The SURVEYFREQ Procedure

Wald Log-Linear Chi-Square Test
If you specify the WLLCHISQ option in the TABLES statement, PROC SURVEYFREQ computes a Wald test for independence based on the log odds ratios. For more information about Wald tests, see the section Wald Chi-Square Test.
For a two-way table of R rows and C columns, the Wald log-linear test is based on the (R – 1)(C – 1)-dimensional array of elements 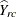 ,
,
![\[ \widehat{Y}_{rc} = \log \widehat{N}_{rc} ~ - ~ \log \widehat{N}_{rC} ~ - ~ \log \widehat{N}_{Rc} ~ + ~ \log \widehat{N}_{RC} \]](images/statug_surveyfreq0279.png)
where 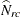 is the estimated total for table cell (r, c). The null hypothesis of independence between the row and column variables can be expressed as
is the estimated total for table cell (r, c). The null hypothesis of independence between the row and column variables can be expressed as 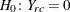 for all
for all 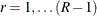 and
and 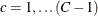 . This null hypothesis can be stated equivalently in terms of cell proportions.
. This null hypothesis can be stated equivalently in terms of cell proportions.
The generalized Wald log-linear chi-square statistic is computed as
![\[ Q_\mi {L} = \widehat{\mb{Y}}’ ~ \widehat{\mb{V}}(\widehat{\mb{Y}})^{-1} ~ \widehat{\mb{Y}} \]](images/statug_surveyfreq0281.png)
where 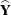 is the (R – 1)(C – 1)-dimensional array of the , and
is the (R – 1)(C – 1)-dimensional array of the , and 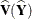 estimates the variance of ,
estimates the variance of ,
![\[ \widehat{\mb{V}}(\widehat{\mb{Y}}) = \mb{A} ~ \mb{D}^{-1} ~ \widehat{V}(\widehat{\mb{N}}) ~ \mb{D}^{-1} ~ \mb{A}’ \]](images/statug_surveyfreq0283.png)
where 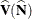 is the covariance matrix of the estimates , which is computed as described in the section Covariances of Frequency Estimates.
is the covariance matrix of the estimates , which is computed as described in the section Covariances of Frequency Estimates. 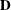 is a diagonal matrix with the estimated totals on the diagonal, and
is a diagonal matrix with the estimated totals on the diagonal, and 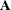 is the
is the 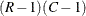 by
by 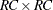 linear contrast matrix.
linear contrast matrix.
Under the null hypothesis of independence, the statistic 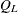 approximately follows a chi-square distribution with (R – 1)(C – 1) degrees of freedom for large samples.
approximately follows a chi-square distribution with (R – 1)(C – 1) degrees of freedom for large samples.
PROC SURVEYFREQ computes the Wald log-linear F statistic as
![\[ F_\mi {L} = Q_\mi {L} ~ / ~ (R-1)(C-1) \]](images/statug_surveyfreq0288.png)
Under the null hypothesis of independence, 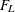 approximately follows an F distribution with (R – 1)(C – 1) numerator degrees of freedom. PROC SURVEYFREQ computes the denominator degrees of freedom as described in the section
Degrees of Freedom. Alternatively, you can use the DF=
option in the TABLES statement to specify the denominator degrees of freedom.
approximately follows an F distribution with (R – 1)(C – 1) numerator degrees of freedom. PROC SURVEYFREQ computes the denominator degrees of freedom as described in the section
Degrees of Freedom. Alternatively, you can use the DF=
option in the TABLES statement to specify the denominator degrees of freedom.
For tables larger than 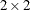 , PROC SURVEYFREQ also computes the adjusted Wald log-linear F statistic as
, PROC SURVEYFREQ also computes the adjusted Wald log-linear F statistic as
![\[ F_{\mathit{Adj\_ L}} = Q_\mi {L} ~ (s - k + 1) ~ / ~ (k s) \]](images/statug_surveyfreq0290.png)
where k = (R – 1)(C – 1), and s is the denominator degrees of freedom, which is computed as described in the section Degrees of Freedom. Alternatively, you can use the DF=
option in the TABLES statement to specify the value of s. For tables, k = (R – 1)(C – 1) = 1, and therefore the adjusted Wald F statistic equals the (unadjusted) Wald F statistic and has the same numerator and denominator degrees of freedom.
Under the null hypothesis, 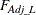 approximately follows an F distribution with k numerator degrees of freedom and (s – k + 1) denominator degrees of freedom.
approximately follows an F distribution with k numerator degrees of freedom and (s – k + 1) denominator degrees of freedom.