Correlations Task
About the Correlations Task
Correlation is a statistical
procedure for describing the relationship between numeric variables.
The relationship is described by calculating correlation coefficients
for the variables. By default, the Correlations task calculates a
Pearson product-moment correlation. This is a parametric measure of
association for two continuous random variables. The correlations
range from –1 to 1.
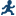

Assigning Data to Roles
To run the Correlations
task, you must assign at least two columns to the Analysis
variables role, or you must assign at least one column
to the Analysis variables role and one column
to the Correlate with role.
Setting Options



Setting the Output Options
You can specify whether
to create an output data set that contains the Pearson correlation
statistics. This data set also includes means, standard deviations,
and the number of observations. By default, this data set is saved
in the Work library.
You can also choose
to include these statistics in the output data set:
Copyright © SAS Institute Inc. All rights reserved.