Time Series Analysis and Examples
The measurement (or observation) equation can be written as
where ![]() is an
is an ![]() vector,
vector, ![]() is an
is an ![]() matrix, the sequence of observation noise
matrix, the sequence of observation noise ![]() is independent,
is independent, ![]() is an
is an ![]() state vector, and
state vector, and ![]() is an
is an ![]() observed vector.
observed vector.
The transition (or state) equation is denoted as a first-order Markov process of the state vector,
where ![]() is an
is an ![]() vector,
vector, ![]() is an
is an ![]() transition matrix, and the sequence of transition noise
transition matrix, and the sequence of transition noise ![]() is independent. This equation is often called a shifted transition equation, because the state vector is shifted forward one time period. The transition equation can also be denoted by using an alternative
specification,
is independent. This equation is often called a shifted transition equation, because the state vector is shifted forward one time period. The transition equation can also be denoted by using an alternative
specification,
There is no real difference between the shifted transition equation and this alternative equation if the observation noise
and transition equation noise are uncorrelated—that is, ![]() . It is assumed that
. It is assumed that
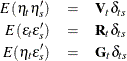
where
De Jong (1991) proposed a diffuse Kalman filter that can handle an arbitrarily large initial state covariance matrix. The diffuse initial state assumption is reasonable if you encounter the case of parameter uncertainty or SSM nonstationarity. The SSM of the diffuse Kalman filter is written as
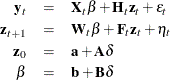
where ![]() is a random variable with a mean of
is a random variable with a mean of ![]() and a variance of
and a variance of ![]() . When
. When ![]() , the SSM is said to be diffuse.
, the SSM is said to be diffuse.
The KALCVF call computes the one-step prediction ![]() and the filtered estimate
and the filtered estimate ![]() , together with their covariance matrices
, together with their covariance matrices ![]() and
and ![]() , by using forward recursions. You can obtain the k-step prediction
, by using forward recursions. You can obtain the k-step prediction ![]() and its covariance matrix
and its covariance matrix ![]() by using the KALCVF call. The KALCVS call uses backward recursions to compute the smoothed estimate
by using the KALCVF call. The KALCVS call uses backward recursions to compute the smoothed estimate ![]() and its covariance matrix
and its covariance matrix ![]() when there are T observations in the complete data.
when there are T observations in the complete data.
The KALDFF call produces one-step prediction of the state and the unobserved random vector ![]() along with their covariance matrices. The KALDFS call computes the smoothed estimate
along with their covariance matrices. The KALDFS call computes the smoothed estimate ![]() and its covariance matrix
and its covariance matrix ![]() .
.