Paired-sample t Test Task
About the Paired-sample t Test Task
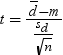
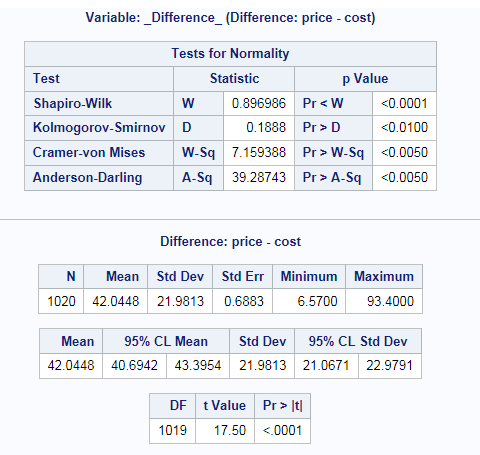
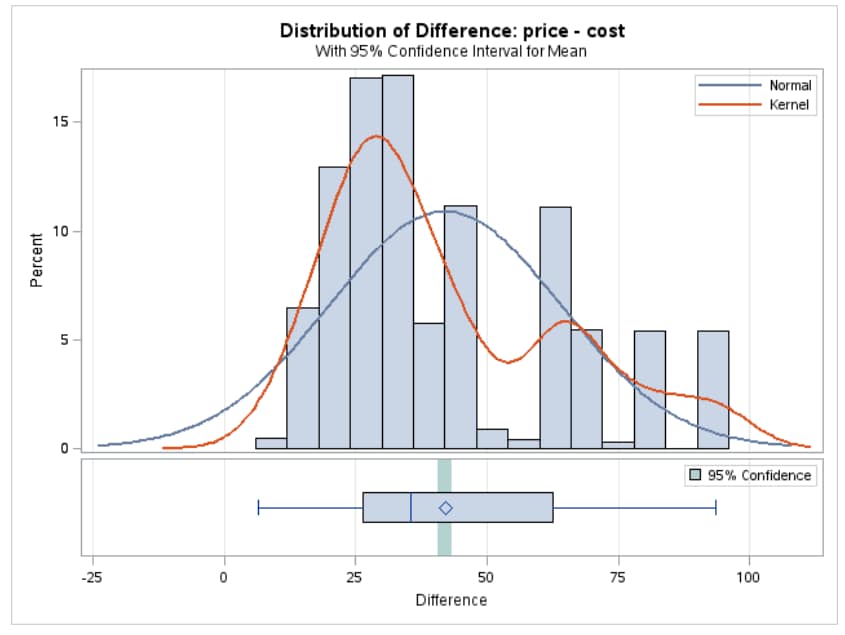
Example: Determining the Distribution of Price - Cost
Assigning Data to Roles
To run the Paired-sample
t Test, you must assign columns to the Group 1 variable and Group
2 variable roles. The task compares these two variables.
Because paired t tests are performed by subtracting
each value of the Group 2 variable from the
corresponding value of the Group 1 variable,
the designation of the variables matters.
Setting Options
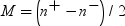
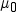
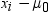
Copyright © SAS Institute Inc. All rights reserved.