Group BY変数
Group BY変数を使用すると、1つ以上のカテゴリ変数によって定義されているデータセグメントごとにモデルの当てはめを行うことができます。すべてのGroup BY変数の階層のそれぞれの固有の組み合わせは、特定のデータセグメントです。たとえば、3つの階層をもつGroup
BY変数が1つある場合は、3つのデータセグメントがあります。しかし、2つのGroup BY変数があり、一方の変数に3つの階層があり、もう一方の変数に4つの階層がある場合は、最大で12のデータセグメントがあります。データセグメントは、分類階層の組み合わせにオブザベーションがない場合は作成されません。
SAS Visual Statisticsでは、詳細なグループ化機能を使用する場合を除き、最大数のBYグループを実行します。デフォルトでは、許容されるBYグループの最大数は1024です。空のデータセグメントは、モデルで許容されるBYグループの最大数に照らしてカウントされます。
2つ以上のGroup BY変数を指定した場合、その結果は変数がGroup Byフィールドに表示されている順番でグループ化されます。
当てはめの要約ウィンドウでは、特定のデータセグメントを選択すると、Residual PlotウィンドウとInfluence Plotウィンドウが、指定されたデータセグメントのオブザベーションのみを含むように更新されます。
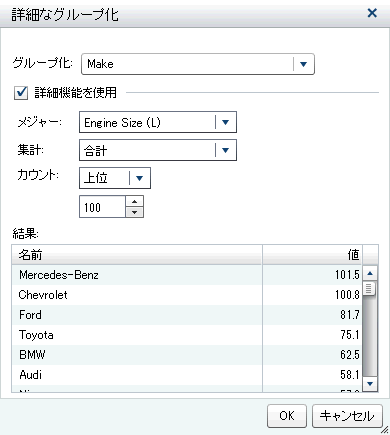
Group Byフィールドでは、グループ化に使用されている変数を選択できます。指定した尺度変数の集計統計量を表示するには、Use advanced featuresオプションを選択します。メジャーフィールドに尺度変数を指定します。Aggregationフィールドには、AverageまたはSumを計算するかを指定します。Countフィールドには、n値のTopまたはBottomが必要であるかどうかを指定します。Countの下のフィールドでは、nの値を指定できます。