DataFlux Data Management Studio 2.5: User Guide
You can include delimited text files or fixed-width text files as inputs or outputs in data jobs. Add an appropriate node to a data job. Then, you can use it to process your text file data.
You can add a Text File Input node to a data job to use a delimited text file as an input to a data job. Perform the following tasks:
You should examine the structure and content of the text file in a text editor. Be sure to note features such as whether the first line contains headings, whether the file contains text qualifiers, and what delimiters are used.
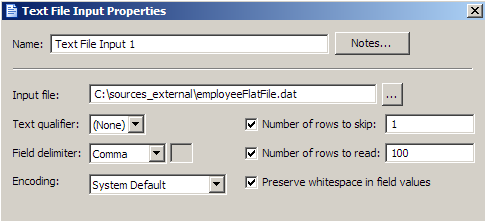
Use the data that you gathered when you reviewed the text file to configure its parameters in the Text File Input Properties dialog. For example, the following display shows the parameter configuration for a text file that does not use a text qualifier and specifies comma as the delimiter.
You can generate a listing of the fields in the text file by clicking Suggest. The sample text file listed the field names in the first line, so click First row contains field names and Guess field types and lengths from file content. The following fields are displayed in the Fields section.
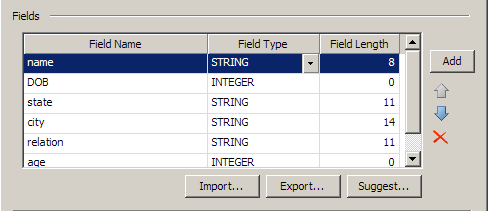
You can make any needed changes to the field names, field types, and field lengths in the text file directly in the Fields section of the dialog. Then, you can click OK to save the properties for the file.
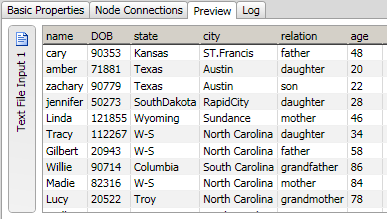
You can easily preview the text file input that you added to the data job. Right-click the Text File Input node and click Preview in the pop-up menu. A preview is provided in the Details pane, as shown in the following display.
You can add a Fixed Width Input node to a data job to use a fixed-width text file as an input to a data job. Perform the following tasks:
You should examine the structure and content of the fixed-width file in a text editor. Be sure to note features such as whether the first line contains headings, the length of the longest records, and which encoding is used.
Use the data that you gathered when you reviewed the text file to configure its parameters in the Text File Input Properties dialog. For example, the following display shows the parameter configuration for a fixed-width file that uses the system default encoding.

you will establish the record length when you define the column widths.
You can begin the column-definition process by clicking Advanced. You will see a calculated record length in the Record Length dialog because you kept the default record length of 0 in the configuration task. Click OK to accept the calculation and access the Column Selection dialog, as shown in the following display.
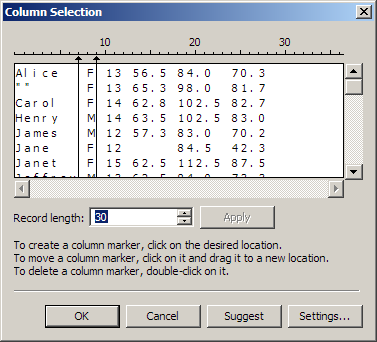
Note that the first and second column markers have been created by clicking on the appropriate positions on the ruler above the list of rows. The following display shows the columns after they have been named and identified by type.
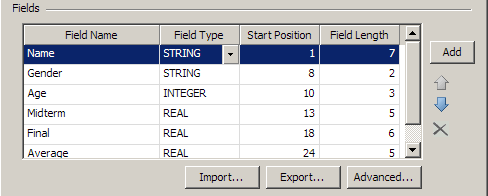
You can make any needed changes to the field names, field types, start positions, and field lengths in the fixed-width file directly in the Fields section of the dialog. Then, you can click OK to save the properties for the file.
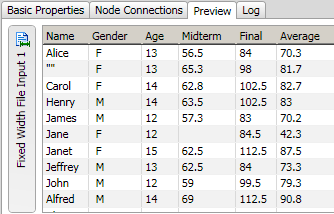
You can easily preview the text file that you added to the data job. Right-click the Text File Input node and click Preview in the pop-up menu. A preview is provided in the Details pane, as shown in the following display.
You can add a Text File Input node to a data job to add a flat file from a mainframe environment as an input to a data job. Then, you can use a COBOL copybook file, a COBOL layout file, or a copybook job file to read in the data from the mainframe data file. Perform the following tasks:
You must specify a copybook source before you can use the contents of a mainframe flat file as an input to a data job. Copybook source files come in the following types, which you specify in the Copybook type field:
The copybook configuration for a sample flow is shown in the following display.
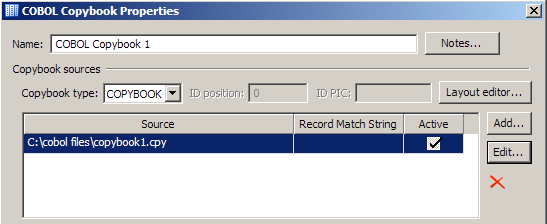
Note that you can store more than one copybook source in a single COBOL Copybook node. You must then specify the record match string for the active copybook. You can set this value when you add a copybook or when you edit an existing copybook. Only one copybook can be active at a time.
You select and configure the data file that you want to process in the Data file group box. The path to a sample file and its data format are shown in the following display.

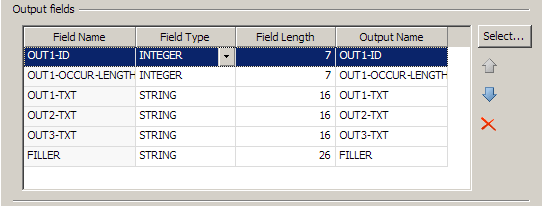
You can click Select in the Output Fields group box to access the Select Output fields dialog. The following display shows that all of the available fields in the sample file are selected.
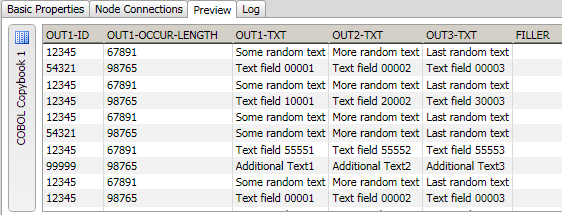
You can easily preview the text file input that you added to the data job. Right-click the COBOL Copybook node and click Preview in the pop-up menu. A preview is provided in the Details pane, as shown in the following display.
You can connect a Text File Output node to the final node in a data job to create a plain text output file to hold the results of a data job. Perform the following tasks:
You can configure the output parameters for the text file in the Text File Output Properties dialog. For example, the following display shows the parameter configuration for a text file that does not use a text qualifier and specifies comma as the delimiter.
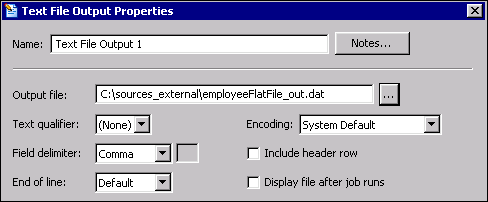
Note that the name and path of the output file are also specified.
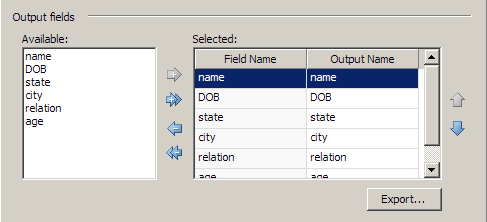
The available output fields are determined by the data that flows into the Text File Output node. In the example depicted in the display below, all of the fields are moved to the Selected field.
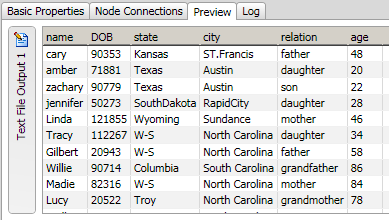
You can easily preview the text file output that you added to the data job. Right-click the Text File Output node and click Preview in the pop-up menu. A preview is provided in the Details pane, as shown in the following display.
You can add a Fixed Width Output node to the final node in a data job to create a fixed-width output file to hold the results of a data job. Perform the following tasks:
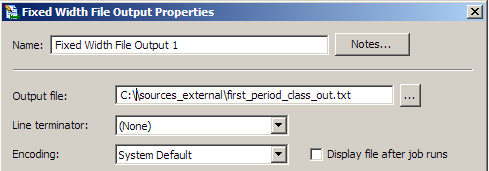
You can configure the output parameters for the fixed-width file in the Text File Input Properties dialog. For example, the following display shows that the output file is specified and the default encoding is used for a sample file.
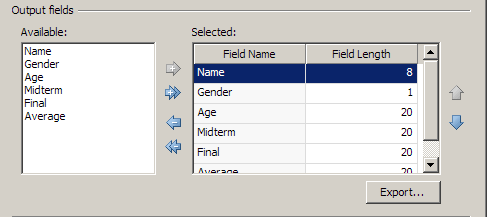
The available output fields are determined by the data that flows into the Fixed Width File Output node. In the example depicted in the display below, all of the Available fields are moved to the Selected field.
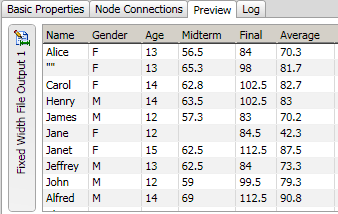
You can easily preview the fixed-width file output that you added to the data job. Right-click Fixed Width File Output node and click Preview in the pop-up menu. A preview is provided in the Details pane, as shown in the following display.
|
Documentation Feedback: yourturn@sas.com
|
Doc ID: dfU_T_DataJob_Text.html |