愿意响应的优惠信息),则必须确保您的训练数据包含数据集中足够多的此类客户。您可能想要过度抽样训练数据以确保选择了所有接受优惠的客户,同时提供相同数量的不接受优惠的客户。过度抽样使得拥有稀有事件目标的模型更容易找到稳定的解。
执行过度抽样以提高训练数据中的稀有事件发生率时,相对于自然总体,您人为地提高了训练数据中目标事件的发生率。为了弥补训练数据和总体数据之间的差异,SAS Rapid
Predictive Modeler 为您提供了先验概率设置。先验概率设置指定目标事件在总体数据中所占的真正频数比例。
使用 SAS Rapid Predictive Modeler 挖掘的数据应组织为行(观测)或列(变量)。一个列应代表一个目标变量。
姓名
包含每个观测 ID 值的列。SAS Rapid Predictive Modeler 不处理分析内容的 ID 变量列。
年龄、性别、收入和促销
SAS Rapid Predictive Modeler 所使用的输入列。
购买
目标列。
配置输入数据表时,您还可以指定频数列。频数列中的值为非负整数,总和必须为 1。
通过使用要从模型中排除的变量角色,还可以在分析过程中选择您想要 SAS Rapid Predictive Modeler 忽略的列。
训练数据始终需要输入变量值和目标变量值。用于评分的数据仅需要输入变量值;目标列是可选的。当模型根据新数据中进行预测时,目标列不是必需的。当模型用于监视有效性时,目标列是必需的。用于评分的数据通常包括一个
ID 列。
向角色分配数据
要运行 Rapid Predictive Modeler,您必须向因变量角色分配一个变量。
|
角色
|
说明
|
|---|---|
|
角色
|
|
|
因变量
|
指定您想要预测和分类的值。因变量也称为目标变量。
|
|
决策和先验
|
指定以下信息:
|
|
其他角色
|
|
|
从模型中排除的变量
|
指定您不想在分析中包括的变量。
|
|
频数计数
|
指定用于代表频数值的变量。数据被视为每个观测的重复次数等于频数变量的值。
|
|
ID 变量
|
指定对报表和评分选择函数有用的变量。这些变量不包括在分析中。
|
设置模型选项
了解 SAS Rapid Predictive Modeler 的模型
SAS Rapid Predictive Modeler 为您提供基本、中级和高级模型。模型在完善程度和复杂程度方面逐级提高。
-
基本模型是一个简单的回归分析。
-
中级模型除包括基本模型分析外,还包括一个更复杂的分析,并选择更好的模型。
-
高级模型除包括基本分析和中级分析外,还包括一个更复杂的分析,并选择最佳模型。
基本方法
基本模型执行一系列三个数据挖掘操作。
-
变量选择:基本模型选择前 100 个变量建模。
-
转换:基本模型针对选来用于建模的前 100 个变量执行最优分箱转换。最优分箱转换会补足缺失的变量值,所以不执行缺失值补缺操作。
-
建模:基本模型使用向前回归模型。向前回归模型在逐步过程中一次选择一个变量。逐步过程向线性方程一次添加一个变量,直到所添加变量的贡献不显著为止。向前回归模型试图从分析中排除没有预测能力的变量(或与其他预测变量高度相关的变量)。
中级方法
中级模型执行一系列七个数据挖掘操作。
-
变量选择:中级模型选择前 200 个变量建模。
-
转换:中级模型针对选来用于建模的 200 个变量执行最佳幂转换。最佳幂转换是 Box-Cox 转换的通用转换类的子集。最佳幂转换对指数幂转换的子集求值,然后针对指定的准则选择具有最佳结果的转换。
-
补缺:中级模型执行补缺,用平均变量值取代缺失变量。补缺操作还创建指示符变量,这些变量允许对包含补缺变量值的观测进行标识。
-
变量选择:中级模型使用卡方检验和 R 方准则检验去除与目标变量无关的变量。
-
变量选择方法组合:中级模型将通过卡方检验和 R 方准则检验选择的一组变量合并在一起。
-
建模:中级模型将训练数据提交给三个相互竞争的模型算法。模型包括决策树、logistic 回归和逐步回归。在 Logistic 回归模型中,训练数据首先提交至决策树,由决策树创建 NODE_ID 变量,该变量作为输入传递至回归模型。创建 NODE_ID 变量是为了支持变量交互模型。
-
最佳模型选择:中级模型针对竞争模型的预测或分类性能执行分析评估。将选择预测或分类性能最佳的模型来执行建模分析。用于最佳模型选择的中级模型不仅会对中级模型的性能进行评估,还会对基本模型的性能进行评估。
SAS Rapid Predictive Modeler 选择中级最佳模型后,它将其预测性能与基本模型相比较,然后选择最佳模型作为结果。
高级方法
高级模型执行一系列七个数据挖掘操作。
-
变量选择:高级模型选择前 400 个变量建模。
-
转换:高级模型对选择用于建模的 400 个变量执行多重转换算法。多重转换操作创建多个变量转换,旨在在后续变量选择中使用。多重转换将导致输入变量数增加。由于输入变量数增加,SAS Rapid Predictive Modeler 从多重转换算法所生成的输出中选择 400 个最佳输入变量。
-
补缺:高级模型执行补缺,用平均变量值取代缺失变量。补缺操作还创建指示符变量,允许用户识别包含补缺变量值的观测。
-
变量选择:高级模型使用卡方检验和 R 方准则检验去除与目标变量无关的变量。在 R 方分析期间将创建 AOV16 变量。
-
变量选择方法组合:高级模型将通过卡方检验和 R 方准则检验选择的一组变量合并在一起。
-
建模:高级模型将训练数据提交至四种竞争模型算法。它们是决策树模型、神经网络模型、向后回归模型和集成模型。神经网络模型通过执进行有限的搜索来查找最优前馈网络。向后回归模型是一种线性回归模型,它通过一次删除一个变量直至 R 方评分显著降低来剔除变量。集成模型可以合并来自多个前趋输入模型的后验概率(对于分类目标)或预测值(对于区间型目标),以此来创建新模型。新的集成模型随后用于对新数据评分。在高级模型中使用的集成模型是基于基本模型的输出、中级模型的最佳模型以及高级模型的最佳模型而创建的。
-
最佳模型选择:高级模型针对竞争的决策树、神经网络和回归模型的预测或分类性能执行分析评估。预测或分类性能最佳的模型随后将用作输入,结合基本和中级模型的最佳模型,共同创建集成模型。然后,将对新创建的高级集成模型、决策树模型、神经网络模型和向后回归模型进行分析比较,以便从所有基本、中级和高级最佳模型的样本空间中选择最佳模型。
SAS Rapid Predictive Modeler 选择最佳模型后,会运行高级模型并将其预测性能与最佳中级模型和最佳基本模型的预测性能进行比较,随后选择性能最好的最佳模型作为结果。
设置报表选项
关于报表
报告可识别模型中的重要术语并生成常用业务图形,如提升图。结果包括训练和验证数据的统计量。SAS Rapid Predictive Modeler 过程将输入数据分为训练数据和验证数据。训练数据用于计算每个模型的参数,生成训练拟合统计量。然后,对每个模型的验证数据进行评分,生成验证拟合统计量。验证拟合统计量用于比较模型和检测过度拟合。若训练统计量明显优于验证统计量,则应考虑存在过度拟合的可能性。过度拟合发生在训练模型以检测数据中的随机信号时。通常首选具有最佳验证统计量的模型。
SAS Rapid Predictive Modeler 自动生成一组简明核心报表,这些报表提供了用于建模的数据源和变量的汇总、重要预测变量的排名、估算模型精确度的多个拟合统计量,以及一个模型记分卡。
关于 SAS Rapid Predictive Modeler 的标准报表
以下是 SAS Rapid Predictive Modeler 自动生成的标准报表:
增益图
增益图仅适用于具有分类目标变量的模型。该表显示了根据预测值排名的数据百分位数。提升度衡量的是:与通过随机选择找到的目标事件数相比,模型找到的目标事件数所占的比率。
受试者操作特征图 (ROC)
受试者操作特征图 (ROC) 显示模型对整个样本(而非单一分位数)的最大预测能力。数据按“(1 - 特异度)-灵敏度”的形式绘制。模型曲线与对角线(代表随机选择模型)之间的距离称为
Kolmogorov-Smirnov (KS) 值。更高的 KS 值代表更强大的模型。
记分卡
结果包括一个记分卡,以便依据商业用途对模型特征进行解释。当软件构建记分卡时,每个区间型变量被分箱到不重复的值范围内。然后,通过模型的重要性对每个变量进行排名,最大值为
1000 点。每个变量的非重复值随后会收到占总分一定比例的分数。
项目信息
项目信息显示模型的创建用户、创建时间,以及模型组件文件的存储位置。
设置输出选项
|
选项
|
说明
|
|---|---|
|
输出数据集
|
|
|
保存 Enterprise Miner 项目数据
|
指定是否保存该任务的 SAS Enterprise Miner 数据。SAS Rapid Predictive Modeler 中的模型是一个 SAS Enterprise
Miner 项目的示例。保存 SAS Enterprise Miner 数据时,可以使用 SAS Enterprise Miner 界面打开和编辑使用 SAS Rapid
Predictive Modeler 所创建的模型。在 SAS Enterprise Miner 中,您可以保存并导出分析使其在 SAS Enterprise Miner
外部使用,并在 SAS 元数据储存库中注册您的模型。
|
|
导出评分代码
|
将该任务的评分代码保存到指定位置。然后,您可以运行此代码以便为其他 SAS 产品中的数据集评分。
|
|
为输入数据集评分
|
指定包含评分值的输出数据集名称。输入数据集中的值由 SAS Rapid Predictive Modeler 所建立的模型评分。
|