DataFlux Data Management Studio 2.5: User Guide
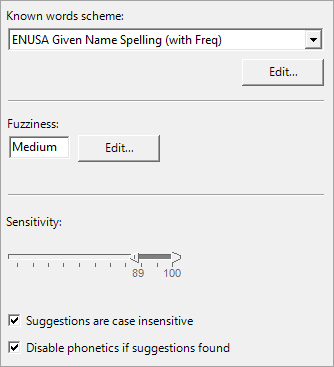
The Suggestions node for each token is where the suggestion-based matching mechanism is configured for that token. Each token can have only one Suggestions node. The properties dialog for a Suggestions node is shown in the following display.
The known words scheme must be specified, and the file should be in the following format:
When manually creating a known words scheme, the source used to create the vocabulary used by the corresponding parse definition could also provide words for the scheme. However, this scheme is specific to the token in which the Suggestions node is contained, so its contents should be limited to only words that could appear in that particular token.
Each Suggestions node has three fuzziness levels (High, Medium and Low), which each encompass a set of values for many individual configuration parameters. In definitions shipped by DataFlux in a QKB release, the values underlying these levels are obtained through extensive experimentation with test data appropriate to the particular data type. The High level provides the highest accuracy, while the Low level requires the least computation time. The Medium level is a reasonable compromise.
In new user-created definitions, these three preset levels are populated with default values as a convenient starting point. These settings are not guaranteed to perform well, or even sensibly, for arbitrary data. For better results, it may be necessary to configure the individual parameters.
To access the individual configuration parameters, click the Edit button. For more information, see Suggestions Node Advanced Configuration (Fuzziness Settings). If any of the individual parameters are edited, the changes are saved under a Custom fuzziness level.
As with other nodes in the match definition, the Sensitivity slider selects the sensitivity range for which the Suggestions node will have an effect.
If the Suggestions are case insensitive check box is selected, the incoming token will be uppercased at the input to the Suggestions node.
If the Disable phonetics if suggestions found check box is selected, the Phonetics Libraries further down in the match definition flow will not take effect whenever there is at least one suggestion output by the Suggestions node (other than the input token itself). This is useful when converting an existing match definition that uses Phonetics Libraries because those phonetics rules tend to overly reduce the string.
The individual configuration parameters for a Suggestions node can be adjusted in its advanced configuration dialog, shown in the following display.
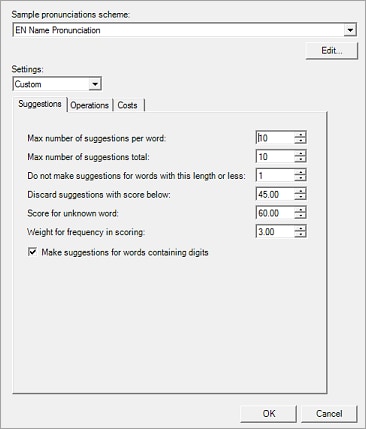
The sample pronunciations scheme is used to define the pronunciation of some words so that suggestions can be generated with phonetically equivalent characters. This is optional, but if a scheme is specified, it must be in a specific format and should not be indiscriminately edited. For more information, see Editing the Sample Pronunciations Scheme in the Scheme Builder.
![]() Note: If no sample pronunciations scheme is specified, phonetic equivalences will not be used.
Note: If no sample pronunciations scheme is specified, phonetic equivalences will not be used.
The Settings drop-down list contains the preset fuzziness levels (High, Medium, Low, and Custom, if it exists). Changing this selection will set the active preset level (the level that will be used when the definition is run). When the fuzziness level is changed, all the individual parameters corresponding to that level are shown on the Suggestions, Operations, and Costs tabs below the list.
Initially, the Custom fuzziness level does not exist. It is created and made active if any of the parameters on the Suggestions, Operations, and Costs tabs are changed.
The Suggestions tab contains general parameters pertaining to the suggestions that will be generated for the currently selected preset level.
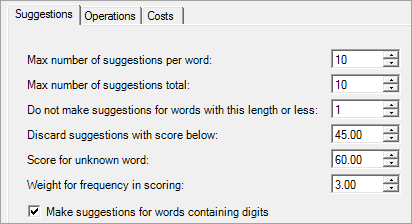
No more than this number of suggestions will be generated for each word in the token. For example, if the token contains two words ("OCEAN VIEW"), up to two suggestions might be generated for "OCEAN", and two suggestions for "VIEW". Thus, up to four potential suggestions might be generated for the entire token.
No more than this number of suggestions will be generated for the entire token. For example, if the token contains two words ("OCEAN VIEW"), even if each word could produce two suggestions (resulting in four potential combined suggestions), a maximum of the two top-scoring combined suggestions will be shown.
Because it is often not useful to generate suggestions for very short words, they can be excluded from the spelling checker mechanism. For example, if this parameter is set to 1 or greater, the word "A" will not generate any suggestions other than "A" itself. If this parameter is set to zero, the word "A" could generate "B", "C", "D", and so on.
This parameter is a threshold that allows suggestions (for the token) that have low scores to be discarded and not pass through the rest of the token processing. This threshold will be applied even if the maximum number of suggestions for the token has not been exceeded. For example, if this parameter is set to 80.00 and the potential suggestions have scores 100.00, 80.00, and 79.00, only the first two suggestions will be shown.
If an input word does not exist in the Known words scheme, this is the score that is assigned to it by the spelling checker mechanism. The input word itself is always output as a suggestion, regardless of what other suggestions are generated.
This parameter controls the contribution of frequency to the score. If this parameter is set to zero, frequency does not affect the score. If the weight is non-zero, more frequent terms ("SMITH") will score higher than less-frequent terms ("SMOTH") even if they are equally close to the input ("SMKTH"). The effect of frequency is not linear. Doubling this weight will have very little effect on the score of terms with low frequencies, and will only approach double the effect on the score for terms with very high frequencies.
This parameter determines whether words containing digits (for example, "Win7") are exempted from the spelling checker mechanism.
The parameters on the Operations tab control the types of operations that are allowed in the spelling checker for the selected preset level.
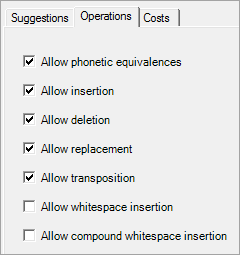
This operation occurs when a character is phonetically equivalent in the input and in the suggestion. Phonetic equivalence is contextual—that is, a character can be pronounced differently depending on what word it is in.
As long as the sample pronunciations scheme contains words containing the relevant characters, the spelling checker automatically creates equivalence classes for the set of all vowels and some sets of consonants. For example, input "VERDENT" with suggestion "VERDANT" could contain a phonetic equivalence operation because of the automatic phonetic equivalence of vowels.
This operation occurs when a character is added to the input word. For example, insertion could lead to the suggestion "JOAN" for input "JON".
This operation occurs when a character is removed from the input word. For example, deletion could lead to the suggestion "JON" for input "JOAN".
This operation occurs when a character in the input word is replaced by another character. For example, replacement could lead to the suggestion "JOHN" for input "JOAN".
This operation occurs when two adjacent characters switch positions. For example, transposition could lead to the suggestion "JON" for input "JNO".
This operation occurs when a whitespace character is inserted in the input word to make two words. For example, if the Known words scheme contains the two words "MARY" and "ANN", whitespace insertion could lead to the suggestion "MARY ANN" for input "MARYANN".
This operation occurs when a whitespace character is inserted in the input word to make two words that form a known compound. For example, if the Known words scheme contains the compound "MARY ANN", whitespace insertion could lead to the suggestion "MARY ANN" for input "MARYANN".
The Costs tab contains numeric parameters that control the costs of operations and the search strategy by which suggestions are constructed.
As a general guideline, the cost of a particular operation should be set lower for common operations—that is, if the type of error associated with that operation is more commonly encountered in the data. The cost of an operation should also be lower if (for some reason) it is considered more important for that type of error to be caught.
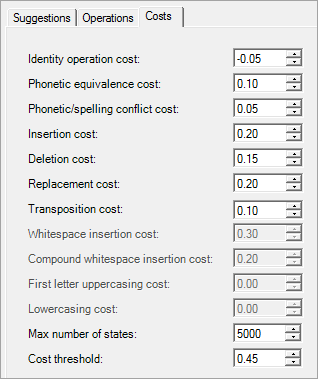
This parameter controls the cost of the operation where the same character is used in both the suggestion and the input word. Generally, the cost should be set to a non-positive quantity. For example, input "ANDY" with suggestion "ANDY" consists of four identity operations. If this operation's cost is -0.05, the total cost is -0.20.
This parameter controls the cost of the operation where a phonetically equivalent character is substituted. For example, input "VERDENT" with suggestion "VERDANT" contains one phonetic equivalence operation (vowel equivalence). If this operation's cost is 0.10 and the identity cost is -0.05, total cost is 6*-0.05 + 0.10 = -0.20.
This parameter controls the cost of the operation where the character is the same, but is pronounced differently in the input word and the suggestion. For example, consider the Spanish-origin name "JOSE", which is pronounced like "ho-zay" in English, compared to the English name "JOE", which is pronounced like "jo". Although both words contain "J" and "E", the pronunciation of those letters differs in the two words. Assume that the sample pronunciations scheme contains an entry for both these words (or similar words that contain these sounds). Further assume that the only allowed operations are identity, deletion and phonetic equivalence. For input "JOSE", there could be a suggestion "JOE", with a score resulting from one identity operation ("O"), one deletion ("S") and two phonetic/spelling conflicts ("J" and "E").
This parameter controls the cost of the insertion operation.
This parameter controls the cost of the deletion operation.
This parameter controls the cost of the replacement operation.
This parameter controls the cost of the transposition operation. This cost is applied once for the pair of transposed characters, and neither transposed character has an identity cost applied. For example, input "JNO" with suggestion "JON" contains one identity operation and one transposition operation.
This parameter controls the cost of the whitespace insertion operation.
This parameter controls the cost of the compound whitespace insertion operation.
This parameter controls the cost of changing the first letter of the input word to uppercase. This parameter is not available if the Suggestions are case insensitive option was selected in the Suggestions node properties.
This parameter controls the cost of changing an entire uppercased input word to lowercase. For this cost to be applied, the suggestion must be listed in the Known words scheme in lowercase. This parameter is not available if the Suggestions are case insensitive option was selected in the Suggestions node properties.
![]() Note: This applies to an input word that is entirely in uppercase. If only some of the letters in the input word are uppercased, they are treated as individual replacements.
Note: This applies to an input word that is entirely in uppercase. If only some of the letters in the input word are uppercased, they are treated as individual replacements.
This parameter controls the breadth of searches in the state graph. The graph is made up of all possible transitions between characters found in words (including lowercase and uppercase). After this number of states has been checked, the search will end and will return the complete suggestions that have been found before that point. Thus, the larger this setting (relative to the number of states generated from all the terms in the Known words scheme and the input string), the more suggestions are likely to be found. Also see the following discussion of the Cost threshold parameter.
A running cost total is kept along every search path traversed in the state graph. If, at any time, a certain path exceeds this threshold, that path is abandoned. For example, assume that the insertion cost is set to 0.4, the identity cost is -0.05, and the cost threshold is 0.25. If the input is "BRTHOLOMEW", the running cost at the insertion of "A" is -0.05 + 0.4 = 0.35, which is greater than the threshold. Although the final cost of the suggestion "BARTHOLOMEW" would in theory pass the threshold (because there are nine other identical characters toward the end of the word, giving a final total cost of 10*-0.05 + 0.4 = -0.1), the current running cost total at that state does not pass the threshold. Therefore, that suggestion's path is abandoned. The Cost threshold parameter, together with the Max number of states, is the main determiner of the computation time needed for the spelling checker.
The following display shows the output of the Suggestions node in Customize (assuming no token combination rules). The rule-weighted score is the score after applying the weight of the applicable token combination rule, if combination-based matching is also in use. (If token combination rules are not in use, the rule-weighted score is the same as the raw score.) The rule-weighted score is then passed down into the rest of the token processing, and will eventually be used with the other tokens' scores when the complete match codes are assembled.
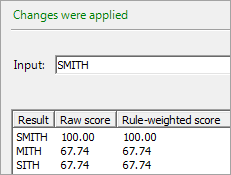
![]() Note: If token combination rules are in use, you can view the output for a rule by selecting the rule in the rule selector drop-down list in the Test Window.
Note: If token combination rules are in use, you can view the output for a rule by selecting the rule in the rule selector drop-down list in the Test Window.
If the match definition option Weight scores by sensitivity is enabled, all rule-weighted scores are further modified by the current sensitivity setting.
|
Documentation Feedback: yourturn@sas.com
|
Doc ID: dfDMStd_SBM_Customize_SuggestionsNode.html |