Combining SAS Data Sets: Methods
Concatenating
Definition
Concatenating data sets
is the combining of two or more data sets, one after the other, into
a single data set. The number of observations in the new data set
is the sum of the number of observations in the original data sets.
The order of observations is sequential. All observations from the
first data set are followed by all observations from the second data
set, and so on.
In the simplest case,
all input data sets contain the same variables. If the input data
sets contain different variables, observations from one data set have
missing values for variables defined only in other data sets. In
either case, the variables in the new data set are the same as the
variables in the old data sets.
Syntax
SET data-set(s);
For a complete description
of valid SAS data set names, see the SET statement in SAS Statements: Reference.
DATA Step Processing during Concatenation
SAS reads the descriptor
information of each data set that is named in the SET statement and
then creates a program data vector that contains all the variables
from all data sets as well as variables created by the DATA step.
SAS reads the first
observation from the first data set into the program data vector.
It processes the first observation and executes other statements in
the DATA step. It then writes the contents of the program data vector
to the new data set.
The SET statement does
not reset the values in the program data vector to missing, except
for variables whose value is calculated or assigned during the DATA
step. Variables that are created by the DATA step are set to missing
at the beginning of each iteration of the DATA step. Variables that
are read from a data set are not.
SAS continues to read
one observation at a time from the first data set until it finds an
end-of-file indicator. The values of the variables in the program
data vector are then set to missing, and SAS begins reading observations
from the second data set, and so on, until it reads all observations
from all data sets.
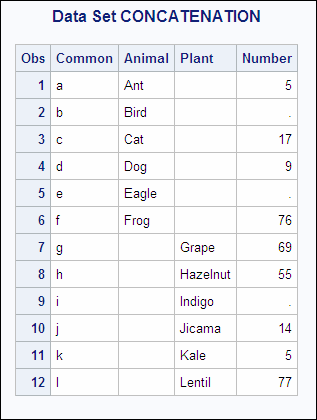
Example 1: Concatenation Using the DATA Step
In this example, each data set contains the variables
Common and Number, and the observations are arranged in the order
of the values of Common. Generally, you concatenate SAS data sets
that have the same variables. In this case, each data set also contains
a unique variable to show the effects of combining data sets more
clearly. The following shows the ANIMAL and the PLANT input data
sets in the library that is referenced by the libref EXAMPLE:
ANIMAL PLANT OBS Common Animal Number OBS Common Plant Number 1 a Ant 5 1 g Grape 69 2 b Bird 2 h Hazelnut 55 3 c Cat 17 3 i Indigo . 4 d Dog 9 4 j Jicama 14 5 e Eagle 5 k Kale 5 6 f Frog 76 6 l Lentil 77
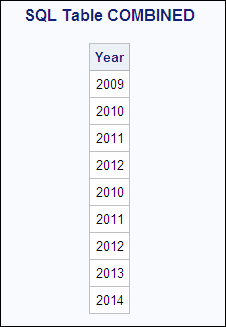
Example 2: Concatenation Using SQL
You can also use the SQL language to concatenate tables. In this example,
SQL reads each row in both tables and creates a new table named COMBINED.
The following shows the YEAR1 and YEAR2 input tables:
Appending Files
Instead of concatenating
data sets or tables, you can append them and produce the same results
as concatenation. SAS concatenates data sets (DATA step) and tables
(SQL) by reading each row of data to create a new file. To avoid reading
all the records, you can append the second file to the first file
by using the APPEND procedure:
proc append base=year1 data=year2; run;
Interleaving
Definition
Interleaving uses a
SET statement and a BY statement to combine multiple data sets into
one new data set. The number of observations in the new data set is
the sum of the number of observations from the original data sets.
However, the observations in the new data set are arranged by the
values of the BY variable or variables and, within each BY group,
by the order of the data sets in which they occur. You can interleave
data sets either by using a BY variable or by using an index.
Syntax
SET data-set(s);
BY variable(s);
SET data-set-1 . . . data-set-n KEY= index;
For a complete description
of the SET statement, including SET with the KEY= option, see the
SET statement in SAS Statements: Reference.
DATA Step Processing during Interleaving
SAS compares the first
observation from each data set that is named in the SET statement
to determine which BY group should appear first in the new data set.
It reads all observations from the first BY group from the selected
data set. If this BY group appears in more than one data set, it
reads from the data sets in the order in which they appear in the
SET statement. The values of the variables in the program data vector
are set to missing each time SAS starts to read a new data set and
when the BY group changes.
Example 1: Interleaving in the Simplest Case
In this example, each data
set contains the BY variable Common, and the observations are arranged
in order of the values of the BY variable. The following shows the
ANIMAL and the PLANT input data sets in the library that is referenced
by the libref EXAMPLE:
ANIMAL PLANT
OBS Common Animal OBS Common Plant
1 a Ant 1 a Apple
2 b Bird 2 b Banana
3 c Cat 3 c Coconut
4 d Dog 4 d Dewberry
5 e Eagle 5 e Eggplant
6 f Frog 6 f FigThe following program
uses SET and BY statements to interleave the data sets, and prints
the results:
data interleaving; set animal plant; by Common; run; proc print data=interleaving; title 'Data Set INTERLEAVING'; run;
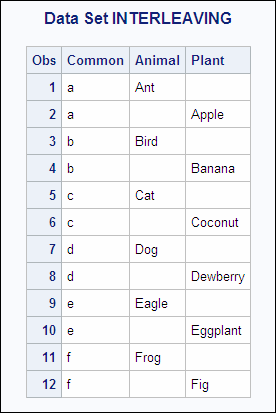
The resulting data set
INTERLEAVING has 12 observations, which is the sum of the observations
from the combined data sets. The new data set contains all variables
from both data sets. The value of variables found in one data set
but not in the other are set to missing, and the observations are
arranged by the values of the BY variable.
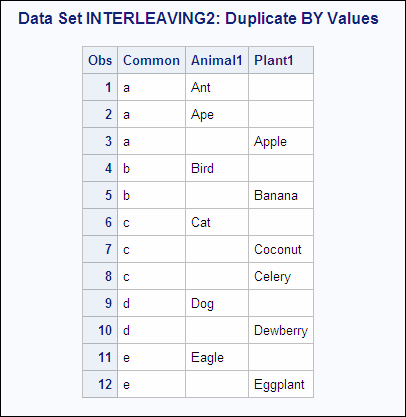
Example 2: Interleaving with Duplicate Values of the BY Variable
If the data sets contain duplicate values of the BY
variables, the observations are written to the new data set in the
order in which they occur in the original data sets. This example
contains duplicate values of the BY variable Common. The following
shows the ANIMAL1 and PLANT1 input data sets:
ANIMAL1 PLANT1 OBS Common Animal1 OBS Common Plant1 1 a Ant 1 a Apple 2 a Ape 2 b Banana 3 b Bird 3 c Coconut 4 c Cat 4 c Celery 5 d Dog 5 d Dewberry 6 e Eagle 6 e Eggplant
The following program
uses SET and BY statements to interleave the data sets, and prints
the results:
Example 3: Interleaving with Different BY Values in Each Data Set
The data sets ANIMAL2 and
PLANT2 both contain values that are present in one data set but not
in the other. The following shows the ANIMAL2 and the PLANT2 input
data sets:
ANIMAL2 PLANT2
OBS Common Animal2 OBS Common Plant2
1 a Ant 1 a Apple
2 c Cat 2 b Banana
3 d Dog 3 c Coconut
4 e Eagle 4 e Eggplant
5 f Fig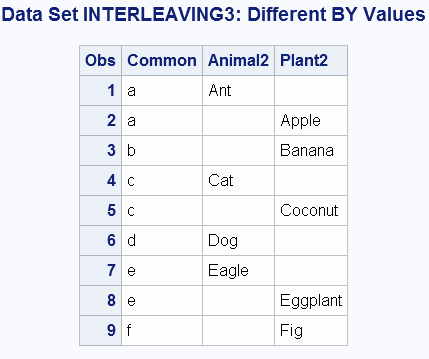
Comments and Comparisons
-
In other languages, the term merge is often used to mean interleave. SAS reserves the term merge for the operation in which observations from two or more data sets are combined into one observation. The observations in interleaved data sets are not combined; they are copied from the original data sets in the order of the values of the BY variable.
One-to-One Reading
Definition
One-to-one reading combines
observations from two or more data sets into one observation by using
two or more SET statements to read observations independently from
each data set. This process is also called one-to-one matching. The
new data set contains all the variables from all the input data sets.
The number of observations in the new data set is the number of observations
in the smallest original data set. If the data sets contain common
variables, the values that are read in from the last data set replace
the values that were read in from earlier data sets.
Syntax
SET data-set-1;
SET data-set-2;
where
For a complete description,
see SET Statement in SAS Statements: Reference.
DATA Step Processing during a One-to-One Reading
SAS reads the descriptor
information of each data set named in the SET statement and then creates
a program data vector that contains all the variables from all data
sets as well as variables created by the DATA step.
When SAS executes the
first SET statement, SAS reads the first observation from the first
data set into the program data vector. The second SET statement reads
the first observation from the second data set into the program data
vector. If both data sets contain the same variables, the values from
the second data set replace the values from the first data set, even
if the value is missing. After reading the first observation from
the last data set and executing any other statements in the DATA step,
SAS writes the contents of the program data vector to the new data
set. The SET statement does not reset the values in the program data
vector to missing, except for those variables that were created or
assigned values during the DATA step.
Example 1: One-to-One Reading: Processing an Equal Number of Observations
The SAS data sets
ANIMAL and PLANT both contain the variable Common, and are arranged
by the values of that variable. The following shows the ANIMAL and
the PLANT input data sets:
ANIMAL PLANT OBS Common Animal OBS Common Plant 1 a Ant 1 a Apple 2 b Bird 2 b Banana 3 c Cat 3 c Coconut 4 d Dog 4 d Dewberry 5 e Eagle 5 e Eggplant 6 f Frog 6 g Fig
The following program
uses two SET statements to combine observations from ANIMAL and PLANT,
and prints the results:
data twosets; set animal; set plant; run; proc print data=twosets; title 'Data Set TWOSETS - Equal Number of Observations'; run;
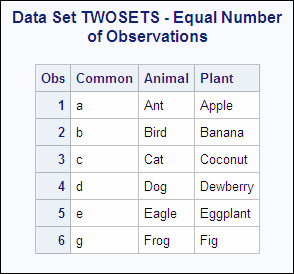
Each observation in
the new data set contains all the variables from all the data sets.
Note, however, that the Common variable value in observation 6 contains
a “g.” The value of Common in observation 6 of the ANIMAL
data set was overwritten by the value in PLANT, which was the data
set that SAS read last.
Comments and Comparisons
-
The results that are obtained by reading observations using two or more SET statements are similar to those that are obtained by using the MERGE statement with no BY statement. However, with one-to-one reading, SAS stops processing before all observations are read from all data sets if the number of observations in the data sets is not equal.
One-to-One Merging
Definition
One-to-one merging combines
observations from two or more SAS data sets into a single observation
in a new data set. To perform a one-to-one merge, use the MERGE statement
without a BY statement. SAS combines the first observation from all
data sets in the MERGE statement into the first observation in the
new data set, the second observation from all data sets into the second
observation in the new data set, and so on. In a one-to-one merge,
the number of observations in the new data set equals the number of
observations in the largest data set that was named in the MERGE statement.
Syntax
MERGE data-set(s);
CAUTION:
Avoid using
duplicate values or different values of common variables.
One-to-one merging
with data sets that contain duplicate values of common variables can
produce undesirable results. If a variable exists in more than one
data set, the value from the last data set that is read is the one
that is written to the new data set. The variables are combined exactly
as they are read from each data set. Using a one-to-one merge to combine
data sets with different values of common variables can also produce
undesirable results. If a variable exists in more than one data set,
the value from the last data set read is the one that is written to
the new data set even if the value is missing. Once SAS has processed
all observations in a data set, all subsequent observations in the
new data set have missing values for the variables that are unique
to that data set.
For a complete description
of the MERGE statement, see the MERGE statement in SAS Statements: Reference.
DATA Step Processing during One-to-One Merging
SAS reads the descriptor
information of each data set that is named in the MERGE statement.
Then, SAS creates a program data vector that contains all the variables
from all data sets as well as variables created by the DATA step.
SAS reads the first
observation from each data set into the program data vector, reading
the data sets in the order in which they appear in the MERGE statement.
If two data sets contain the same variables, the values from the second
data set replace the values from the first data set. After reading
the first observation from the last data set and executing any other
statements in the DATA step, SAS writes the contents of the program
data vector to the new data set. Only those variables that are created
or assigned values during the DATA step are set to missing.
Example 1: One-to-One Merging with an Equal Number of Observations
The SAS data sets
ANIMAL and PLANT both contain the variable Common, and the observations
are arranged by the values of Common. The following shows the ANIMAL
and the PLANT input data sets:
ANIMAL PLANT OBS Common Animal OBS Common Plant 1 a Ant 1 a Apple 2 b Bird 2 b Banana 3 c Cat 3 c Coconut 4 d Dog 4 d Dewberry 5 e Eagle 5 e Eggplant 6 f Frog 6 g Fig
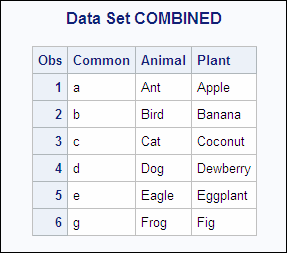
Example 2: One-to-One Merging with an Unequal Number of Observations
The SAS data sets
ANIMAL1 and PLANT1 both contain the variable Common, and the observations
are arranged by the values of Common. The PLANT1 data set has fewer
observations than the ANIMAL1 data set. The following shows the ANIMAL1
and the PLANT1 input data sets:
ANIMAL1 PLANT1 OBS Common Animal OBS Common Plant 1 a Ant 1 a Apple 2 b Bird 2 b Banana 3 c Cat 3 c Coconut 4 d Dog 5 e Eagle 6 f Frog
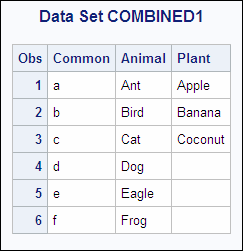
Example 3: One-to-One Merging with Duplicate Values of Common Variables
The following
example shows the undesirable results that you can obtain by using
one-to-one merging with data sets that contain duplicate values of
common variables. The value from the last data set that is read is
the one that is written to the new data set. The variables are combined
exactly as they are read from each data set. In the following example,
the data sets ANIMAL1 and PLANT1 contain the variable Common, and
each data set contains observations with duplicate values of Common.
The following shows the ANIMAL1 and the PLANT1 input data sets:
ANIMAL1 PLANT1 OBS Common Animal OBS Common Plant 1 a Ant 1 a Apple 2 a Ape 2 b Banana 3 b Bird 3 c Coconut 4 c Cat 4 c Celery 5 d Dog 5 d Dewberry 6 e Eagle 6 e Eggplant
/* This program illustrates undesirable results. */ data merge1; merge animal1 plant1; run; proc print data=merge1; title 'Data Set MERGE1'; run;
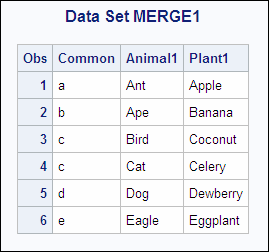
The number of observations
in the new data set is six. Note that observations 2 and 3 contain
undesirable values. SAS reads the second observation from data set
ANIMAL1. It then reads the second observation from data set PLANT1
and replaces the values for the variables Common and Plant1. The third
observation is created in the same way.
Example 4: One-to-One Merging with Different Values of Common Variables
The following
example shows the undesirable results obtained from using the one-to-one
merge to combine data sets with different values of common variables.
If a variable exists in more than one data set, the value from the
last data set that is read is the one that is written to the new data
set even if the value is missing. Once SAS processes all observations
in a data set, all subsequent observations in the new data set have
missing values for the variables that are unique to that data set.
In this example, the data sets ANIMAL2 and PLANT2 have different values
of the Common variable. The following shows the ANIMAL2 and the PLANT2
input data sets:
ANIMAL2 PLANT2
OBS Common Animal OBS Common Plant
1 a Ant 1 a Apple
2 c Cat 2 b Banana
3 d Dog 3 c Coconut
4 e Eagle 4 e Eggplant
5 f Fig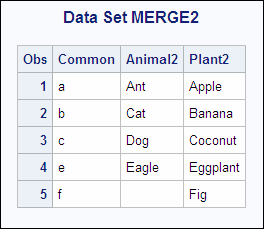
Match-Merging
Definition
Match-merging combines
observations from two or more SAS data sets into a single observation
in a new data set according to the values of a common variable. The
number of observations in the new data set is the sum of the largest
number of observations in each BY group in all data sets. To perform
a match-merge, use the MERGE statement with a BY statement. Before
you can perform a match-merge, all data sets must be sorted by the
variables that you specify in the BY statement or they must have an
index.
Syntax
MERGE data-set(s);
BY variable(s);
For a complete description
of the MERGE and the BY statements, see SAS Statements: Reference.
DATA Step Processing during Match-Merging
SAS reads the descriptor
information of each data set that is named in the MERGE statement
and then creates a program data vector that contains all the variables
from all data sets as well as variables created by the DATA step.
SAS creates the FIRST.variable and
LAST.variable for each variable
that is listed in the BY statement.
SAS looks at the first
BY group in each data set that is named in the MERGE statement to
determine which BY group should appear first in the new data set.
The DATA step reads into the program data vector the first observation
in that BY group from each data set, reading the data sets in the
order in which they appear in the MERGE statement. If a data set does
not have observations in that BY group, the program data vector contains
missing values for the variables unique to that data set.
After processing the
first observation from the last data set and executing other statements,
SAS writes the contents of the program data vector to the new data
set. SAS retains the values of all variables in the program data vector
except those variables that were created by the DATA step; SAS sets
those values to missing. SAS continues to merge observations until
it writes all observations from the first BY group to the new data
set. When SAS has read all observations in a BY group from all data
sets, it sets all variables in the program data vector (except those
created by SAS) to missing. SAS looks at the next BY group in each
data set to determine which BY group should appear next in the new
data set.
Example 1: Combining Observations Based on a Criterion
The SAS
data sets ANIMAL and PLANT each contain the BY variable Common, and
the observations are arranged in order of the values of the BY variable.
The following shows the ANIMAL and the PLANT input data sets:
ANIMAL PLANT OBS Common Animal OBS Common Plant 1 a Ant 1 a Apple 2 b Bird 2 b Banana 3 c Cat 3 c Coconut 4 d Dog 4 d Dewberry 5 e Eagle 5 e Eggplant 6 f Frog 6 f Fig
The following program
merges the data sets according to the values of the BY variable Common,
and prints the results:
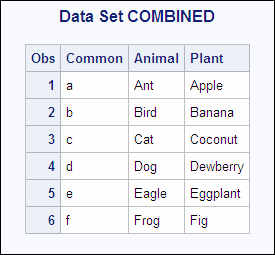
Example 2: Match-Merge with Duplicate Values of the BY Variable
When SAS reads
the last observation from a BY group in one data set, SAS retains
its values in the program data vector for all variables that are unique
to that data set until all observations for that BY group have been
read from all data sets. In the following example, the data sets ANIMAL1
and PLANT1 contain duplicate values of the BY variable Common. The
following shows the ANIMAL1 and the PLANT1 input data sets:
ANIMAL1 PLANT1 OBS Common Animal1 OBS Common Plant1 1 a Ant 1 a Apple 2 a Ape 2 b Banana 3 b Bird 3 c Coconut 4 c Cat 4 c Celery 5 d Dog 5 d Dewberry 6 e Eagle 6 e Eggplant
data match1; merge animal1 plant1; by Common; run; proc print data=match1; title 'Data Set MATCH1'; run;
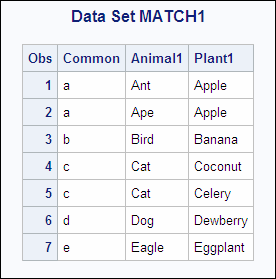
In observation 2 of
the output, the value of the variable Plant1 is retained until all
observations in the BY group are written to the new data set. Match-merging
also produced duplicate values in ANIMAL1 for observations 4 and 5.
Note: The MERGE statement does
not produce a Cartesian product on a many-to-many match-merge. Instead,
it performs a one-to-one merge while there are observations in the
BY group in at least one data set. When all observations in the BY
group have been read from one data set and there are still more observations
in another data set, SAS performs a one-to-many merge until all observations
have been read for the BY group.
Example 3: Match-Merge with Nonmatched Observations
When SAS performs a match-merge
with nonmatched observations in the input data sets, SAS retains the
values of all variables in the program data vector even if the value
is missing. The data sets ANIMAL2 and PLANT2 do not contain all values
of the BY variable Common. The following shows the ANIMAL2 and the
PLANT2 input data sets:
ANIMAL2 PLANT2
OBS Common Animal2 OBS Common Plant2
1 a Ant 1 a Apple
2 c Cat 2 b Banana
3 d Dog 3 c Coconut
4 e Eagle 4 e Eggplant
5 f
Fig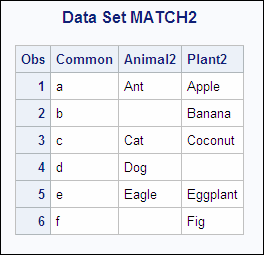
Updating with the UPDATE and the MODIFY Statements
Definitions
Updating a data set refers to the
process of applying changes to a master data set. To update data sets,
you work with two input data sets. The data set containing the original
information is the master data set, and the data set containing the
new information is the transaction data set.
You can update data
sets by using the UPDATE statement or the MODIFY statement:
uses observations from
the transaction data set to change the values of corresponding observations
from the master data set. You must use a BY statement with the UPDATE
statement because all observations in the transaction data set are
keyed to observations in the master data set according to the values
of the BY variable.
The number of observations
in the new data set is the sum of the number of observations in the
master data set and the number of unmatched observations in the transaction
data set.
For complete information
about the UPDATE
and the MODIFY statements, see SAS Statements: Reference.
Syntax of the UPDATE Statement
UPDATE master-data-set transaction-data-set;
BY variable-list;
If the transaction data
set contains duplicate values of the BY variable, SAS applies both
transactions to the observation. The last values that are copied
into the program data vector are written to the new data set. If your
data is in this form, use the MODIFY statement instead of the UPDATE
statement to process your data.
For complete information
about the UPDATE statement, see SAS Statements: Reference.
Syntax of the MODIFY Statement
MODIFY master-data–set;
BY variable-list;
Note: The MODIFY statement does
not support changing the descriptor portion of a SAS data set, such
as adding a variable.
For complete information,
see MODIFY Statement in the SAS Statements: Reference.
DATA Step Processing with the UPDATE Statement
SAS looks at the first
observation in each data set that is named in the UPDATE statement
to determine which BY group should appear first. If the transaction
BY value precedes the master BY value, SAS reads from the transaction
data set only and sets the variables from the master data set to missing.
If the master BY value precedes the transaction BY value, SAS reads
from the master data set only and sets the unique variables from the
transaction data set to missing. If the BY values in the master and
transaction data sets are equal, it applies the first transaction
by copying the nonmissing values into the program data vector.
After completing the
first transaction, SAS looks at the next observation in the transaction
data set. If SAS finds one with the same BY value, it applies that
transaction too. The first observation then contains the new values
from both transactions. If no other transactions exist for that observation,
SAS writes the observation to the new data set and sets the values
in the program data vector to missing. SAS repeats these steps until
it has read all observations from all BY groups in both data sets.
Updating with Nonmatched Observations, Missing Values, and New Variables
In the UPDATE statement, if an observation in the
master data set does not have a corresponding observation in the transaction
data set, SAS writes the observation to the new data set without modifying
it. Any observation from the transaction data set that does not correspond
to an observation in the master data set is written to the program
data vector and becomes the basis for an observation in the new data
set. The data in the program data vector can be modified by other
transactions before it is written to the new data set. If a master
data set observation does not need updating, the corresponding observation
can be omitted from the transaction data set.
SAS does not replace
existing values in the master data set with missing values if those
values are coded as periods (for numeric variables) or blanks (for
character variables) in the transaction data set. To replace existing
values with missing values, you must either create a transaction data
set in which missing values are coded with the special missing value
characters, or use the UPDATEMODE=NOMISSINGCHECK statement option.
With UPDATE, the transaction
data set can contain new variables to be added to all observations
in the master data set.
To view a sample program,
see
Example 3: Using UPDATE for Processing Nonmatched Observations, Missing Values, and New Variables.
Sort Requirements for the UPDATE Statement
If you do not use an index, both
the master data set and the transaction data set must be sorted by
the same variable or variables that you specify in the BY statement
that accompanies the UPDATE statement. The values of the BY variable
should be unique for each observation in the master data set. If
you use more than one BY variable, the combination of values of all
BY variables should be unique for each observation in the master data
set. The BY variable or variables should be ones that you never need
to update.
Choosing between UPDATE or MODIFY with BY
Using the UPDATE statement
is comparable to using MODIFY with BY to apply transactions to a data
set. MODIFY is a more powerful tool with several other applications,
but UPDATE is still the tool of choice in some cases. The following
table helps you choose whether to use UPDATE or MODIFY with BY.
For more information
about tools for combining SAS data sets, see
Statements or Procedures for Combining SAS Data Sets.
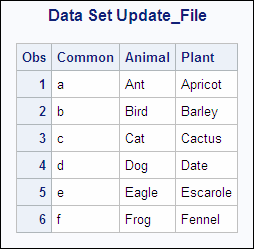
Example 1: Using UPDATE for Basic Updating
In this example, the data set MASTER contains original
values of the variables Animal and Plant. The data set NEWPLANT is
a transaction data set with new values of the variable Plant. The
following shows the MASTER and the NEWPLANT input data sets:
MASTER NEWPLANT OBS Common Animal Plant OBS Common Plant 1 a Ant Apple 1 a Apricot 2 b Bird Banana 2 b Barley 3 c Cat Coconut 3 c Cactus 4 d Dog Dewberry 4 d Date 5 e Eagle Eggplant 5 e Escarole 6 f Frog Fig 6 f Fennel
The following program
updates MASTER with the transactions in the data set NEWPLANT, writes
the results to UPDATE_FILE, and prints the results:
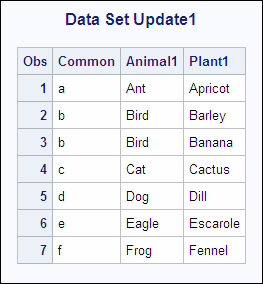
Example 2: Using UPDATE with Duplicate Values of the BY Variable
If the
master data set contains two observations with the same value of the
BY variable, the first observation is updated and the second observation
is ignored. SAS writes a warning message to the log. If the transaction
data set contains duplicate values of the BY variable, SAS applies
both transactions to the observation. The last values copied into
the program data vector are written to the new data set. The following
shows the MASTER1 and the DUPPLANT input data sets.
MASTER1 DUPPLANT OBS Common Animal1 Plant1 OBS Common Plant1 1 a Ant Apple 1 a Apricot 2 b Bird Banana 2 b Barley 3 b Bird Banana 3 c Cactus 4 c Cat Coconut 4 d Date 5 d Dog Dewberry 5 d Dill 6 e Eagle Eggplant 6 e Escarole 7 f Frog Fig 7 f Fennel
data update1; update master1 dupplant; by Common; run; proc print data=update1; title 'Data Set Update1'; run;
Example 3: Using UPDATE for Processing Nonmatched Observations, Missing Values, and New Variables
In this example, the data
set MASTER2 is a master data set. It contains a missing value for
the variable Plant2 in the first observation, and not all of the values
of the BY variable Common are included. The transaction data set NONPLANT
contains a new variable Mineral, a new value of the BY variable Common,
and missing values for several observations. The following shows
the MASTER2 and the NONPLANT input data sets:
MASTER2 NONPLANT
OBS Common Animal2 Plant2 OBS Common Plant2 Mineral
1 a Ant 1 a Apricot Amethyst
2 c Cat Coconut 2 b Barley Beryl
3 d Dog Dewberry 3 c Cactus
4 e Eagle Eggplant 4 e
5 f Frog Fig 5 f Fennel
6 g Grape Garnet
data update2_file; update master2 nonplant; by Common; run; proc print data=update2_file; title 'Data Set Update2_File'; run;
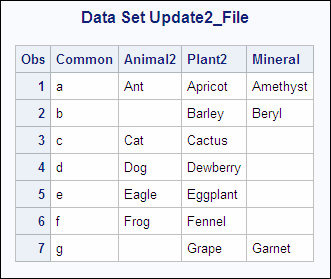
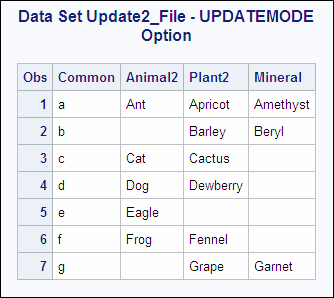
As shown, all observations
now include values for the variable Mineral. The value of Mineral
is set to missing for some observations. Observations 2 and 6 in the
transaction data set did not have corresponding observations in MASTER2,
and they have become new observations. Observation 3 from the master
data set was written to the new data set without change, and the value
for Plant2 in observation 4 was not changed to missing. Three observations
in the new data set have updated values for the variable Plant2.
The following program
uses the UPDATEMODE statement option in the UPDATE statement, and
prints the results:
data update2_file; update master2 nonplant updatemode=nomissingcheck; by Common; run; proc print data=update2_file; title 'Data Set Update2_File - UPDATEMODE Option'; run;
Example 4: Updating a MASTER Data Set By Adding an Observation
If
the transaction data set contains an observation that does not match
an observation in the master data set, you must alter the program.
The Year value in observation 5 of TRANSACTION has no match in MASTER.
The following shows the MASTER and the TRANSACTION input data sets:
MASTER TRANSACTION OBS Year VarX VarY OBS Year VarX VarY 1 2004 x1 y1 1 2010 x2 2 2005 x1 y1 2 2011 x2 y2 3 2006 x1 y1 3 2012 x2 4 2007 x1 y1 4 2012 y2 5 2008 x1 y1 5 2014 x2 y2 6 2009 x1 y1 7 2010 x1 y1 8 2011 x1 y1 9 2012 x1 y1 10 2013 x1 y1
You must use an explicit
OUTPUT statement to write a new observation to a master data set.
(The default action for a DATA step using a MODIFY statement is REPLACE,
not OUTPUT.) Once you specify an explicit OUTPUT statement, you must
also specify a REPLACE statement. The following DATA step updates
data set MASTER, based on values in TRANSACTION, and adds a new observation.
This program also uses the _IORC_ automatic variable for error checking.
(For more information about error checking, see
Error Checking When Using Indexes to Randomly Access or Update Data.