The HPLMIXED Procedure

If ![]() and
and ![]() are known,
are known, ![]() is the best linear unbiased estimator (BLUE) of
is the best linear unbiased estimator (BLUE) of ![]() , and
, and ![]() is the best linear unbiased predictor (BLUP) of
is the best linear unbiased predictor (BLUP) of ![]() (Searle, 1971; Harville, 1988, 1990; Robinson, 1991; McLean, Sanders, and Stroup, 1991). Here, "best" means minimum mean squared error. The covariance matrix of
(Searle, 1971; Harville, 1988, 1990; Robinson, 1991; McLean, Sanders, and Stroup, 1991). Here, "best" means minimum mean squared error. The covariance matrix of ![]() is
is
where ![]() denotes a generalized inverse (Searle 1971).
denotes a generalized inverse (Searle 1971).
However, ![]() and
and ![]() are usually unknown and are estimated by using one of the aforementioned methods. These estimates,
are usually unknown and are estimated by using one of the aforementioned methods. These estimates, ![]() and
and ![]() , are therefore simply substituted into the preceding expression to obtain
, are therefore simply substituted into the preceding expression to obtain
as the approximate variance-covariance matrix of ![]() ). In this case, the BLUE and BLUP acronyms no longer apply, but the word empirical is often added to indicate such an approximation. The appropriate acronyms thus become EBLUE and EBLUP.
). In this case, the BLUE and BLUP acronyms no longer apply, but the word empirical is often added to indicate such an approximation. The appropriate acronyms thus become EBLUE and EBLUP.
McLean and Sanders (1988) show that ![]() can also be written as
can also be written as
where
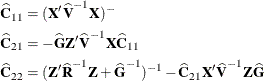
Note that ![]() is the familiar estimated generalized least squares formula for the variance-covariance matrix of
is the familiar estimated generalized least squares formula for the variance-covariance matrix of ![]() .
.