| The QUANTREG Procedure |
| OUTPUT Statement |
- OUTPUT <OUT=SAS-data-set> keyword=name <...keyword=name> </ COLUMNWISE> ;
The OUTPUT statement creates a SAS data set containing statistics calculated after fitting models for all specified quantiles with the QUANTILE= option in the MODEL statement. At least one specification of the form keyword=name is required.
All variables in the original data set are included in the new data set, along with the variables created as options to the OUTPUT statement. These new variables contain fitted values and estimated quantiles. If you want to create a permanent SAS data set, you must specify a two-level name (refer to SAS Language Reference: Concepts for more information about permanent SAS data sets).
If you specify multiple quantiles in the MODEL statement, the COLUMNWISE option arranges the created OUTPUT data set in column-wise form. This arrangement repeats the input data for each quantile. By default, the OUTPUT data set is created in row-wise form. For each appropriate keyword specified in the OUTPUT statement, one variable for each specified quantile is generated. These variables appear in the sorted order of the specified quantiles.
The following specifications can appear in the OUTPUT statement:
- OUT=SAS-data-set
specifies the new data set. By default, the procedure uses the DATA
 convention to name the new data set.
convention to name the new data set. - keyword=name
specifies the statistics to include in the output data set and gives names to the new variables. Specify a keyword for each desired statistic (see the following list of keywords), an equal sign, and the variable to contain the statistic. The diagnostic statistics LEVERAGE, MAHADIST, OUTLIER, and ROBDIST can be requested when only a single quantile is specified in the MODEL statement.
The keywords allowed and the statistics they represent are as follows:
- LEVERAGE
specifies a variable to indicate leverage points. To include this variable in the OUTPUT data set, you must specify the LEVERAGE option in the MODEL statement. See the section Leverage Point and Outlier Detection for how to define LEVERAGE.
- MAHADIST | MD
specifies a variable to contain the Mahalanobis distance. To include this variable in the OUTPUT data set, you must specify the LEVERAGE option in the MODEL statement.
- OUTLIER
specifies a variable to indicate outliers. See the section Leverage Point and Outlier Detection for how to define OUTLIER.
- PREDICTED | P
- QUANTILE | Q
specifies a variable to contain the quantile for which the quantile regression is fitted. If you specify the COLUMNWISE option, this variable is created by default. If multiple quantiles are specified in the MODEL statement and the COLUMNWISE option is not specified, this variable is not created.
- RESIDUAL | RES
specifies a variable to contain the residuals (unstandardized)
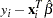
- ROBDIST | RD
specifies a variable to contain the robust MCD distance. To include this variable in the OUTPUT data set, you must specify the LEVERAGE option in the MODEL statement.
- SPLINE | SP
specifies a variable to contain the estimated spline effect, which includes all spline effects in the model and their interactions.
- SRESIDUAL | SR
specifies a variable to contain the standardized residuals

See the section Leverage Point and Outlier Detection for how to compute
 .
. - STDP
specifies a variable to contain the estimates of the standard errors of the estimated response.
Copyright © 2009 by SAS Institute Inc., Cary, NC, USA. All rights reserved.