Regression Models and Models with Classification Effects
A linear regression model in the broad sense has the form
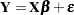 |
where 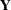 is the vector of response values,
is the vector of response values, 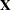 is the matrix of regressor effects,
is the matrix of regressor effects, 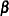 is the vector of regression parameters, and
is the vector of regression parameters, and  is the vector of errors or residuals. A regression model in the narrow sense—as compared to a classification model—is a linear model in which all regressor effects are continuous variables. In other words, each effect in the model contributes a single column to the matrix and a single parameter to the overall model. For example, a regression of subjects’ weight (
is the vector of errors or residuals. A regression model in the narrow sense—as compared to a classification model—is a linear model in which all regressor effects are continuous variables. In other words, each effect in the model contributes a single column to the matrix and a single parameter to the overall model. For example, a regression of subjects’ weight (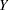 ) on the regressors age (
) on the regressors age (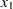 ) and body mass index (bmi,
) and body mass index (bmi, 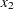 ) is a regression model in this narrow sense. In symbolic notation you can write this regression model as
) is a regression model in this narrow sense. In symbolic notation you can write this regression model as
This symbolic notation expands into the statistical model
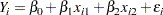 |
Single parameters are used to model the effects of age 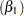 and bmi
and bmi 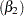 , respectively.
, respectively.
A classification effect, on the other hand, is associated with possibly more than one column of the matrix. Classification with respect to a variable is the process by which each observation is associated with one of 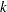 levels; the process of determining these levels is referred to as levelization of the variable. Classification variables are used in models to identify experimental conditions, group membership, treatments, and so on. The actual values of the classification variable are not important, and the variable can be a numeric or a character variable. What is important is the association of discrete values or levels of the classification variable with groups of observations. For example, in the previous illustration, if the regression also takes into account the subjects’ gender, this can be incorporated in the model with a two-level classification variable. Suppose that the values of the gender variable are coded as "F" and "M," respectively. In symbolic notation the model
levels; the process of determining these levels is referred to as levelization of the variable. Classification variables are used in models to identify experimental conditions, group membership, treatments, and so on. The actual values of the classification variable are not important, and the variable can be a numeric or a character variable. What is important is the association of discrete values or levels of the classification variable with groups of observations. For example, in the previous illustration, if the regression also takes into account the subjects’ gender, this can be incorporated in the model with a two-level classification variable. Suppose that the values of the gender variable are coded as "F" and "M," respectively. In symbolic notation the model
expands into the statistical model
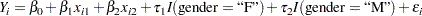 |
where 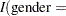 "F"
"F"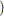 is the indicator function that returns
is the indicator function that returns  if the value of the gender variable is "F" and
if the value of the gender variable is "F" and 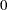 otherwise. Parameters
otherwise. Parameters 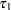 and
and 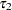 are associated with the gender classification effect. This form of parameterizing the gender effect in the model is only one of several different methods of incorporating the levels of a classification variable in the model. This form, the so-called singular parameterization, is the most general approach, and it is used in the GLM, MIXED, and GLIMMIX procedures. Alternatively, classification effects with various forms of nonsingular parameterizations are available in such procedures as GENMOD and LOGISTIC. See the documentation for the individual SAS/STAT procedures on their respective facilities for parameterizing classification variables and the section Parameterization of Model Effects in
Chapter 19,
Shared Concepts and Topics,
for general details.
are associated with the gender classification effect. This form of parameterizing the gender effect in the model is only one of several different methods of incorporating the levels of a classification variable in the model. This form, the so-called singular parameterization, is the most general approach, and it is used in the GLM, MIXED, and GLIMMIX procedures. Alternatively, classification effects with various forms of nonsingular parameterizations are available in such procedures as GENMOD and LOGISTIC. See the documentation for the individual SAS/STAT procedures on their respective facilities for parameterizing classification variables and the section Parameterization of Model Effects in
Chapter 19,
Shared Concepts and Topics,
for general details.
Models that contain only classification effects are often identified with analysis of variance (ANOVA) models, because ANOVA methods are frequently used in their analysis. This is particularly true for experimental data where the model effects comprise effects of the treatment and error-control design. However, classification effects appear more widely than in models to which analysis of variance methods are applied. For example, many mixed models, where parameters are estimated by restricted maximum likelihood, consist entirely of classification effects but do not permit the sum of squares decomposition typical for ANOVA techniques.
Many models contain both continuous and classification effects. For example, a continuous-by-class effect consists of at least one continuous variable and at least one classification variable. Such effects are convenient, for example, to vary slopes in a regression model by the levels of a classification variable. Also, recent enhancements to linear modeling syntax in some SAS/STAT procedures (including GLIMMIX and GLMSELECT) enable you to construct sets of columns in matrices from a single continuous variable. An example is modeling with splines where the values of a continuous variable x are expanded into a spline basis that occupies multiple columns in the matrix. For purposes of the analysis you can treat these columns as a single unit or as individual, unrelated columns. For more details, see the section EFFECT Statement in
Chapter 19,
Shared Concepts and Topics.