Set Global Options
Overview of the Configuration Window
You can use the Configuration window
to specify server connections, data sources, global options, and other
settings for SAS Data Loader.
To display this window, click the More icon  in the top right corner of SAS Data Loader.
Then select Configuration. See the following
topics for details about the options in each panel of the window.
in the top right corner of SAS Data Loader.
Then select Configuration. See the following
topics for details about the options in each panel of the window.
in the top right corner of SAS Data Loader.
Then select Configuration. See the following
topics for details about the options in each panel of the window.
Hadoop Configuration Panel
SAS Data Loader
enables you to easily access, transform, and manage data stored in
Hadoop. You can use the Hadoop Configuration panel
of the Configuration window to specify a
connection to a Hadoop cluster. You can also use it to change the
default storage locations for various types of files.
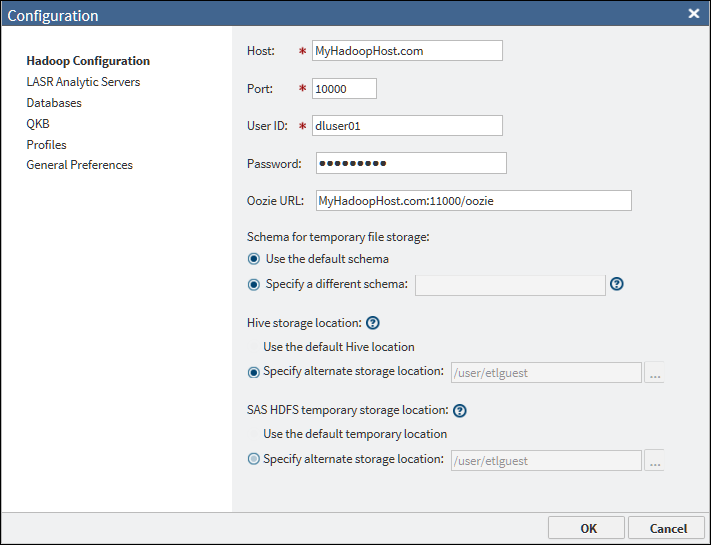
The values for Host, Port, User
ID, Password, and Oozie
URL are entered in the vApp during the initial setup
of SAS Data Loader,
as described in the SAS Data Loader for Hadoop: vApp Deployment Guide. Typically,
you will not change these values except in consultation with your
Hadoop administrator. The default values in the storage location fields
will work in many cases, but you can change one or more of these locations
for your site.
Note: To reconfigure SAS Data Loader
for a different Hadoop cluster, you must copy a new set of configuration
files and JAR files into the shared folder for the vApp. Then you
can update these configuration settings for the new cluster. For
more information about configuring a new version of Hadoop, see SAS Data Loader for Hadoop: vApp Deployment Guide.
The fields in the Hadoop
Configuration panel are as follows:
Host
the fully qualified
host name for HiveServer2 on your Hadoop cluster.
Port
the port number for
HiveServer2 on your Hadoop cluster.
User ID
the name of the user
account that is used to connect to the Hadoop cluster. If this field
is editable, you can specify an ID that is provided by your Hadoop
administrator.
The User
ID is not editable if Kerberos security has been specified
in the vApp, as described in SAS Data Loader for Hadoop: vApp Deployment Guide.
When your cluster uses
a MapR distribution of Hadoop, the User ID field
is populated from a configuration file when you start the vApp. To
change the User ID field, first enter the
new value in the file
vApp-home\shared-folder\hadoop\conf\mapr-users.json.
Next, restart the vApp to read the new value. Finally, open the Hadoop
Configuration panel and enter the new user ID.
Password
the password for the
user account that is used to connect to the Hadoop cluster. If your
system administrator indicates that the cluster uses LDAP authentication,
a password is required. Enter the password that is provided by the
administrator. If the Hadoop cluster does not require a password for
authentication, leave this field blank.
The Password is
not editable if Kerberos security has been specified in the vApp.
Oozie URL
the URL to the Oozie
Web Console, which is an interface to the Oozie server. Oozie is a
workflow scheduler system that is used to manage Hadoop jobs. SAS
Data Loader uses the SQOOP and Oozie components installed with the
Hadoop cluster to move data to and from a DBMS.
-
URL format: http://host_name:port_number/oozie/
-
URL example (using default port number): http://my.example.com:11000/oozie/
Schema for temporary file storage
enables you to specify
an alternative schema in Hive for the temporary files that are generated
by some directives. The default schema for these files is default.
Any alternative schema must exist in Hive.
Hive storage location
enables you to specify
a location on the Hadoop file system to store your content that is
not the default storage location. You must have appropriate permissions
to this location in order to use it. For more information,
see Overriding the Hive Storage Location for Target Tables.
SAS HDFS temporary storage location
enables you to specify
an alternative location on the Hadoop file system to read and write
temporary files when using features specific to SAS. You must have
appropriate permissions to this location in order to use it.
If the default temporary
storage directory for SAS Data Loader is not appropriate for some
reason, you can change that directory. For example, some SAS Data
Loader directives might fail to run if they cannot write to the temporary
directory. If that happens, ask your Hadoop administrator if the sticky
bit has been set on the default temporary directory (typically
/tmp).
If that is the case, specify an alternate location in the SAS
HDFS temporary storage location field. Your Hadoop administrator
will tell you the location of this alternate directory. The administrator
must grant you Read and Write access to this directory.
LASR Analytic Servers Panel
Overview
You can use the Load
Data to LASR directive to copy Hadoop tables to a single SAS LASR
Analytic Server or to a grid of SAS LASR Analytic Servers. On the
SAS LASR Analytic Servers, you can analyze tables using software such
as SAS Visual Analytics.
The Load Data to LASR
directive requires a connection to SAS LASR Analytic Server software.
To load data onto a grid of SAS LASR Analytic Servers, the directive
requires a connection that is optimized for massively parallel processing
(MPP). To load data onto a single SAS LASR Analytic Server, the directive
requires a connection that is optimized for symmetric multi-processing
(SMP). You can use the LASR Analytic Server panel
of the Configuration window to create these
connections.
To add connections for
SAS LASR Analytic Servers:
-
Verify that the appropriate SAS LASR Analytic Server software is available, as described in the general prerequisites below.
-
Display the Hadoop Configuration panel of the Configuration window. If the User ID field is not editable, the Hadoop login for SAS Data Loader has been configured for Kerberos authentication. See the prerequisites below for Kerberos. Otherwise, see the prerequisites below for the case when Kerberos is not used.
-
Use the information above to add a connection to SAS LASR Analytic Server software, as described below.
General Prerequisites for SAS LASR Analytic Server
Ask
your SAS LASR Analytic Server administrator to verify that the following
prerequisites have been met:
-
SAS LASR Analytic Server must be release 2.5 or later. The server must be fully operational and configured to start automatically.
-
SAS Visual Analytics 6.4 or later must be installed and configured on the SAS LASR Analytic Server.
-
SAS LASR Analytic Server must be registered on a SAS Metadata Server.
-
SAS LASR Analytic Server must have memory and disk allocations that are large enough to accept Hadoop tables. Jobs created with the Load Data to LASR directive cannot ensure that sufficient storage is available in SAS LASR Analytic Server.
Additional Prerequisites for Kerberos Authentication
Display the Hadoop Configuration panel of the Configuration window. If the User
ID field is not editable, the Hadoop login for SAS Data Loader
has been configured for Kerberos authentication. The following additional
prerequisites apply.
-
The user ID used to log on to the Hadoop cluster and the user ID used to log on to SAS LASR Analytic Server must be identical. Take note of the User ID that is specified in the Hadoop Configuration panel. Ask the SAS LASR Analytic Server administrator to create an account for that user ID on the SAS LASR Analytic Server.
-
SAS Data Loader, the Hadoop cluster, and the SAS LASR Analytic Server must share a single Kerberos realm. The Kerberos realm for SAS Data Loader and the Hadoop cluster is specified in the SAS Data Loader: Information Center Settings window in the vApp. Ask the SAS LASR Analytic Server administrator to verify that the user ID on the SAS LASR Analytic Server is in the same Kerberos realm.
-
When SAS Data Loader is configured, a Kerberos user ID and realm are entered into the SAS Data Loader: Information Center Settings window in the vApp. When this information is saved, a public key for that user is placed in the shared folder for SAS Data Loader. Ask the SAS LASR Analytic Server administrator to copy this public key to the SAS LASR Analytic Server or to the head node on the SAS LASR Analytic Server grid. The public key must be appended to the authorized keys file in the .ssh directory of that user.
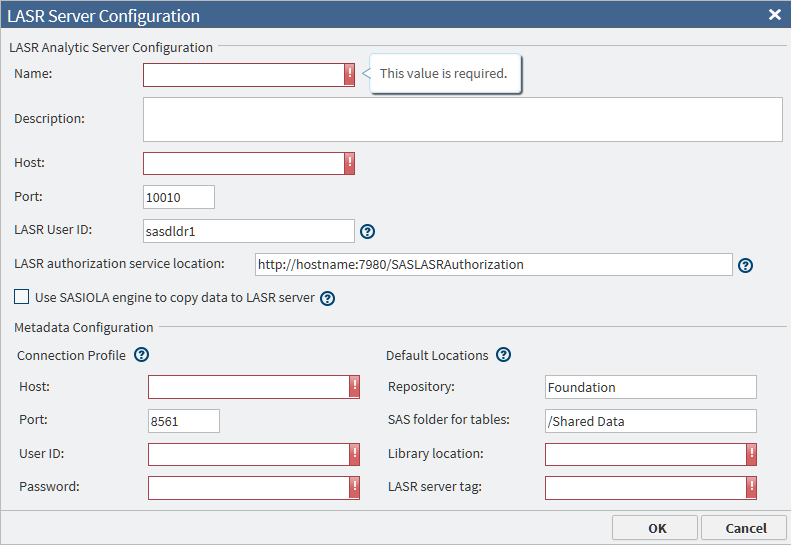
-
Review the fields in the LASR Server of the Configuration window. Ask the SAS LASR Analytic Server administrator to provide the information that is required to specify a connection in this window.
After these prerequisites
have been met, you can add a connection to a SAS LASR Analytic Server. See Add or Update Connections to SAS LASR Analytic Servers.
Additional Prerequisites When Kerberos Authentication Is Not Used
Display the Hadoop Configuration panel of the Configuration window. If the User
ID field is editable, the Hadoop login for SAS Data Loader
has been configured for no authentication or for an authentication
method other than Kerberos. The following additional prerequisites
apply.
-
The user ID used to log on to the Hadoop cluster and the user ID used to log on to SAS LASR Analytic Server must be identical. Take note of the User ID that is specified in the Hadoop Configuration panel. Ask the SAS LASR Analytic Server administrator to create an account for that user ID on the SAS LASR Analytic Server.
-
The user account above must be configured with Secure Shell (SSH) keys on the SAS LASR Analytic Server.
Ask the SAS LASR Analytic
Server administrator to perform these steps:
-
The administrator generates a public key and a private key for the SAS Data Loader user account and installs those keys in SAS LASR Analytic Server, as described in the SAS LASR Analytic Server: Reference Guide.
-
The administrator copies the public key file from SAS Data Loader at
vApp-install-path\vApp-instance\shared–folder \Configuration\sasdemo.pub. A typical path isC:\Program Files\SASDataLoader\dataloader-3p.22on94.1-devel-vmware.vmware (1)\dataloader-3p.22on94.1-devel-vmware\SASWorkspace\Configuration. -
The administrator appends the SAS Data Loader public key to the file
~designated-user-account/.ssh/authorized_keys.If SAS LASR Analytic Server is configured across a grid of hosts, then the public key is appended in the head node of the grid.CAUTION:To maintain access to SAS LASR Analytic Server, you must repeat step 3 each time you replace your installation of SAS Data Loader for Hadoop.Note: It is not necessary to repeat this step if you update your vApp by clicking the Update button in the SAS Data Loader: Information Center.
Review the fields in
the LASR Server of the Configuration window. Ask
the SAS LASR Analytic Server administrator to provide the information
that is required to specify a connection in this window.
After these prerequisites
have been met, you can add a connection to a SAS LASR Analytic Server. See Add or Update Connections to SAS LASR Analytic Servers.
Additional Prerequisites for SSL Connections
If you want SAS Data
Loader to connect to a SAS LASR Analytic Server in a deployment where
the SAS Web Server is secured with Secure Socket Layer (SSL), you
must do the following tasks.
After these prerequisites
have been met, you can add a connection to a SAS LASR Analytic Server,
as described in the next section.
Add or Update Connections to SAS LASR Analytic Servers
After the prerequisites
above have been met, you can add a connection to a SAS LASR Analytic
Server. Perform these steps:
-
If your Hadoop cluster uses Kerberos for authentication, then the value of the LASR User ID field is not used. It is assumed to the same as the User ID that is specified in the Hadoop Configuration panel.If your Hadoop cluster does not use Kerberos for authentication, enter the name of the user account on the SAS LASR Analytic Server that received SSH keys, as described in Additional Prerequisites When Kerberos Authentication Is Not Used. Consult your administrator to confirm whether you should specify a user ID in this field and, if so, which user ID you should use. If no user ID is specified, the user sasdldr1 is used.
-
In the field LASR authorization service location, add or change the HTTP address of the authorization service. You can specify an HTTPS URL if you have done some additional set up. See Additional Prerequisites for SSL Connections.
-
If your SAS LASR Analytic Server is configured to run on a grid of multiple hosts, deselect Use SASIOLA engine to copy data to LASR server. Not selecting this field indicates that massively parallel processing (MPP) will be used in the SAS Data Loader jobs that use this connection.If your SAS LASR Analytic Server supports symmetric multiprocessing (SMP) on a single host, click Use SASIOLA engine to copy data to LASR server.



Databases Panel
Overview
Directives such as Copy
Data to Hadoop and Copy Data from Hadoop require JDBC connections
in order to access tables in databases. The Databases panel
of the Configuration window enables you to
maintain these connections.
To add connections for
databases:
-
Ask your Hadoop administrator to send you a copy of the JDBC drivers that are installed on the Hadoop cluster.
-
Copy these JDBC drivers to the shared folder on the SAS Data Loader host.
-
Contact the administrators of the databases to which you want to connect. Ask for the usual information that is required to connect to a database: host name, port, logon credentials, and so on.
-
Add connections to the databases for which you have JDBC drivers.
Copy JDBC Drivers to the SAS Data Loader Host
SAS Data Loader uses
the SQOOP and Oozie components installed with the Hadoop cluster to
move data to and from a DBMS. SAS Data Loader also accesses the databases
directly, using JDBC to select source or target tables and schemas.
The Hadoop administrator installs appropriate JDBC drivers on the
Hadoop cluster. The SAS Data Loader host must have the same version
of the JDBC drivers in its shared folder.
Follow these steps to
obtain JDBC drivers from the Hadoop administrator and copy them to
the shared folder on the SAS Data Loader host:
-
On the SAS Data Loader host, navigate to the shared folder and open the JDBCDrivers subfolder. Here is a typical path to the JDBCDrivers folder:
C:\Program Files\SAS Data Loader\2.x\SASWorkspace\JDBCDrivers
To verify the path to your shared folder, open the VMware Player Pro window and select Player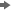 ManageVirtual Machine Settings. In
the Virtual Machine Settings window, click
the Options tab, and then click Shared
Folders (in the Settings list.)
On the right side, the path to the shared folder is provided in the Host
Path column.
ManageVirtual Machine Settings. In
the Virtual Machine Settings window, click
the Options tab, and then click Shared
Folders (in the Settings list.)
On the right side, the path to the shared folder is provided in the Host
Path column.
-
Check the Run Status directive to ensure that all jobs are stopped and saved.In VMware Player Pro, select PlayerPowerRestart Guest. Wait for the
vApp to restart.
Note: Suspending the vApp is not sufficient to detect the new drivers. Restarting is the only way to restart services and ensure that the new drivers are detected.
SAS Data Loader now
has access to these new JDBC drivers. The next task is to add connections
to the databases for which you have new JDBC drivers.
Add Database Connections
After you have copied
the appropriate JDBC drivers into the shared folder on the SAS Data
Loader host, you can add connections to the corresponding databases.
-
The values of Driver class and Connect string are generated automatically when you select either Teradata or Oracle in the Type field. For an Oracle connection that requires a Service ID (SID), enter the SID in the Database name field. If you select Other, you must obtain these values from the JDBC driver provider.
-
If the test fails for a new Oracle connection, then examine the Connect string field. If the string has either of the following formats, then change the string to the other format and test the connection again.
jdbc:oracle:thin:@raintree.us.ourco.com:1521:oadev jdbc:oracle:thin:@raintree.us.ourco.com:1521/oadev
One version uses a final colon character. The other version uses a final slash character.To edit the Connect string field, click Edit .
.


QKB Panel
A SAS Quality Knowledge
Base (QKB) is a collection of files that store data and logic that
define data management operations such as parsing, standardization,
and matching. SAS software products refer to the QKB when performing
data management operations, also referred to as data cleansing, on
your data.
A QKB supports locales
organized by language and country, for example, English, United States;
English, Canada; and French, Canada. The OKB panel
of the Configuration window enables you to
select the default locale used by the transformations in the Cleanse
Data in Hadoop directive. The default locale should match the typical
locale of your source data.
You can override the
default locale in any of the data quality transformations in the Cleanse
Data in Hadoop directive. For more information
about this directive, see Cleanse Data in Hadoop.
Profiles Panel
SAS Data Loader
profile directives enable you to assess the composition, organization,
and quality of tables in Hadoop. For more information
about these directives, see Profile Data in Hadoop.
Data profiling tasks
can be resource intensive. Accordingly, the Profiles panel
of the Configuration window enables you to
change defaults that can improve the performance of new profile jobs.

You can change the following
default options for profiles:
Stop processing a column if the number of unique
values exceeds
stops processing a
column if the number of unique values is greater than the number
that you enter in the field. You can specify a value from 0 to 99999999.
A value of 0 causes every observation in the table to be processed.
Maximum number of frequency distribution values
to save
the maximum number
of frequency distribution values (1–99999999) to save during
the profile run. If there are more frequency distribution values
than this number, the less-frequent values are combined into an Other
frequency distribution.
Number of outlier values to save
the maximum number
of outlier values (1–99999999) to save during the profile run.
Minimize the number of MapReduce jobs created for
a profile run.
limits the number of
parallel processes that are used in a profile job.
Note: This option causes all processing
to be performed by the vApp. For large data tables with many columns,
performance can be affected, even to the point of causing the vApp
to run out of memory. You should specify this setting only if you
know that you have very small data tables.
Number of threads to use for a profile run
the maximum number
of threads (1–99999999) to use for a profile job. If you select
the option to minimize the number of MapReduce jobs for a profile
run, this setting is disabled.
General Preferences Panel
The General
Preferences panel of the Configuration window
enables you to specify various global options for SAS Data Loader.
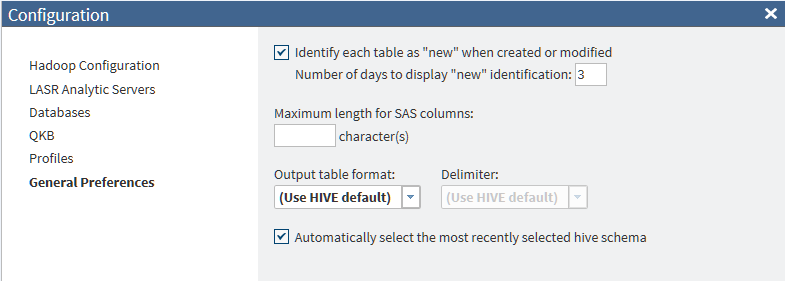
You can change the following
default options:
Identify each table as "new" when created
or modified. Number of days to display "new" identification:
specifies how long
tables are identified as “new” in SAS Data Loader.
Maximum length for SAS columns
specifies a default
length for character columns in input tables for some directives.
The default length of 1024 characters should perform well in most
cases. For more
information, see Change the Maximum Length for SAS Character Columns.
Output table format and Delimiter
specifies the default
file format and delimiter for directive target tables. Use the Output
table format drop-down list to select one of five output
table formats: Hive default, Text, Parquet, ORC, or Sequence. Use
the Delimiter drop-down list to select one
of five output table formats: Hive default, Comma, Tab, Space, or
Other. For more
information, see Change the File Format of Hadoop Target Tables.
Note: If your cluster runs a MapR
distribution of Hadoop, then the Parquet output table format is not
supported.
Automatically select the most recently selected
hive schema
If you frequently work
with the same data source across multiple directives, you can have
SAS Data Loader select the most recently used schema automatically.
This can help you select source tables and target tables more quickly.
Copyright © SAS Institute Inc. All rights reserved.