Selecting Data from More than One Table by Using Joins
Overview of Selecting Data from More than One Table by Using Joins
The data that you
need for a report could be located in more than one table. In order
to select the data from the tables, join the tables in a query. Joining
tables enables you to select data from multiple tables as if the data
were contained in one table. Joins do not alter the original tables.
The most basic type
of join is simply two tables that are listed in the FROM clause of
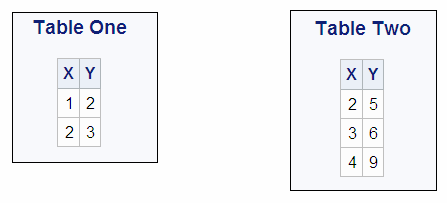
a SELECT statement. The following query joins the two tables that
are shown in Table One, Table Two and creates
Cartesian Product of Table One and Table Two.
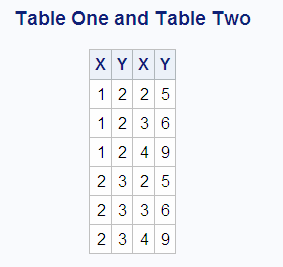
Joining
tables in this way returns the Cartesian product of the tables. Each
row from the first table is combined with every row from the second
table. When you run this query, the following message is written to
the SAS log:
Cartesian Product Log Message
NOTE: The execution of this query involves performing one or more Cartesian
product joins that can not be optimized.The Cartesian product
of large tables can be huge. Typically, you want a subset of the Cartesian
product. You specify the subset by declaring the join type.
Inner Joins
Overview of Inner Joins
An inner join returns only the subset of rows from the
first table that matches rows from the second table. You can specify
the columns that you want to be compared for matching values in a
WHERE clause.
The following code adds
a WHERE clause to the previous query. The WHERE clause specifies that
only rows whose values in column X of Table One match values in column
X of Table Two should appear in the output. Compare this query's output
to Cartesian Product of Table One and Table Two.
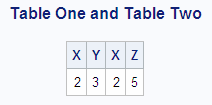
The output contains
only one row because only one value in column X matches from each
table. In an inner join, only the matching rows are selected. Outer
joins can return nonmatching rows; they are covered in
Outer Joins.
Using Table Aliases
A table
alias is a temporary, alternate name for a table. You specify table
aliases in the FROM clause. Table aliases are used in joins to qualify
column names and can make a query easier to read by abbreviating table
names.
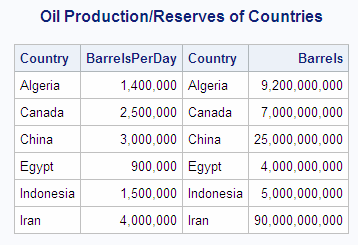
The following example
compares the oil production of countries to their oil reserves by
joining the OILPROD and OILRSRVS tables on their Country columns.
Because the Country columns are common to both tables, they are qualified
with their table aliases. You could also qualify the columns by prefixing
the column names with the table names.
Specifying the Order of Join Output
You can order the output of joined
tables by one or more columns from either table. The next example's
output is ordered in descending order by the BarrelsPerDay column.
It is not necessary to qualify BarrelsPerDay, because the column exists
only in the OILPROD table.
Creating Inner Joins Using INNER JOIN Keywords
The INNER JOIN keywords
can be used to join tables. The ON clause replaces the WHERE clause
for specifying columns to join. PROC SQL provides these keywords primarily
for compatibility with the other joins (OUTER, RIGHT, and LEFT JOIN).
Using INNER JOIN with an ON clause provides the same functionality
as listing tables in the FROM clause and specifying join columns with
a WHERE clause.
Joining Tables Using Comparison Operators
Tables can be joined by using
comparison operators other than the equal sign (
=) in the WHERE clause. For more information about comparison operators,
see Retrieving Rows Based on a Comparison. In this example, all U.S. cities in the USCITYCOORDS table
are selected that are south of Cairo, Egypt. The compound WHERE clause
specifies the city of Cairo in the WORLDCITYCOORDS table and joins
USCITYCOORDS and WORLDCITYCOORDS on their Latitude columns, using
a less-than (lt) operator.
libname sql 'SAS-library';
proc sql;
title 'US Cities South of Cairo, Egypt';
select us.City, us.State, us.Latitude, world.city, world.latitude
from sql.worldcitycoords world, sql.uscitycoords us
where world.city = 'Cairo' and
us.latitude lt world.latitude;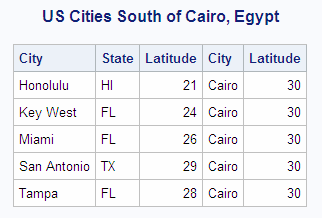
The Effects of Null Values on Joins
Most database products treat nulls as
distinct entities and do not match them in joins. PROC SQL treats
nulls as missing values and as matches for joins. Any null will match
with any other null of the same type (character or numeric) in a join.
The following example
joins Table One and Table Two on column B. There are null values in
column B of both tables. Notice in the output that the null value
in row c of Table One matches all the null values in Table Two. This
is probably not the intended result for the join.
proc sql;
title 'One and Two Joined';
select one.a 'One', one.b, two.a 'Two', two.b
from one, two
where one.b=two.b;

Creating Multicolumn Joins
When a row is distinguished by a combination
of values in more than one column, use all the necessary columns in
the join. For example, a city name could exist in more than one country.
To select the correct city, you must specify both the city and country
columns in the joining query's WHERE clause.
This example displays
the latitude and longitude of capital cities by joining the COUNTRIES
table with the WORLDCITYCOORDS table. To minimize the number of rows
in the example output, the first part of the WHERE expression selects
capitals with names that begin with the letter
L from the COUNTRIES table.
libname sql 'SAS-library';
proc sql;
title 'Coordinates of Capital Cities';
select Capital format=$12., Name format=$12.,
City format=$12., Country format=$12.,
Latitude, Longitude
from sql.countries, sql.worldcitycoords
where Capital like 'L%' and
Capital = City;London occurs once as
a capital city in the COUNTRIES table. However, in WORLDCITYCOORDS,
London is found twice: as a city in England and again as a city in
Canada. Specifying only
Capital = City in
the WHERE expression yields the following incorrect output:
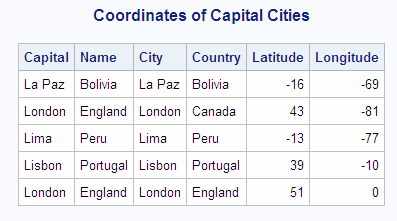
Notice in the output
that the inner join incorrectly matches London, England, to both London,
Canada, and London, England. By also joining the country name columns
together (COUNTRIES.Name to WORLDCITYCOORDS.Country), the rows match
correctly.
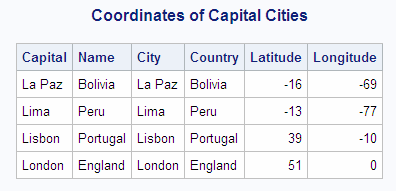
Selecting Data from More than Two Tables
The data that you need
could be located in more than two tables. For example, if you want
to show the coordinates of the capitals of the states in the United
States, then you need to join the UNITEDSTATES table, which contains
the state capitals, with the USCITYCOORDS table, which contains the
coordinates of cities in the United States. Because cities must be
joined along with their states for an accurate join (similarly to
the previous example), you must join the tables on both the city and
state columns of the tables.
Joining the cities,
by joining the UNITEDSTATES.Capital column to the USCITYCOORDS.City
column, is straightforward. However, in the UNITEDSTATES table the
Name column contains the full state name, while in USCITYCOORDS the
states are specified by their postal code. It is therefore impossible
to directly join the two tables on their state columns. To solve this
problem, it is necessary to use the POSTALCODES table, which contains
both the state names and their postal codes, as an intermediate table
to make the correct relationship between UNITEDSTATES and USCITYCOORDS.
The correct solution joins the UNITEDSTATES.Name column to the POSTALCODES.Name
column (matching the full state names), and the POSTALCODES.Code column
to the USCITYCOORDS.State column (matching the state postal codes).
libname sql 'SAS-library';
title 'Coordinates of State Capitals';
proc sql outobs=10;
select us.Capital format=$15., us.Name 'State' format=$15.,
pc.Code, c.Latitude, c.Longitude
from sql.unitedstates us, sql.postalcodes pc,
sql.uscitycoords c
where us.Capital = c.City and
us.Name = pc.Name and
pc.Code = c.State;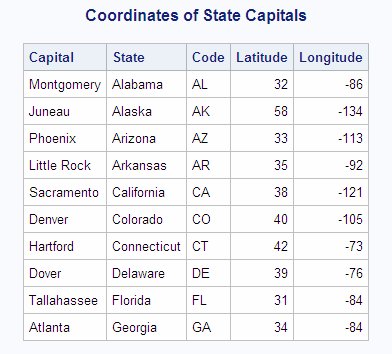
Showing Relationships within a Single Table Using Self-Joins
When you need
to show comparative relationships between values in a table, it is
sometimes necessary to join columns within the same table. Joining
a table to itself is called a self-join, or reflexive join. You can
think of a self-join as PROC SQL making an internal copy of a table
and joining the table to its copy.
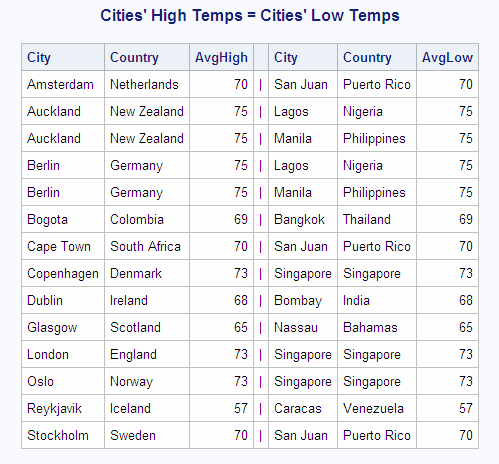
For example, the following
code uses a self-join to select cities that have average yearly high
temperatures equal to the average yearly low temperatures of other
cities.
libname sql 'SAS-library';
proc sql;
title "Cities' High Temps = Cities' Low Temps";
select High.City format $12., High.Country format $12.,
High.AvgHigh, ' | ',
Low.City format $12., Low.Country format $12.,
Low.AvgLow
from sql.worldtemps High, sql.worldtemps Low
where High.AvgHigh = Low.AvgLow and
High.city ne Low.city and
High.country ne Low.country;Notice that the WORLDTEMPS
table is assigned two aliases,
High and Low. Conceptually, this makes a copy of the table so
that a join can be made between the table and its copy. The WHERE
clause selects those rows that have high temperature equal to low
temperature.
Outer Joins
Overview of Outer Joins
Outer joins are inner joins that are augmented with
rows from one table that do not match any row from the other table
in the join. The resulting output includes rows that match and rows
that do not match from the join's source tables. Nonmatching rows
have null values in the columns from the unmatched table. Use the
ON clause instead of the WHERE clause to specify the column or columns
on which you are joining the tables. However, you can continue to
use the WHERE clause to subset the query result.
Including Nonmatching Rows with the Left Outer Join
A left
outer join lists matching rows and rows from the left-hand table (the
first table listed in the FROM clause) that do not match any row in
the right-hand table. A left join is specified with the keywords LEFT
JOIN and ON.
For example, to list
the coordinates of the capitals of international cities, join the
COUNTRIES table, which contains capitals, with the WORLDCITYCOORDS
table, which contains cities' coordinates, by using a left join. The
left join lists all capitals, regardless of whether the cities exist
in WORLDCITYCOORDS. Using an inner join would list only capital cities
for which there is a matching city in WORLDCITYCOORDS.
Including Nonmatching Rows with the Right Outer Join
A right join, specified with the keywords RIGHT JOIN
and ON, is the opposite of a left join: nonmatching rows from the
right-hand table (the second table listed in the FROM clause) are
included with all matching rows in the output. This example reverses
the join of the last example; it uses a right join to select all the
cities from the WORLDCITYCOORDS table and displays the population
only if the city is the capital of a country (that is, if the city
exists in the COUNTRIES table).
Selecting All Rows with the Full Outer Join
A full outer join, specified with the
keywords FULL JOIN and ON, selects all matching and nonmatching rows.
This example displays the first ten matching and nonmatching rows
from the City and Capital columns of WORLDCITYCOORDS and COUNTRIES.
Note that the pound sign (
#) is used as a
line split character in the labels.
libname sql 'SAS-library';
proc sql outobs=10;
title 'Populations and/or Coordinates of World Cities';
select City '#City#(WORLDCITYCOORDS)' format=$20.,
Capital '#Capital#(COUNTRIES)' format=$20.,
Population, Latitude, Longitude
from sql.countries full join sql.worldcitycoords
on Capital = City and
Name = Country; 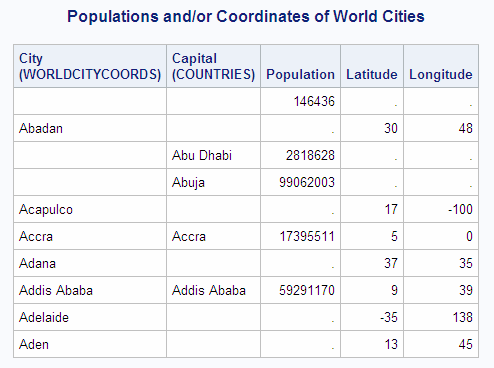
Specialty Joins
Including All Combinations of Rows with the Cross Join
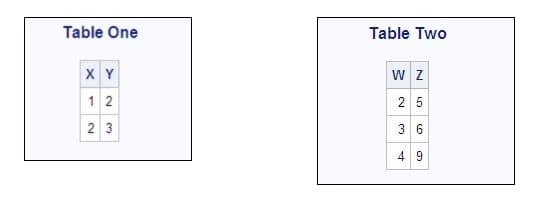
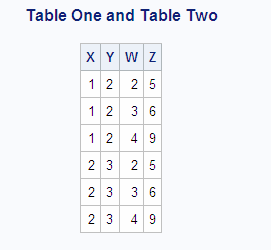
Including All Rows with the Union Join
A union join
combines two tables without attempting to match rows. All columns
and rows from both tables are included. Combining tables with a union
join is similar to combining them with the OUTER UNION set operator
(see Combining Queries with Set Operators). A union join's output can be limited by a WHERE clause.
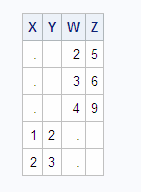
Matching Rows with a Natural Join
A natural
join automatically selects columns from each table to use in determining
matching rows. With a natural join, PROC SQL identifies columns in
each table that have the same name and type; rows in which the values
of these columns are equal are returned as matching rows. The ON clause
is implied.
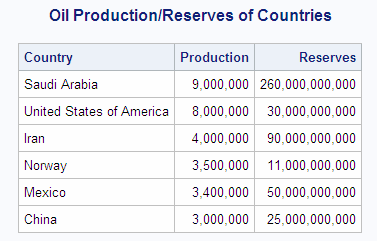
This example produces
the same results as the example in
Specifying the Order of Join Output:
libname sql 'SAS-library';
proc sql outobs=6;
title 'Oil Production/Reserves of Countries';
select country, barrelsperday 'Production', barrels 'Reserve'
from sql.oilprod natural join sql.oilrsrvs
order by barrelsperday desc;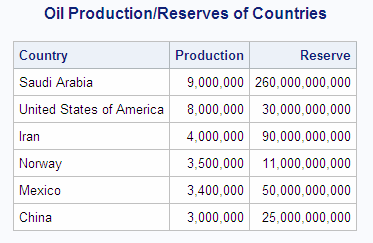
The advantage of using
a natural join is that the coding is streamlined. The ON clause is
implied, and you do not need to use table aliases to qualify column
names that are common to both tables. These two queries return the
same results:
proc sql; select a.W, a.X, Y, Z from table1 a left join table2 b on a.W=b.W and a.X=b.X order by a.W;
proc sql; select W, X, Y, Z from table1 natural left join table2 order by W;
If you specify a natural
join on tables that do not have at least one column with a common
name and type, then the result is a Cartesian product. You can use
a WHERE clause to limit the output.
Because the natural
join makes certain assumptions about what you want to accomplish,
you should know your data thoroughly before using it. You could get
unexpected or incorrect results. For example, if you are expecting
two tables to have only one column in common when they actually have
two. You can use the FEEDBACK option to see exactly how PROC SQL is
implementing your query. See
Using PROC SQL Options to Create and Debug Queries for more information about the FEEDBACK option.
Using the Coalesce Function in Joins
As you can see from the previous examples, the nonmatching rows
in outer joins contain missing values. By using the COALESCE function,
you can overlay columns so that only the row from the table that contains
data is listed. Recall that COALESCE takes a list of columns as its
arguments and returns the first nonmissing value that it encounters.
This example adds the
COALESCE function to the previous example to overlay the COUNTRIES.Capital,
WORLDCITYCOORDS.City, and COUNTRIES.Name columns. COUNTRIES.Name is
supplied as an argument to COALESCE because some islands do not have
capitals.
libname sql 'SAS-library';
proc sql outobs=10;
title 'Populations and/or Coordinates of World Cities';
select coalesce(Capital, City,Name)format=$20. 'City',
coalesce(Name, Country) format=$20. 'Country',
Population, Latitude, Longitude
from sql.countries full join sql.worldcitycoords
on Capital = City and
Name = Country; 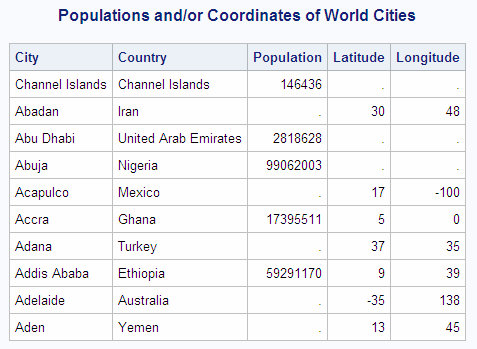
COALESCE can be used
in both inner and outer joins. For more information about COALESCE,
see Replacing Missing Values.
Comparing DATA Step Match-Merges with PROC SQL Joins
Overview of Comparing DATA Step Match-Merges with PROC SQL Joins
Many SAS users are
familiar with using a DATA step to merge data sets. This section compares
merges to joins. DATA step match-merges and PROC SQL joins can produce
the same results. However, a significant difference between a match-merge
and a join is that you do not have to sort the tables before you join
them.
When All of the Values Match
When all of the values match
in the BY variable and there are no duplicate BY variables, you can
use an inner join to produce the same result as a match-merge. To
demonstrate this result, here are two tables that have the column
Flight in common. The values of Flight are the same in both tables:
FLTSUPER FLTDEST Flight Supervisor Flight Destination 145 Kang 145 Brussels 150 Miller 150 Paris 155 Evanko 155 Honolulu
FLTSUPER and FLTDEST
are already sorted by the matching column Flight. A DATA step merge
produces
Merged Tables When All the Values Match.
data fltsuper; input Flight Supervisor $; datalines; 145 Kang 150 Miller 155 Evanko ; data fltdest; input Flight Destination $; datalines; 145 Brussels 150 Paris 155 Honolulu ; run;
data merged; merge FltSuper FltDest; by Flight; run; proc print data=merged noobs; title 'Table MERGED'; run;
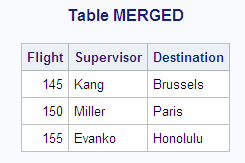
With PROC SQL, presorting
the data is not necessary. The following PROC SQL join gives the same
result as that shown in
Merged Tables When All the Values Match.
When Only Some of the Values Match
When only some of the values
match in the BY variable, you can use an outer join to produce the
same result as a match-merge. To demonstrate this result, here are
two tables that have the column Flight in common. The values of Flight
are not the same in both tables:
FLTSUPER FLTDEST Flight Supervisor Flight Destination 145 Kang 145 Brussels 150 Miller 150 Paris 155 Evanko 165 Seattle 157 Lei
A DATA step merge produces
Merged Tables When Some of the Values Match:
data merged; merge fltsuper fltdest; by flight; run; proc print data=merged noobs; title 'Table MERGED'; run;
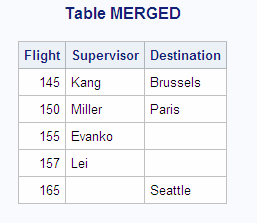
To get the same result
with PROC SQL, use an outer join so that the query result will contain
the nonmatching rows from the two tables. In addition, use the COALESCE
function to overlay the Flight columns from both tables. The following
PROC SQL join gives the same result as that shown in
Merged Tables When Some of the Values Match:
proc sql;
select coalesce(s.Flight,d.Flight) as Flight, Supervisor, Destination
from fltsuper s full join fltdest d
on s.Flight=d.Flight;When the Position of the Values Is Important
When you
want to merge two tables and the position of the values is important,
you might need to use a DATA step merge. To demonstrate this idea,
here are two tables to consider:
FLTSUPER FLTDEST Flight Supervisor Flight Destination 145 Kang 145 Brussels 145 Ramirez 145 Edmonton 150 Miller 150 Paris 150 Picard 150 Madrid 155 Evanko 165 Seattle 157 Lei
For Flight 145,
Kang matches with Brussels and Ramirez matches with Edmonton. Because the DATA step merges data based
on the position of values in BY groups, the values of Supervisor and
Destination match appropriately. A DATA step merge produces
Match-Merge of the FLTSUPER and FLTDEST Tables: data merged; merge fltsuper fltdest; by flight; run; proc print data=merged noobs; title 'Table MERGED'; run;
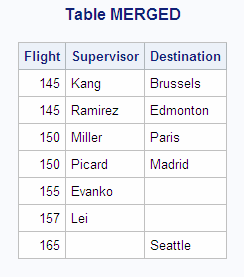
PROC SQL does not process
joins according to the position of values in BY groups. Instead, PROC
SQL processes data only according to the data values. Here is the
result of an inner join for FLTSUPER and FLTDEST:
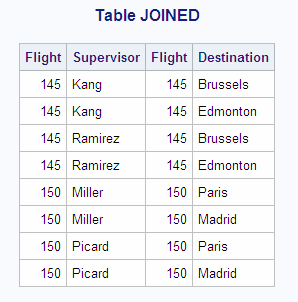
PROC SQL builds the
Cartesian product and then lists the rows that meet the WHERE clause
condition. The WHERE clause returns two rows for each supervisor,
one row for each destination. Because Flight has duplicate values
and there is no other matching column, there is no way to associate
Kang only with Brussels, Ramirez only with Edmonton, and so on.
For more information
about DATA step match-merges, see SAS Statements: Reference.
Copyright © SAS Institute Inc. All rights reserved.