DataFlux Data Management Studio 2.5: User Guide
In Customize, two new groups of nodes have been added to the match definition to support combination-based matching functionality: the Morph Analysis group and the Token Combination Rule (TCR) group. The Match Score Threshold node, added to support suggestion-based matching, is also useful in combination-based matching. A match definition is considered "combination-based" if the TCR placeholder group contains a TCR node. A newly-created match definition will have an empty TCR group. It is therefore still possible to create legacy match definitions, simply by not inserting any TCR nodes.
In this document, a simple definition, designed to tackle the easily-understood family name/given name transposition problem, will be used for illustration. In the following examples, the existing Name match definition is used as a starting point to which the trappings of combination-based matching are then added. Advanced users may wish to examine the Address (Full) (with Combinations) match definition in the English (United Kingdom) locale, which illustrates the handling of a far more complex problem.
Each token has a Morph Analysis group which is precisely analogous to the correspondingly-named group in a Parse definition. The purpose of this group is to assign categories to the incoming tokens; a token may be assigned zero or more categories, together with likelihoods for each of those categories. It is necessary to configure Morph Analysis groups only for those tokens that are used in the conditions of TCR nodes.
![]() Note: More information on the Morph Analysis group and the nodes contained therein, including their properties sheets and testing outputs, can be found in the Customize documentation for the Parse definition.
Note: More information on the Morph Analysis group and the nodes contained therein, including their properties sheets and testing outputs, can be found in the Customize documentation for the Parse definition.
To set up Morph Analysis, consider what conditions are necessary for the ambiguity to occur: the transposition of names must be plausible (as in the example of "JOHN ELTON" and "ELTON JOHN"). Though, in principle, there is no limitation on what words could conceivably be used as either given or family names, the probability that a particular name is transposed does increase when the words concerned are commonly used as both given and family names. For simplicity, the examples shown here will assume that there is a fixed, known group of words that can be used as both given and family names. This will allow the problem to be addressed using a single TCR node.
![]() Note: Here it is assumed that all the words in the vocabulary are equally likely to be present as family or given names. However some words are more likely to be used as family names than as given names, or vice versa. Multiple TCR nodes could be used to handle the differing likelihoods; less-likely transpositions could be given a lower rule weight.
Note: Here it is assumed that all the words in the vocabulary are equally likely to be present as family or given names. However some words are more likely to be used as family names than as given names, or vice versa. Multiple TCR nodes could be used to handle the differing likelihoods; less-likely transpositions could be given a lower rule weight.
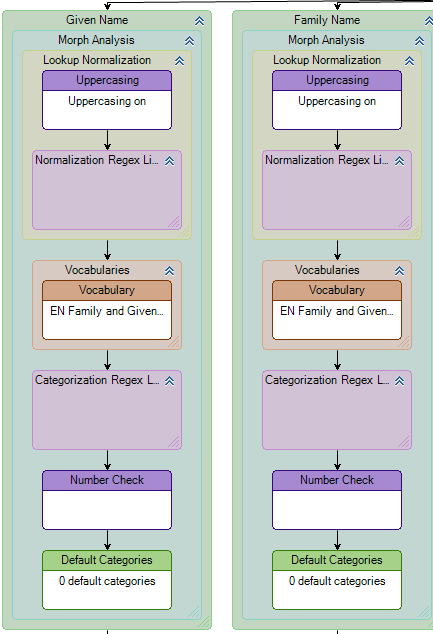
The only configuration now necessary in the Morph Analysis group is to insert a Vocabulary node into the group for both Given Name and Family Name tokens.
The following diagram shows the top of a match definition flow in Customize, showing Morph Analysis groups configured for two tokens:
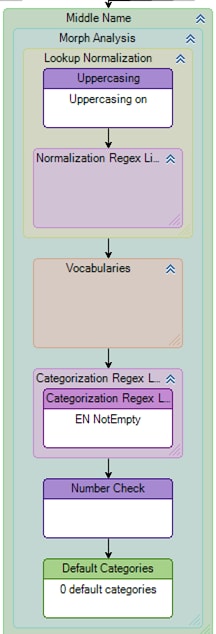
Additional complexity can be added to handle more realistic situations. For example, the input "ELTON A JOHN" strongly suggests that "ELTON" is the given name and "JOHN" the family name, because of the existence of the middle initial; in this case, transposition of family and given names is probably not desirable. To implement this, an additional category can be added to the vocabulary to describe a token that is not empty. A Categorization Regex node can then tag the Middle Name token whenever it is non-empty.
The following diagram shows the Morph Analysis group for the Middle Name token, showing a Categorization Regexlib node:
With the Vocabulary node configured as described above, a category will be assigned to the Given Name token if one or more of its words is present in the vocabulary. Otherwise, no category will be assigned. The same sort of result is produced for the Family Name token.
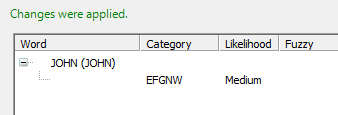
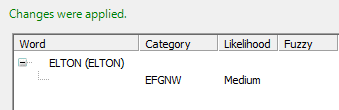
The next two figures show the test output of the Morph Analysis group when the input string contains only words that are present in the vocabulary. In this example, the input string is "JOHN ELTON". The desired category has been arbitrarily named EFGNW (standing for Either Family or Given Name Word).
This example shows the test output for Given Name token's Morph Analysis group with input string "JOHN ELTON". Both words were present in vocabulary.
This example shows the test output for Family Name token's Morph Analysis group with input string "JOHN ELTON". Both words were present in vocabulary.
Conversely, this example shows the test output of the Morph Analysis group for a word that is not in the vocabulary. Here, no category is assigned.
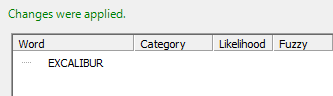
This example shows the effect of the categorization regexlib in the Middle Name token. When the token is non-empty, the category NEMP (standing for Not Empty) is assigned.
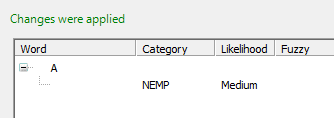
This example shows the result when the token is empty and no category is assigned.
The TCR node specifies the conditions under which the rule should take effect, as well as the desired effect of the rule. Each node describes a single rule and will be responsible for producing one matchcode (if the rule's conditions are satisfied).
The properties sheet for a TCR node is shown in the following figure. Here, the rule is configured to use the categories previously assigned by the Morph Analysis groups. There are three conditions; these specify that the rule is only applied when the Family and Given Name tokens both have the category EFGNW, and the Middle Name token does not have the category NEMP.
When all these conditions are satisfied, the Family and Given Name tokens will be transposed. The rule will be evaluated at all sensitivities (50 - 100) and the output of the rule will be assigned a weight of 80.
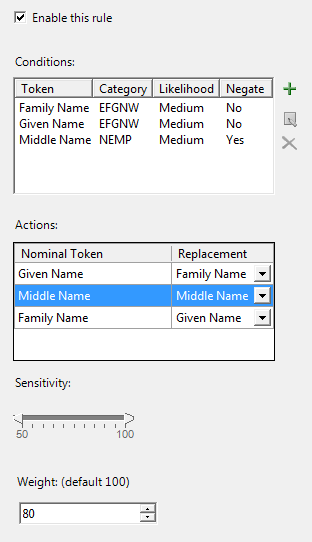
Check this box to enable the rule. By default, this box is checked; it is provided as a convenience to users who may want to selectively enable and disable certain rules while developing or debugging a new match definition.
Each row of this grid specifies a single condition. All conditions must be satisfied for the rule to be applied. The Token column contains the name of the incoming token that should be examined. The Category and Likelihood columns contain, respectively, the name of the category that the incoming token must be assigned, and the minimum likelihood that must be associated with that assignment. The value in the Negate column should be set to "Yes" if the condition must be negated—this is sometimes useful when it is easier to express the opposite of a desired condition using categories. By default, the grid is empty, meaning that no conditions need be satisfied for the rule to be applied.
An action is the mapping of an incoming token to the effective token that will be used in the matchcode generation processing steps. The available incoming tokens are listed in the Nominal Token column. Each incoming token may be replaced by another token, as specified in the Replacement column. By default, no Replacement tokens are assigned when the node is first created; leaving a token with no replacement will cause that token to be replaced by a blank string (i.e. omitted).
As with other nodes in the match definition, the sensitivity slider selects the range of sensitivities within which the node will take effect. This defaults to the entire range of sensitivities.
This specifies a weight that will be associated with the rule, and defaults to 100. The weight is used to generate a score for each matchcode arising from this rule.
The output of the TCR node indicates whether the conditions have been satisfied for the given input; if so, the rule will be applied. The next two figures show the possible test outputs for the TCR node.
Output of the TCR node in Customize (if the conditions are satisfied):
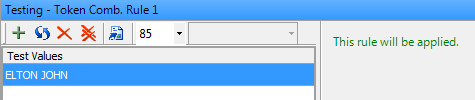
Output of the TCR node in Customize (if the conditions are not satisfied):

The properties sheet for the TCR group is shown below. These properties concern the handling of the "default rule"—the identity mapping of all incoming tokens to themselves, without condition. The default rule is defined implicitly and does not take up a TCR node; unless otherwise specified in these properties, this default rule is always evaluated with a weight of 100.
Users may wish to disable the default rule when the "default" case—the case where all defined tokens are present in their natural state—is not one that can reasonably occur. This can happen, for example, when all possible combinations are already covered by the user-defined TCR nodes.
![]() Note: For an advanced use case, see the Address (Full) (with Combinations) match definition in English (United Kingdom).
Note: For an advanced use case, see the Address (Full) (with Combinations) match definition in English (United Kingdom).
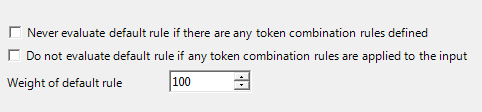
Never evaluate default rule if there are any token combination rules defined - If this box is checked, inserting any TCR nodes into the group causes the default rule to be disabled.
Do not evaluate default rule if any token combination rules are applied to the input - If this box is checked, the default rule will not be evaluated if at least one TCR node has its conditions satisfied.
Weight of default rule - This specifies the weight that should be assigned to the default rule.
The output for the Token Combination Rule (TCR) group indicates whether any of the rules in the group will be applied. It also informs the user if the default combination (the combination where all tokens are mapped to themselves) will be evaluated. The possible test outputs for the TCR group include:
| Output | Description |
|---|---|
| One or more rules will be applied. The default token combination will be evaluated. | Output of the TCR group in Customize if at least one rule has its conditions satisfied and the default rule is enabled |
| No rules will be applied. The default token combination will be evaluated. | Output of the TCR group in Customize if no rules have their conditions satisfied and the default rule is enabled |
| No rules will be applied. The default token combination will not be evaluated. | Output of the TCR group in Customize if no rules have their conditions satisfied and the default rule is disabled |
| One or more rules will be applied. The default token combination will not be evaluated. | Output of the TCR group if at least one rule has its conditions satisfied and the default rule is disabled |
The Match Score Threshold node has only one parameter, the Minimum Score Threshold. This threshold value is applied to the combined score for the entire matchcode as laid out in the Matchcode Layout node. Any matchcodes that have scores below this value are discarded.
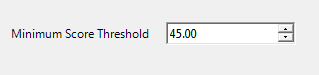
The threshold value should be set to limit the output of the match definition to some reasonable number of matchcodes for the typical input string. Since very low scoring matchcodes are likely to be ignored during entity resolution anyway, discarding them at this stage will save resources when the match definition is run in a data job.
The test window output of the Match Score Threshold node is very similar to that of the Matchcode Layout node. The matchcodes are shown prior to obfuscation, together with their scores and the token combination rule from which each arose. If there were duplicate matchcodes generated (i.e. the same matchcode arising from several token combination rules), this is also indicated. Only those matchcodes which passed the threshold are shown.
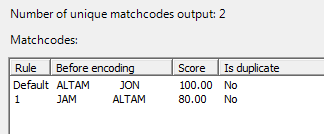
Assuming that suggestion-based matching is not used, the score for each matchcode is, by default, the weight of the rule that produced it. If suggestion-based matching is in use, then this score also includes a contribution from the score produced at the Suggestions node. (Note that the final score is the suggestion's score multiplied by the rule weight, and divided by 100.) In addition, if the match definition option Weight scores by sensitivity is enabled, then the rule weights are further modified by the current sensitivity setting. (Note that the score due to suggestion and/or combinations is multiplied by the current sensitivity setting and divided by 100.)
|
Documentation Feedback: yourturn@sas.com
|
Doc ID: dfDMStd_CBM_working.html |