| The SEVERITY Procedure |
| Input Data Sets |
PROC SEVERITY accepts DATA= and INEST= data sets as input data sets. This section details the information they are expected to contain.
DATA= Data Set
The DATA= data set is expected to contain the values of the analysis variables specified in the MODEL statement.
If BY variables are specified in the BY statement, then the DATA= data set must contain all the variables specified in the BY statement and the data set must be sorted by the BY variables unless the NOTSORTED option is used in the BY statement.
The data set must also contain the following variables:
- <response variable>
the response variable that is specified in the MODEL statement.- <Regressor 1> ... <Regressor K>
 regressor variables that are specified in the MODEL statement. can be 0.
regressor variables that are specified in the MODEL statement. can be 0. - <left-truncation variable>
If a left-truncation variable is specified by using the LEFTTRUNCATED= option in the MODEL statement, then that variable must be present.- <right-censoring variable>
If a right-censoring indicator variable is specified by using the RIGHTCENSORED= option in the MODEL statement, then that variable must be present.
INEST= Data Set
The INEST= data set is expected to contain the initial values of the parameters for the parameter estimation process.
If BY variables are specified in the BY statement, then the INEST= data set must contain all the variables specified in the BY statement. If the NOTSORTED option is not specified in the BY statement, then the INEST= data set must be sorted by the BY variables. However, it is not required to contain all the BY groups present in the DATA= data set. For the BY groups that are not present in the INEST= data set, the default parameter initialization method is used. If the NOTSORTED option is specified in the BY statement, then the INEST= data set must contain all the BY groups that are present in the DATA= data set and they must appear in the same order as they appear in the DATA= data set.
In addition to any variables specified in the BY statement, the data set must contain the following variables:
- _MODEL_
identifying name of the distribution for which the estimates are provided.
- _TYPE_
type of the estimate. The value of this variable must be EST for an observation to be valid.
- <Parameter 1> ...<Parameter M>
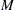 variables, named after the parameters of all candidate distributions, that contain initial values of the respective parameters. is the cardinality of the union of parameter name sets from all candidate distributions. In an observation, estimates are read only from variables for parameters that correspond to the distribution specified by the _MODEL_ variable.
variables, named after the parameters of all candidate distributions, that contain initial values of the respective parameters. is the cardinality of the union of parameter name sets from all candidate distributions. In an observation, estimates are read only from variables for parameters that correspond to the distribution specified by the _MODEL_ variable. If you specify a missing value for some parameters, then default initial values are used unless the parameter is initialized by using the INIT= option in the DIST statement. If you want to use the dist_PARMINIT subroutine for initializing the parameters of a model, then you should either not specify the model in the INEST= data set or specify missing values for all the distribution parameters in the INEST= data set and not use the INIT= option in the DIST statement.
If regressors are specified, then the initial value provided for the first parameter of each distribution must be the base value of the scale or log-transformed scale parameter. See the section Estimating Regression Effects for details.
- <Regressor 1> ...<Regressor K>
If regressors are specified in the MODEL statement, then the INEST= data set must contain variables that are named for each regressor. The variables contain initial values of the respective regression coefficients. If a regressor is linearly dependent on other regressors for a given BY group, then you can indicate this by providing a special missing value of .R for the respective variable. In a given BY group, if a variable is marked as linearly dependent for one model, then it must be marked so for all the models. Similarly, if a variable is not marked as linearly dependent for one model, then it must be marked so for all the models.
Note: This procedure is experimental.
Copyright © SAS Institute, Inc. All Rights Reserved.