Which to Use? DATA Step or the SCORE Statement
Advantages, Disadvantages, and Best Practices
The following list highlights
some of the advantages and disadvantages for each approach:
-
If you know that you want to run code in the server, then using the SCORE statement to the IMSTAT procedure provides assurance. Either the code runs in the server and the statement succeeds or the statement fails. Large tables are never transferred from the server to the client for processing.
-
If you want to use the
__first_in_partitionor__last_in_partitionvariables, you must use the SCORE statement. Those variables can be used to provide some similarity to BY-group processing with FIRST. and LAST. variables. -
To use the DATA step and keep processing in the server, your program must use the DSACCEL=ANY system option and meet the requirements that are commonly associated with scoring. In this case, the DATA step determines that the requirements are met and performs the optimization of running in the server.
-
Error messages are more helpful and troubleshooting is easier when you are using the DATA step than when you are running a program with the SCORE statement.
As a best practice,
initial development with the DATA step provides rapid development.
After the program is complete, or nearly so, switching to run the
program with the SCORE statement provides assurance that the program
runs in the server.
When you work with the
SCORE action, use the IMSTAT procedure’s PGMMSG option so that
the server records any error information. You can read this information
in the &_PGMMSG_ temporary table. PUT statements in your program
are written to that table rather than the SAS log.
As a final consideration,
before writing a DATA step program, check the list of alternatives
in the preceding section to see whether a statement for the IMSTAT
procedure can accomplish your goal. The GROUPBY, AGGREGATE, and TRANSFORM
statements can be used to perform data preparation on in-memory tables.
Using the BALANCE Statement to Subset a Table
All the statements for
the IMSTAT procedure that operate on rows of data support WHERE expression
processing. For example, the following code generates summary statistics
for all cars with more than 300 horsepower:
libname example sasiola host="grid001.example.com" port=10010 tag="hps";
data example.cars; set sashelp.cars; run;
proc imstat;
table example.cars;
where horsepower > 300;
summary;
run;Using a WHERE expression
to subset data is a best practice because it is efficient and avoids
duplicating data in memory. However, if you must create a new table,
you can use the BALANCE statement with a WHERE expression:
proc imstat;
table example.cars;
where horsepower > 300;
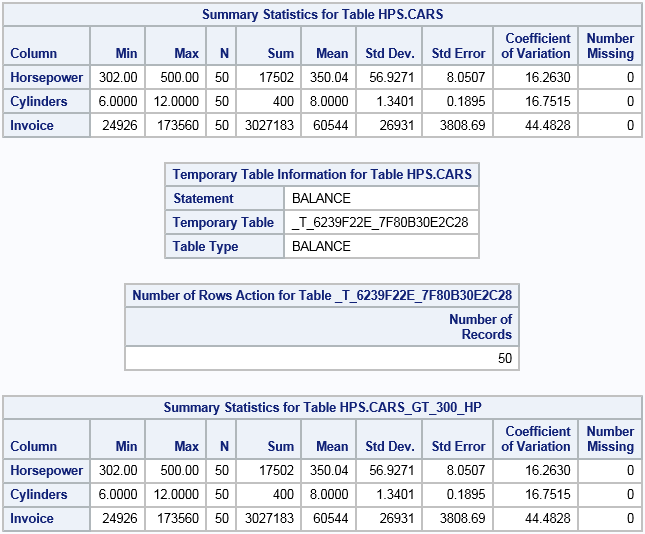
summary horsepower cylinders invoice; 1
run;
balance; 2
run;
table example.&_TEMPLAST_;
numrows; 3
run;
promote cars_gt_300_hp; 4
run;
table example.cars_gt_300_hp;
summary horsepower cylinders invoice;
run;| 1 | The first SUMMARY statement is subject to the WHERE expression. This is the most efficient way to work with tables and should be used whenever possible. The results show that the minimum value is 302. |
| 2 | The BALANCE statement creates a new temporary table. The Cars table is still the active table and it is still subject to the WHERE expression. For distributed servers, the observations in the temporary table are distributed amongst the machines in the cluster evenly for an even workload. |
| 3 | The NUMROWS action is used in this example to demonstrate that the number of observations in the new temporary table matches the value of N from the first SUMMARY statement. |
| 4 | The PROMOTE statement makes the temporary table into a regular table and gives it a name. It must be set as the active table with the TABLE statement. The final SUMMARY statement demonstrates that the results are identical to the first SUMMARY statement. |
Copyright © SAS Institute Inc. All Rights Reserved.