| The MI Procedure |
| Regression Method for Monotone Missing Data |
The regression method is the default imputation method for continuous variables in a data set with a monotone missing pattern.
In the regression method, a regression model is fitted for a continuous variable with the covariates constructed from a set of effects. Based on the fitted regression model, a new regression model is simulated from the posterior predictive distribution of the parameters and is used to impute the missing values for each variable (Rubin 1987, pp. 166–167). That is, for a continuous variable 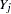 with missing values, a model
with missing values, a model
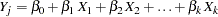 |
is fitted using observations with observed values for the variable and its covariates 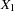 ,
, 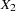 , ...,
, ..., 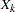 .
.
The fitted model includes the regression parameter estimates 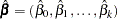 and the associated covariance matrix
and the associated covariance matrix  , where
, where 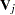 is the usual
is the usual 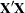 inverse matrix derived from the intercept and covariates , , ..., .
inverse matrix derived from the intercept and covariates , , ..., .
The following steps are used to generate imputed values for each imputation:
New parameters
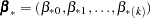 and
and 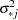 are drawn from the posterior predictive distribution of the parameters. That is, they are simulated from
are drawn from the posterior predictive distribution of the parameters. That is, they are simulated from 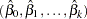 ,
, 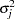 , and . The variance is drawn as
, and . The variance is drawn as 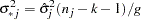
where
 is a
is a 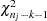 random variate and
random variate and 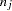 is the number of nonmissing observations for . The regression coefficients are drawn as
is the number of nonmissing observations for . The regression coefficients are drawn as 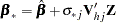
where
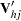 is the upper triangular matrix in the Cholesky decomposition,
is the upper triangular matrix in the Cholesky decomposition, 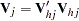 , and
, and 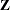 is a vector of
is a vector of 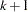 independent random normal variates.
independent random normal variates. The missing values are then replaced by
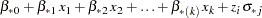
where
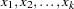 are the values of the covariates and
are the values of the covariates and  is a simulated normal deviate.
is a simulated normal deviate.
Copyright © 2009 by SAS Institute Inc., Cary, NC, USA. All rights reserved.