| The SEQDESIGN Procedure |
| Boundary Scales |
The boundaries computed by the SEQDESIGN procedure are applied to test statistics computed during the analysis, and so generally, the scale you select for the boundaries is determined by the scale of the statistics that you will be using.
The following scales are available in the SEQDESIGN procedure:
These scales are all equivalent for a given set of boundary values—that is, there exists a unique transformation between any two of these scales. If you know the boundary values in terms of statistics from one scale, you can uniquely derive the boundary values of statistics for other scales. You can specify the scale with the BOUNDARYSCALE= option, and the default is the standardized  scale.
scale.
You can also select the boundary scale to better examine the features of an individual group sequential design or to compare features among multiple designs. For example, with the standardized scale, the boundary values for the Pocock design are identical across all stages, and the O’Brien-Fleming design has boundary values (in absolute value) that decrease over the stages.
The remaining section demonstrates the transformations from one scale to the other scales. If the maximum likelihood estimate 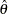 is computed by the analysis, then
is computed by the analysis, then
 |
where  is the Fisher information if it does not depend on
is the Fisher information if it does not depend on 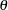 . Otherwise, is either the expected Fisher information evaluated at or the observed Fisher information. See the section Maximum Likelihood Estimator for a detailed description of these statistics.
. Otherwise, is either the expected Fisher information evaluated at or the observed Fisher information. See the section Maximum Likelihood Estimator for a detailed description of these statistics.
With the MLE statistic , the corresponding standardized statistic is computed as
 |
and the corresponding score statistic is computed as
 |
Similarly, if a score statistic  is computed by the analysis, then with
is computed by the analysis, then with
 |
where is the information, either an expected Fisher information (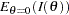 or
or 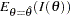 ) or an observed Fisher information (
) or an observed Fisher information (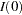 or
or 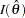 ).
).
The corresponding standardized statistic is computed as
 |
and the corresponding MLE-scaled statistic is computed as
 |
With a standardized normal statistic, the corresponding fixed-sample nominal  -value depends on the type of alternative hypothesis. With an upper alternative, the nominal -value is defined as the one-sided -value under the null hypothesis
-value depends on the type of alternative hypothesis. With an upper alternative, the nominal -value is defined as the one-sided -value under the null hypothesis 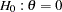 with an upper alternative:
with an upper alternative:
 |
With a lower alternative or a two-sided alternative, the nominal -value is defined as the one-sided -value under the null hypothesis with a lower alternative:
 |
which is an increasing function of the standardized statistic (Emerson, Kittelson, and Gillen 2005, p. 12).
The BOUNDARYSCALE= MLE, STDZ, SCORE, and PVALUE options display the boundary values in the MLE, standardize , score, and -value scales, respectively. For example, suppose  are
are  observations of a response variable Y in a data set from a normal distribution with an unknown mean
observations of a response variable Y in a data set from a normal distribution with an unknown mean 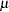 and a known variance
and a known variance 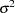 . Then
. Then
 |
for  , where
, where 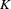 is the number of groups and is the number of observations at group
is the number of groups and is the number of observations at group 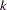 .
.
If 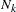 is the cumulative number of observations for the first groups, then the sample mean from these observations
is the cumulative number of observations for the first groups, then the sample mean from these observations
 |
has a normal distribution with mean and variance  :
:
 |
To test the null hypothesis 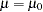 , , where
, , where 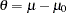 can be used. The MLE of is
can be used. The MLE of is  and
and
 |
where the information is the inverse of the variance of  ,
,
 |
The corresponding standardized statistic is
 |
The score statistic in the SEQDESIGN procedure is then given by
 |
For a null hypothesis 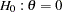 with an upper alternative, the nominal -value of the standardized statistic is
with an upper alternative, the nominal -value of the standardized statistic is  . For a null hypothesis with a lower alternative or a two-sided alternative, the nominal -value of the standardized statistic is
. For a null hypothesis with a lower alternative or a two-sided alternative, the nominal -value of the standardized statistic is  .
.
Copyright © 2009 by SAS Institute Inc., Cary, NC, USA. All rights reserved.