The MDC Procedure
Multinomial Discrete Choice Modeling
When the dependent variable takes multiple discrete values, you can use multinomial discrete choice modeling to analyze the data. This section considers models for unordered multinomial data.
Let the random utility function be defined by
![\[ U_{ij} = V_{ij} + \epsilon _{ij} \]](images/etsug_mdc0001.png)
where the subscript i is an index for the individual, the subscript j is an index for the alternative, 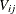 is a nonstochastic utility function, and
is a nonstochastic utility function, and 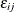 is a random component (error) that captures unobserved characteristics of alternatives or individuals or both. In multinomial
discrete choice models, the utility function is assumed to be linear, so that
is a random component (error) that captures unobserved characteristics of alternatives or individuals or both. In multinomial
discrete choice models, the utility function is assumed to be linear, so that 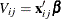 .
.
In the conditional logit model, each for all 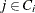 is distributed independently and identically (iid) with the Type I extreme-value distribution,
is distributed independently and identically (iid) with the Type I extreme-value distribution, 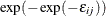 , also known as the Gumbel distribution.
, also known as the Gumbel distribution.
The iid assumption on the random components of the utilities of the different alternatives can be relaxed to overcome the well-known and restrictive independence from irrelevant alternatives (IIA) property of the conditional logit model. This allows for more flexible substitution patterns among alternatives than the one imposed by the conditional logit model. See the section Independence from Irrelevant Alternatives (IIA).
The nested logit model is derived by allowing the random components to be identical but nonindependent. Instead of independent Type I extreme-value errors, the errors are assumed to have a generalized extreme-value distribution. This model generalizes the conditional logit model to allow for particular patterns of correlation in unobserved utility (McFadden 1978).
Another generalization of the conditional logit model, the heteroscedastic extreme-value (HEV) model, is obtained by allowing independent but nonidentical errors distributed with a Type I extreme-value distribution (Bhat 1995). It permits different variances on the random components of utility across the alternatives.
Mixed logit models are also generalizations of the conditional logit model that can represent very general patterns of substitution among alternatives. See the Mixed Logit Model section for details.
The multinomial probit (MNP) model is derived when the errors, 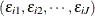 , have a multivariate normal (MVN) distribution. Thus, this model accommodates a very general error structure.
, have a multivariate normal (MVN) distribution. Thus, this model accommodates a very general error structure.
The multinomial probit model requires burdensome computation compared to a family of multinomial choice models derived from
the Gumbel distributed utility function, since it involves multi-dimensional integration (with dimension 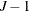 ) in the estimation process. In addition, the multinomial probit model requires more parameters than other multinomial choice
models. As a result, conditional and nested logit models are used more frequently, even though they are derived from a utility
function whose random component is more restrictively defined than the multinomial probit model.
) in the estimation process. In addition, the multinomial probit model requires more parameters than other multinomial choice
models. As a result, conditional and nested logit models are used more frequently, even though they are derived from a utility
function whose random component is more restrictively defined than the multinomial probit model.
The event of a choice being made, 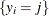 , can be expressed using a random utility function
, can be expressed using a random utility function
![\[ U_{ij} \geq \mathbf{max}_{k \in C_{i}, k \neq j} U_{ik} \]](images/etsug_mdc0064.png)
where 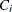 is the choice set of individual i. Individual i chooses alternative j if and only if it provides a level of utility that is greater than or equal to that of any other alternative in his choice
set. Then, the probability that individual i chooses alternative j (from among the
is the choice set of individual i. Individual i chooses alternative j if and only if it provides a level of utility that is greater than or equal to that of any other alternative in his choice
set. Then, the probability that individual i chooses alternative j (from among the 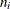 choices in his choice set ) is
choices in his choice set ) is
![\[ P_{i}(j) = P_{ij} = P[\mathbf{x}_{ij}’\bbeta +\epsilon _{ij} \geq \mathbf{max}_{k \in C_{i}} (\mathbf{x}_{ik}’\bbeta +\epsilon _{ik})] \]](images/etsug_mdc0067.png)