Creating a Pig Job
Problem
You want to submit user-written Pig Latin code in the flow for a SAS Data Integration
Studio job.
Solution
You can create a SAS Data Integration Studio job that contains the Pig transformation.
This transformation enables you to submit your
own Pig Latin code in the context of a job. Pig Latin is a high-level language used
for expressing and evaluating data analysis programs. It is assumed that you know Pig Latin well enough to use it in a production
environment.
Perform the following
tasks.
Tasks
Create a Pig Job
The Pig job for this example contains a text table used as a source table, a Transfer to Hadoop transformation, a target table and a Pig transformation. This job structure enables you to transform the text
table into a Hadoop file that can be processed in the Pig transformation.
Perform the following
steps to create and populate the job:
-
Create an empty SAS Data Integration Studio job.
-
Locate the source table in the Inventory tree. Then, drop it in the empty job on the Diagram tab in the Job Editor window. The source table for this sample job is a text table named numbers.txt.
-
Select a Transfer to Hadoop transformation from the Hadoop folder in the Transformations tree. Then, drop it onto the Diagram tab.
-
Connect the source table to the Transfer to Hadoop transformation.
-
Locate the target table and drop it onto the Diagram tab. The target table for this sample job is a Hadoop table named numbers_target.Note that the All files in this location check box must be selected on the File Location tab in the properties window for the Pig target table. This step enables you to see the data in the table after the job has completed successfully.
-
Connect the Transfer to Hadoop transformation to the target table.
-
Select a Pig transformation from the Hadoop folder in the Transformations tree. Then, drop it onto the Diagram tab.
-
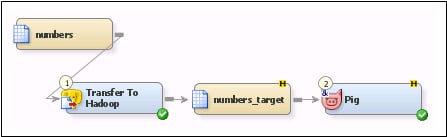
Connect the target table to the Pig transformation. The Diagram tab for the job is shown in the following display:Pig Job Flow
Configure the Job
The configuration for
the Pig transformation is simple. Open the Hadoop Options tab
and select the Delete outputs before executing hadoop
statements check box.
The configuration needed for the Pig transformation varies from job to job. This sample
job requires that you add three Pig Latin statements and four
substitution parameters on the Pig Latin tab.
The tab is shown in
the following display:
Pig Latin Tab
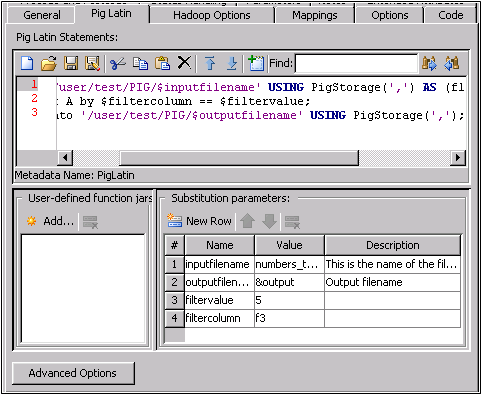
Note that the Pig Latin
statements are entered in the Pig Latin field. The sample job contains the following statements:
A = load '/user/test/PIG/$inputfilename' USING PigStorage(',')
AS (f1:int,f2:int,f3:int);
B1 = filter A by $filtercolumn == $filtervalue;
store B1 into '/user/test/PIG/$outputfilename' USING PigStorage(',');
Similarly, the substitution parameters are entered
in the Substitution parameters field, as
follows:Name = inputfilename, Value = numbers_target.txt, Description = This is the name of the file loaded into hadoop Name = outputfilename, Value = &output, Description = Output filename Name = filtervalue, Value = 5 Name = filtercolumn, Value = f3
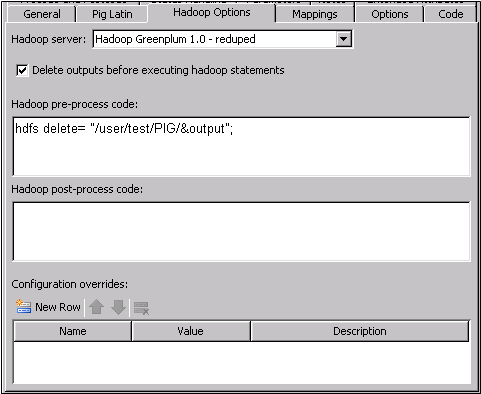
You also need to open
the Hadoop Options tab to select the Delete
outputs before executing hadoop statements check box.
Then, enter appropriate
code into the Hadoop pre-process code field,
as shown in the following display:
Hadoop Options in the Pig Transformation
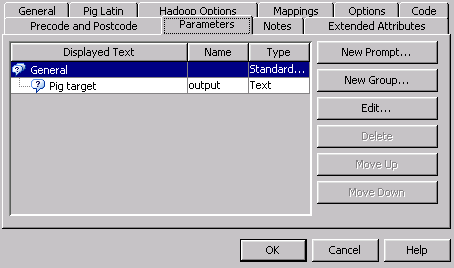
Finally, you need to
create a new prompt for the substitution parameter on the Parameters tab. The general values for this job are
Name=output and Displayed
text=Pig target. The prompt type and values are Prompt
type=Text and Default value=PIG_SubstitutionParamtarget.txt.
The following display
shows the completed Parameters tab:
Parameters Tab
Run the Job and Review the Output
Run the job and verify that the job completes without error. Then, you can use the
Hadoop monitoring
tools to review the output. Right-click the Pig transformation on the Diagram tab and select Hadoop Monitoring Distributed file
system viewer. Then, click Browse
the filesystem and drill down through the User folder
and the test folder to the PIG folder.
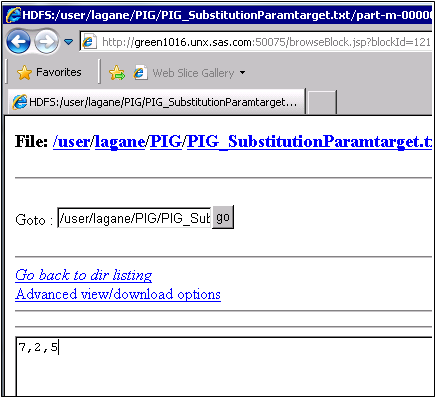
Then click the name of the substitution variable for the job, in this
case PIG_SubstitutionParamtarget.txt. Finally,
click the data file, part-m-00000. Verify
that the expected output, which is
Distributed file
system viewer. Then, click Browse
the filesystem and drill down through the User folder
and the test folder to the PIG folder.
Then click the name of the substitution variable for the job, in this
case PIG_SubstitutionParamtarget.txt. Finally,
click the data file, part-m-00000. Verify
that the expected output, which is
7,2,5,
is displayed in the browser window.
The output for the
sample job is shown in the following display:
Pig Job Output
Copyright © SAS Institute Inc. All Rights Reserved.
Last updated: January 16, 2018