The SHEWHART Procedure
Determining the Components of Variation
The standard Shewhart analysis assumes that sampling variation, also referred to as within-group variation, is the only source of variation. Writing 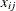 for the jth measurement within the ith subgroup, you can express the model for the conventional
for the jth measurement within the ith subgroup, you can express the model for the conventional 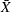 and R chart as
and R chart as
![\[ \begin{array}{rclp{3in}r} x_{ij} & = & \mu + \sigma _{W} \epsilon _{ij} & & (1) \end{array} \]](images/qcug_shewhart0390.png)
for  and
and  . The random variables
. The random variables 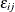 are assumed to be independent with zero mean and unit variance, and
are assumed to be independent with zero mean and unit variance, and  is the within-subgroup variance. The parameter
is the within-subgroup variance. The parameter 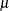 denotes the process mean.
denotes the process mean.
In a process such as film manufacturing, this model is not adequate because there is additional variation due to changes in temperature, pressure, raw material, and other factors. A more appropriate model is
![\[ \begin{array}{rclp{2.5in}r} x_{ij} & = & \mu + \sigma _{B} \omega _{i} + \sigma _{W} \epsilon _{ij} & & (2) \end{array} \]](images/qcug_shewhart0394.png)
where  is the between-subgroup variance, the random variables
is the between-subgroup variance, the random variables 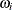 are independent with zero mean and unit variance, and the random variables are independent of the random variables .[51]
are independent with zero mean and unit variance, and the random variables are independent of the random variables .[51]
To plot the subgroup averages  on a control chart, you need expressions for the expectation and variance of
on a control chart, you need expressions for the expectation and variance of  . These are
. These are
![\[ \begin{array}{rcl} E (\bar{x}_{i.} ) & = & \mu \\ \mbox{Var} (\bar{x}_{i.} ) & = & \sigma ^{2}_{B} + \frac{\sigma ^{2}_{W}}{n} \end{array} \]](images/qcug_shewhart0398.png)
Thus, the central line should be located at  , and
, and 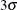 limits should be located at
limits should be located at
![\[ \begin{array}{rp{3.1in}r} \hat{\mu } \pm 3 \sqrt { \widehat{\sigma ^{2}_{B}} + \frac{\widehat{\sigma ^{2}_{W}}}{n} } & & (3) \end{array} \]](images/qcug_shewhart0400.png)
where  and
and  denote estimates of the variance components. You can use a variety of SAS procedures for fitting linear models to estimate
the variance components. The following statements show how this can be done with the MIXED procedure:
denote estimates of the variance components. You can use a variety of SAS procedures for fitting linear models to estimate
the variance components. The following statements show how this can be done with the MIXED procedure:
title; proc mixed data=Film2; class Sample; model Testval = / s; random Sample; ods output solutionf=sf; ods output covparms=cp; run;
The results are shown in Figure 18.203. Note that the parameter estimates are  ,
,  , and
, and  .
.
Figure 18.203: Partial Output from the MIXED Procedure
The following statements merge the output data sets from the MIXED procedure into a SAS data set named Newlim that contains the appropriately derived control limit parameters for average test value:
data cp; set cp sf; keep Estimate; run; proc transpose data=cp out=Newlim; run; data Newlim (keep=_lclx_ _mean_ _uclx_); set Newlim; _limitn_ = 4; _mean_ = col3; _stddev_ = sqrt(4*col1 + col2); _lclx_ = _mean_ - 3*_stddev_ / sqrt(_limitn_); _uclx_ = _mean_ + 3*_stddev_ / sqrt(_limitn_); output; run;
Here, the variable _LIMITN_ is assigned the value of n, the variable _MEAN_ is assigned the value of , and the variable _STDDEV_ is assigned the value of
![\[ \hat{\sigma }\! _{\scriptstyle \text {adj}} \equiv \sqrt { 4 \widehat{\sigma ^{2}_{B}} + \widehat{\sigma ^{2}_{W}} } \]](images/qcug_shewhart0406.png)
The limits (_LCLX_ and _UCLX_) are computed according to (3) using  . The data set
. The data set Newlim contains the mean and limits for the average test value.
The following statements compute appropriate control limits for the and R charts, which are shown in Figure 18.204. First, the data set Newlim2 is created by merging the data set RLimits, which contains the original R chart limits computed in Preliminary Examination of Variation, with Newlim, which saved the appropriate chart limits. The original R chart limits are valid because the range in the ith subgroup is  , which is the same for models (1) and (2). The LIMITS= option specifies the data set
, which is the same for models (1) and (2). The LIMITS= option specifies the data set Newlim2 as the source of the control limits for Figure 18.204.
data Newlim2; merge Newlim RLimits (drop=_lclx_ _mean_ _uclx_); run; title 'Control Chart with Adjusted Limits'; symbol h = 2.0 pct; proc shewhart data=Film2 limits=Newlim2; xrchart Testval*Sample / npanelpos = 60; label Testval='Average Test Value'; run;
The control limits for the chart in Figure 18.204 are  . This chart correctly indicates that the variation in the process is due to common causes.
. This chart correctly indicates that the variation in the process is due to common causes.
Figure 18.204: and R Chart with Derived Control Limits

You can use a similar set of statements to display the derived control limits in Newlim on an and R chart for the original data (including outliers), as shown in Figure 18.205.
Figure 18.205: and R Chart with Derived Control Limits for Raw Data

A simple alternative to the chart in Figure 18.204 is an "individual measurements" chart for the subgroup means. The advantage of the variance components approach is that it yields separate estimates of the components due to lane and sample, as well as a number of hypothesis tests (these require assumptions of normality). In applying this method, however, you should be careful to use data that represent the process in a state of statistical control.