DataFlux Data Management Studio 2.6: User Guide
This section explains how to use the suggestion-based matching feature to detect data entry errors. The feature is implemented in match definition nodes, which you configure using Customize.
With the DataFlux Data Management Studio suggestion-based matching feature, match definitions have the potential to output multiple matchcodes based on alternative "suggestions" for words. You can specify possible alternatives for words within a token. This addresses such problems as incorrect spelling of a word, typographical errors, or otherwise poor data entry.
The DataFlux Data Management Studio suggestion-based matching feature is implemented using an internal spelling checker mechanism and (optionally) using frequencies of terms that have been obtained from reference sources or through data mining. Potentially misspelled words generate spelling checker–like "suggestions" from a known dictionary. This notion of spelling errors includes character deletions, insertions, replacements, and transpositions. Whitespace insertion, casing, and context-dependent pronunciation can also be taken into account.
Each suggestion includes a score that reflects the closeness of that suggestion to the input word based on the operations that transform the input word to the suggestion, and the cost of these operations. Frequency counts obtained from a reference (or otherwise trusted) dataset then further modify the scores for each suggestion, so that if two suggestions are equally close to the input word, the more frequent suggestion will score higher. The input string is viewed as a potentially corrupted version of the real entity, so the higher the score of a suggestion, the more likely it is to have been "what was really intended."
As with combination-based matching, a single input to a suggestion-based match definition will generally produce multiple output match codes. This means that a given record may appear in more than one potential cluster. In the case of suggestion-based matching, each match code corresponds to a different suggestion or, more typically, to a mixture of suggestions for the individual tokens in the input string.
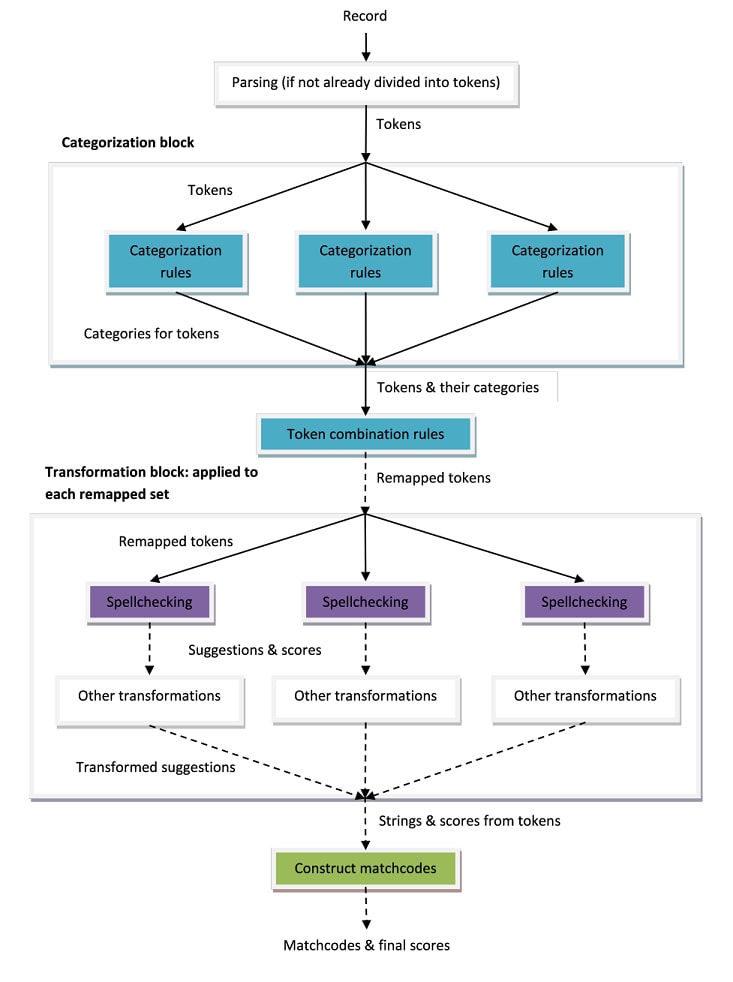
Suggestion-based matching can be used in conjunction with combination-based matching, if desired. The following diagram shows a conceptual overview of the match definition flow when both combination-based matching and suggestion-based matching are used. Note that the required computation and storage resources increase when both types of matching are used.
|
Documentation Feedback: yourturn@sas.com
|
Doc ID: DMCust_SBM.html |