You can use the Method tab to set options in the analysis. (See Figure 30.3.) The Method tab contains the following UI controls:
- Classification method
-
specifies the method used to construct the discriminant function.
- Parametric
-
specifies that a parametric method based on a multivariate normal distribution within each group be used to derive a linear or quadratic discriminant function. This corresponds to the METHOD=NORMAL option in the PROC DISCRIM statement.
- k nearest neighbors
-
specifies that a nonparametric classification method be used. An observation is classified into a group based on the information from the
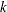 nearest neighbors of the observation. This corresponds to the METHOD=NPAR K= option in the PROC DISCRIM statement.
nearest neighbors of the observation. This corresponds to the METHOD=NPAR K= option in the PROC DISCRIM statement.
- Kernel density
-
specifies that a nonparametric classification method be used. An observation is classified into a group based on the information from observations within a given radius of the observation. This corresponds to the METHOD=NPAR R= option in the PROC DISCRIM statement.
- k
-
specifies the number of nearest neighbors for the method. You can select a fixed number of observations, or a proportion of the total number of observations. You can type a value in this field or choose from a set of standard values. This option corresponds to the K= or KPROP= option in the PROC DISCRIM statement.
- Kernel
-
specifies the shape of the kernel function for the method. You can specify a uniform, Epanechnikov (quadratic), or normal kernel function. This corresponds to the KERNEL= option in the PROC DISCRIM statement.
- Bandwidth
-
specifies the bandwidth for the kernel density classification method. This corresponds to the R= option in the PROC DISCRIM statement. There are two options for choosing the bandwidth:
- Maximum of radii that minimizes AMISE of group densities
-
This option uses a heuristic to automatically choose a bandwidth. The “Background” subsection of the “Details” section in the documentation for the DISCRIM procedure presents formulas for the bandwidths that minimize an approximate mean integrated square error of the estimated density within each group. The formulas assume the data within each group are multivariate normal.
The optimal radius for each group is determined for each group, as shown in Figure 30.5. Descriptive statistics of the radii are also displayed, including the mean of the radii weighted by the number of observations in each group. The bandwidth used for the R= option in the PROC DISCRIM statement is the maximum of the radii.
- Manual
-
sets the kernel bandwidth to the value in the Value field.
- Covariance within groups
-
specifies assumptions about the homogeneity of within-group covariances. This option corresponds to the POOL= option in the PROC DISCRIM statement. For the parametric classification method, the assumption of equal covariances results in a linear discriminant function. The assumption of unequal covariances results in a quadratic discriminant function.
- Prior probability of group membership
-
specifies assumptions about the prior probabilities of group membership. This option corresponds to the EQUAL and PROPORTIONAL options in the PRIORS statement.
- Classify observations by
-
specifies a method of classifying observations based on their canonical scores. This option corresponds to the CROSSVALIDATE option in the PROC DISCRIM statement.