Once you have referenced the data file that contains your data with an INFILE statement, you need to tell IML the following information about how the data are arranged:
-
the number of variables and their names
-
each variable’s type, either numeric or character
-
the format of each variable’s values
-
the columns that correspond to each variable
In other words, you must tell IML how to read the data.
The INPUT statement describes the arrangement of values in an input record. The INPUT statement reads records from a file specified in the previously executed INFILE statement, reading the values into IML variables.
There are two ways to describe a record’s values in an IML INPUT statement:
-
list (or scanning) input
-
formatted input
Following are several examples of valid INPUT statements for the class data file, depending, of course, on how the data are stored.
If the data are stored with a blank or a comma between fields, then list input can be used. For example, the INPUT statement for the class data file might look as follows:
infile inclass; input name $ sex $ age height weight;
These statements tell IML the following:
-
There are five variables:
NAME,SEX,AGE,HEIGHTandWEIGHT. -
Data fields are separated by commas or blanks.
-
NAMEandSEXare character variables, as indicated by the dollar sign ($). -
AGE,HEIGHT, andWEIGHTare numeric variables, the default.
The data must be stored in the same order in which the variables are listed in the INPUT statement. Otherwise, you can use formatted input, which is column specific. Formatted input is the most flexible and can handle any data file. Your INPUT statement for the class data file might look as follows:
infile inclass;
input @1 name $char8. @10 sex $char1. @15 age 2.0
@20 height 4.1 @25 weight 5.1;
These statements tell IML the following:
-
NAMEis a character variable; its value begins in column 1 (indicated by @1) and occupies eight columns ($CHAR8.). -
SEXis a character variable; its value is found in column 10 ($CHAR1.). -
AGEis a numeric variable; its value is found in columns 15 and 16 and has no decimal places (2.0). -
HEIGHTis a numeric variable found in columns 20 through 23 with one decimal place implied (4.1). -
WEIGHTis a numeric variable found in columns 25 through 29 with one decimal place implied (5.1).
The next sections discuss these two modes of input.
If your data are recorded with a comma or one or more blanks between data fields, you can use list input to read your data. If you have missing values—that is, unknown values—they must be represented by a period (.) rather than a blank field.
When IML looks for a value, it skips past blanks and tab characters. Then it scans for a delimiter to the value. The delimiter is a blank, a comma, or the end of the record. When the ampersand (&) format modifier is used, IML looks for two blanks, a comma, or the end of the record.
The general form of the INPUT statement for list input is as follows:
INPUT variable <$> <&> <…variable <$> > <&> > ;
where
- variable
-
names the variable to be read by the INPUT statement.
- $
-
indicates that the preceding variable is character.
- &
-
indicates that a character value can have a single embedded blank. Because a blank normally indicates the end of a data value, use the ampersand format modifier to indicate the end of the value with at least two blanks or a comma.
With list input, IML scans the input lines for values. Consider using list input in the following cases:
-
when blanks or commas separate input values
-
when periods rather than blanks represent missing values
List input is the default in several situations. Descriptions of these situations and the behavior of IML follow:
-
If no input format is specified for a variable, IML scans for a number.
-
If a single dollar sign or ampersand format modifier is specified, IML scans for a character value. The ampersand format modifier enables single embedded blanks to occur.
-
If a format is given with width unspecified or zero, IML scans for the first blank or comma.
If the end of a record is encountered before IML finds a value, then the behavior is as described by the record overflow options in the INFILE statement discussed in the section Using the INFILE Statement.
When you read with list input, the order of the variables listed in the INPUT statement must agree with the order of the values in the data file. For example, consider the following data:
Alice f 10 61 97 Beth f 11 64 105 Bill m 12 63 110
You can use list input to read these data by specifying the following INPUT statement:
input name $ sex $ age height weight;
Note: This statement implies that the variables are stored in the order given. That is, each line of data contains a student’s name, sex, age, height, and weight in that order and separated by at least one blank or by a comma.
The alternative to list input is formatted input. An INPUT statement reading formatted input must have a SAS informat after each variable. An informat gives the data type and field width of an input value. Formatted input can be used with pointer controls and format modifiers. Note, however, that neither pointer controls nor format modifiers are necessary for formatted input.
Pointer controls reset the pointer’s column and line positions and tell the INPUT statement where to go to read the data value. You use pointer controls to specify the columns and lines from which you want to read:
-
Column pointer controls move the pointer to the column you specify.
-
Line pointer controls move the pointer to the next line.
-
Line hold controls keep the pointer on the current input line.
-
Binary file indicator controls indicate that the input line is from a binary file.
Column pointer controls indicate in which column an input value starts. Column pointer controls begin with either an at sign (@) or a plus sign (+). A complete list follows:
- @

-
moves the pointer to column
.
- @point-variable
-
moves the pointer to the column given by the current value of point-variable.
- @(expression)
-
moves the pointer to the column given by the value of the expression. The expression must evaluate to a positive integer.
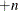
-
moves the pointer
columns.
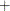 point-variable
point-variable-
moves the pointer the number of columns given by the value of point-variable.
- (expression)
-
moves the pointer the number of columns given by the value of expression. The value of expression can be positive or negative.
Here are some examples of using column pointer controls:
|
Example |
Meaning |
|
|---|---|---|
|
@12 |
go to column 12 |
|
|
@N |
go to the column given by the value of N |
|
|
@(N |
go to the column given by the value of N |
|
|
+5 |
skip 5 spaces |
|
|
+N |
skip N spaces |
|
|
+(N+1) |
skip N+1 spaces |
In the earlier example that used formatted input, you used several pointer controls. Here are the statements:
infile inclass;
input @1 name $char8. @10 sex $char1. @15 age 2.0
@20 height 4.1 @25 weight 5.1;
The @1 moves the pointer to column 1, the @10 moves it to column 10, and so on. You move the pointer to the column where the data field begins and then supply an informat specifying how many columns the variable occupies. The INPUT statement could also be written as follows:
input @1 name $char8. +1 sex $char1. +4 age 2. +3 height 4.1
+1 weight 5.1;
In this form, you move the pointer to column 1 (@1) and read eight columns. The pointer is now at column 9. Now, move the
pointer +1 columns to column 10 to read SEX. The $char1. informat says to read a character variable occupying one column. After you read the value for SEX, the pointer is at column 11, so move it to column 15 with +4 and read AGE in columns 15 and 16 (the 2. informat). The pointer is now at column 17, so move +3 columns and read HEIGHT. The same idea applies for reading WEIGHT.
The line pointer control (/) directs IML to skip to the next line of input. You need a line pointer control when a record of data takes more than one line. You use the new line pointer control (/) to skip to the next line and continue reading data. In the example reading the class data, you do not need to skip a line because each line of data contains all the variables for a student.
The trailing at sign (@), when at the end of an INPUT statement, directs IML to hold the pointer on the current record so that you can read more data with subsequent INPUT statements. You can use it to read several records from a single line of data. Sometimes, when a record is very short—say, 10 columns or so—you can save space in your external file by coding several records on the same line.
When the external file you want to read is a binary file (RECFM=N is specified in the INFILE statement), you must tell IML how to read the values by using the following binary file indicator controls:
- >
-
start reading the next record at the byte position
in the file.
- >point-variable
-
start reading the next record at the byte position in the file given by point-variable.
- >(expression)
-
start reading the next record at the byte position in the file given by expression.
- <
-
read the number of bytes indicated by the value of
.
- <point-variable
-
read the number of bytes indicated by the value of point-variable.
- <(expression)
-
read the number of bytes indicated by the value of expression.
You can have the input mechanism search for patterns of text by using the at sign (@) with a character operand. IML starts searching at the current position, advances until it finds the pattern, and leaves the pointer at the position immediately after the found pattern in the input record. For example, the following statement searches for the pattern NAME= and then uses list input to read the value after the found pattern:
input @ 'NAME=' name $;
If the pattern is not found, then the pointer is left past the end of the record, and the rest of the INPUT statement follows the conventions based on the options MISSOVER, STOPOVER, and FLOWOVER described in the section Using the INFILE Statement. If you use pattern searching, you usually specify the MISSOVER option so that you can control for the occurrences of the pattern not being found.
Notice that the MISSOVER feature enables you to search for a variety of items in the same record, even if some of them are not found. For example, the following statements are able to read in the ADDR variable even if NAME= is not found (in which case, NAME is unvalued):
infile in1 missover;
input @1 @ "NAME=" name $
@1 @ "ADDR=" addr &
@1 @ "PHONE=" phone $;
The pattern operand can use any characters except for the following:
|
% |
$ |
[ ] |
{ } |
< |
> |
|
? |
* |
# |
@ |
^ |
(backquote) |
Each INPUT statement goes to a new record except in the following special cases:
-
An at sign (@) at the end of an INPUT statement specifies that the record is to be held for future INPUT statements.
-
Binary files (RECFM=N) always hold their records until the > directive.
As discussed in the syntax of the INPUT statement, the line pointer operator (/) instructs the input mechanism to go immediately to the next record. For binary (RECFM=N) files, the > directive is used instead of the /.
For character values, the informat determines the way blanks are interpreted. For example, the $CHAR![]() . format reads blanks as part of the whole value, while the BZ
. format reads blanks as part of the whole value, while the BZ![]() . format turns blanks into zeros. See SAS Language Reference: Dictionary for more information about informats.
. format turns blanks into zeros. See SAS Language Reference: Dictionary for more information about informats.
Missing values in formatted input are represented by blanks or a single period for a numeric value and by blanks for a character value.
Data values are either character or numeric. Input variables always result in scalar (one row by one column) values with type (character or numeric) and length determined by the input format.
End of file is the condition of trying to read a record when there are no more records to read from the file. The consequences of an end-of-file condition are described as follows.
-
All the variables in the INPUT statement that encountered end of file are freed of their values. You can use the NROW or NCOL function to test if this has happened.
-
If end of file occurs inside a DO DATA loop, execution is passed to the statement after the END statement in the loop.
For text files, end of file is encountered first as the end of the last record. The next time input is attempted, the end-of-file condition is raised.
For binary files, end of file can result in the input mechanism returning a record that is shorter than the requested length. In this case IML still attempts to process the record, using the rules described in the section Using the INFILE Statement.
The DO DATA mechanism provides a convenient mechanism for handling end of file.
For example, to read the class data from the external file USER.TEXT.CLASS into a SAS data set, you need to perform the following steps:
-
Establish a fileref referencing the data file.
-
Use an INFILE statement to open the file for input.
-
Initialize any character variables by setting the length.
-
Create a new SAS data set with a CREATE statement. You want to list the variables you plan to input in a VAR clause.
-
Use a DO DATA loop to read the data one line at a time.
-
Write an INPUT statement telling IML how to read the data.
-
Use an APPEND statement to add the new data line to the end of the new SAS data set.
-
End the DO DATA loop.
-
Close the new data set.
-
Close the external file with a CLOSEFILE statement.
Your statements should look as follows:
filename inclass 'user.text.class';
infile inclass missover;
name="12345678";
sex="1";
create class var{name sex age height weight};
do data;
input name $ sex $ age height weight;
append;
end;
close class;
closefile inclass;
Note that the APPEND statement is not executed if the INPUT statement reads past the end of file since IML escapes the loop immediately when the condition is encountered.
If you are familiar with the SAS DATA step, you will notice that the following features are supported differently or are not supported in IML:
-
The pound sign (#) directive supporting multiple current records is not supported.
-
Grouping parentheses are not supported.
-
The colon (:) format modifier is not supported.
-
The byte operands (< and >) are new features supporting binary files.
-
The ampersand (&) format modifier causes IML to stop reading data if a comma is encountered. Use of the ampersand format modifier is valid with list input only.
-
The RECFM=F option is not supported.