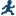|
|
|
|
|
|
|
Standardized
regression coefficients
|
displays the standardized
regression coefficients. A standardized regression coefficient is
computed by dividing a parameter estimate by the ratio of the sample
standard deviation of the dependent variable to the sample standard
deviation of the regressor.
|
Confidence
limits for estimates
|
displays the 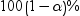 upper and lower confidence limits for the parameter
estimates.
|
|
|
Sequential
sum of squares (Type I)
|
displays the sequential
sums of squares (Type I SS) along with the parameter estimates for
each term in the model.
|
Partial
sum of squares (Type II)
|
displays the partial
sums of squares (Type II SS) along with the parameter estimates for
each term in the model.
|
Partial and Semipartial
Correlations
|
Squared
partial correlations
|
displays the squared
partial correlation coefficients computed by using Type I and Type
II sum of squares.
|
Squared
semipartial correlations
|
displays the squared
semipartial correlation coefficients computed by using Type I and
Type II sum of squares. This value is calculated as sum of squares
divided by the corrected total sum of squares.
|
|
|
|
|
requests a detailed
analysis of collinearity among the regressors. This includes eigenvalues,
condition indices, and decomposition of the variances of the estimates
with respect to each eigenvalue.
|
Tolerance
values for estimates
|
produces tolerance values
for the estimates. Tolerance for a variable is defined as 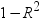 , where R square is obtained from the regression
of the variable on all other regressors in the model.
|
Variance
inflation factors
|
produces variance inflation
factors with the parameter estimates. Variance inflation is the reciprocal
of tolerance.
|
|
|
Heteroscedasticity
analysis
|
performs a test to confirmthat
the first and second moments of the model are correctly specified.
|
Asymptotic
covariance matrix
|
displays the estimated
asymptotic covariance matrix of the estimates under the hypothesis
of heteroscedasticity and heteroscedasticity-consistent standard errors
of parameter estimates.
|
|
|
|
|
calculates a Durbin-Watson
statistic and a p-value to test whether the
errors have first-order autocorrelation.
|
|
|
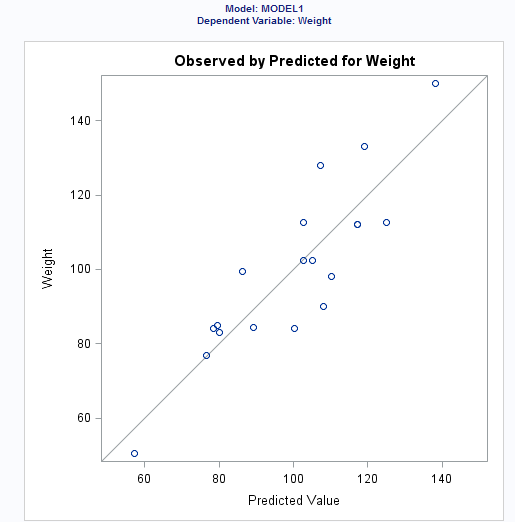
You can select the diagnostic,
residual, and scatter plots to include in the results.
By default, these plots
are included in the results:
-
plots of the fit diagnostics:
-
residuals versus the predicted
values
-
studentized residuals versus the
predicted values
-
studentized residuals versus the
leverage
-
normal quantile plot of the residuals
-
dependent variable versus the predicted
values
-
Cook’s D versus
observation number
-
-
residual-fit plot, which includes
side-by-side quantile plots of the centered fit and the residuals
-
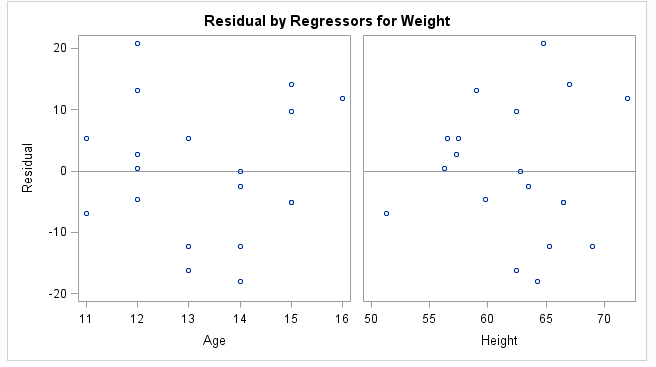
residuals plot for each explanatory
variable
-
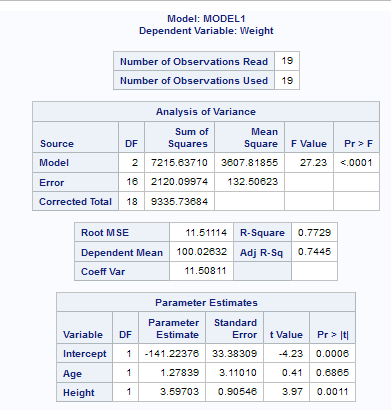
a scatter plot of the observed
values by predicted values
You can also include
these diagnostic plots:
-
Rstudent statistic
by predicted values plots studentized residuals by predicted
values. If you select the Label extreme points option,
observations with studentized residuals that lie outside the band
between the reference lines 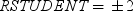 are deemed outliers.
-
DFFITS statistic by
observations plots the DFFITS statistic by observation
number. If you select the Label extreme points option,
observations with a DFFITS statistic greater in magnitude than 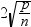 are deemed influential. The number of observations
used is n, and the number of regressors is p.
-
DFBETAS statistic by
observation number for each explanatory variable produces
panels of DFBETAS by observation number for the regressors in the
model. You can view these plots as a panel or as individual plots.
If you select the Label extreme points option,
observations with a DFBETAS statistics greater in magnitude than 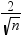 are deemed influential for that regressor. The number
of observations used is n.
You can also include
these scatter plots:
-
Fit plot for a single
explanatory variable produces a scatter plot of the data
overlaid with the regression line, confidence band, and prediction
band for models that depend on at most one regressor. The intercept
is excluded. When the number of points exceeds the value for the Maximum
number of plot points option, a heat map is displayed
instead of a scatter plot.
-
Partial regression
plots for each explanatory variable produces partial
regression plots for each regressor. If you display these plots in
a panel, there is a maximum of six regressors per panel.
|