“二元 Logistic 回归”任务


向角色分配数据
要运行二元 Logistic 回归任务,您必须将列分配至响应变量,并将一列分配至分类变量角色或连续变量角色。
|
角色
|
说明
|
|---|---|
|
角色
|
|
|
响应
|
|
|
响应数据由若干事件和试验组成
|
指定响应数据是否由事件和试验组成。
|
|
事件数
|
指定包含每个观测的事件数的变量。
|
|
试验数
|
指定包含每个观测的试验数的变量。
|
|
响应
|
指定包含响应数据的变量。要执行二元 logistic 回归,响应变量应该仅包括两个水平。
使用感兴趣的事件下拉列表选择二元响应模型的事件类别。
|
|
关联函数
|
指定将响应概率与线性预测变量相关联的关联函数。
下面是有效值:
|
|
解释变量
|
|
|
分类变量
|
指定要在分析中使用的分类变量。分类变量是指通过水平(而不是值)进入统计分析或统计模型的变量。将变量值与水平相关联的过程称为水平化。
|
|
效应参数化
|
|
|
编码
|
指定分类变量的参数化方法。设计矩阵列根据选定编码模式从分类变量中创建。
您可以从以下编码模式中选择:
|
|
缺失值的处理
|
|
|
如果满足以下任一条件,则观测会从分析中排除:
|
|
|
连续变量
|
指定在分析中用作解释变量的连续变量。
|
|
其他角色
|
|
|
频数计数
|
指定包含每个观测的发生频数的变量。该任务处理每个观测时,如同观测已出现 n 次一样,其中 n 是该观测的变量值。
|
|
权重变量
|
指定每个观测在输入数据集中的权重。
|
|
分析分组依据
|
根据 BY 变量的数量创建单独分析。
|
指定模型选择选项
|
选项
|
说明
|
|---|---|
|
模型选择
|
|
|
选择方法
|
指定模型的模型选择方法。该任务将通过检查是应根据选择方法所定义的规则将效应添加到模型还是从模型删除进而执行模型选择。
下面是选择方法的有效值:
|
|
选择方法(续)
|
|
|
详细信息
|
|
|
显示选择过程详细信息
|
指定要包括在结果中的关于选择过程的信息量。您可以选择显示汇总、选择过程每个步骤的详细信息,或关于选择过程的全部信息。
|
|
维护效应层次
|
指定模型层次要求的应用方式以及每次仅单一效应或多个效应可以进入或离开模型。例如,假设您在模型中指定主效应 A 和 B 与交互效应 A*B。在选择过程的第一步中,A
或 B 其中一个进入模型。在第二步中,另一个主效应进入模型。仅当两个主效应均已进入模型后,交互效应才可以进入模型。而且,从模型中删除 A 或 B 之前,必须先删除
A*B 交互。
模型层次指以下要求:对于任意将进入模型的项,项中所包含的所有效应必须呈现在模型中。例如,若交互 A*B 要进入模型,则主效应 A 和 B 必须在模型中。同样,当交互
A*B 在模型中时,效应 A 和 B 都无法离开模型。
|
设置选项
|
选项名称
|
说明
|
|---|---|
|
统计量
注: 除了可以在结果中包括默认统计量,您还可以选择添加其他统计量。
|
|
|
分类表
|
根据预测事件概率是高于还是低于范围中的分界值 z 对输入二元响应观测进行分类。若预测事件概率等于或超过 z,则观测作为事件预测。
|
|
偏相关
|
计算偏相关统计量
 (针对每个参数 i),其中 X2i 是指参数的 Wald 卡方统计量,log L0 是指仅限截距模型的对数似然 (Hilbe 2009)。如果 X2i < 2,则偏相关设置为 0。 (针对每个参数 i),其中 X2i 是指参数的 Wald 卡方统计量,log L0 是指仅限截距模型的对数似然 (Hilbe 2009)。如果 X2i < 2,则偏相关设置为 0。
|
|
广义 R 方
|
请求拟合模型的广义 R 方测度。
|
|
拟合优度和过度分散
|
|
|
偏差和 Pearson 拟合优度
|
指定是否计算偏差和 Pearson 拟合优度。
|
|
聚合依据
|
指定计算 Pearson 卡方检验统计量和似然比卡方检验统计量(偏差)的子总体。给定变量列表中具有公共值的观测视为来自相同的子总体。列表中的变量可以是输入数据集中的任何变量。
|
|
过度分散校正
|
指定是否通过使用偏差或 Pearson 估计来校正过度分散。
|
|
Hosmer-Lemeshow 拟合优度
|
对二元响应模型的情况执行 Hosmer-Lemeshow 拟合优度检验(Hosmer-Lemeshow 2000)。基于估计概率的百分位数将主题大约分为相同大小的
10 组。这些组中观测的观测数和期望数之间的差异由 Pearson 卡方统计量进行汇总。然后该统计量与自由度为 t 的卡方分布进行比较,其中 t 为组数减去 n。默认情况下,n = 2。p 值较小意味着拟合模型并非适当模型。
|
|
多重比较
|
|
|
执行多重比较
|
指定是否计算并比较固定效应的最小二乘均值。
|
|
选择要检验的效应
|
指定您要比较的效应。在模型选项卡上指定这些效应。
|
|
方法
|
请求 p 值的多个比较调整和最小二乘均值差的置信限。以下是有效方法:Bonferroni、Nelson、Scheffé、Sidak 和 Tukey。
|
|
显著性水平
|
请求对每个置信水平为 1 – number 的最小二乘均值构造 t 类型置信区间。number 的值必须介于 0 到 1 之间。默认值为 0.05。
|
|
精确检验
|
|
|
截距的精确检验
|
计算截距的精确检验。
|
|
选择要检验的效应
|
计算选定效应的参数的精确检验。
|
|
显著性水平
|
指定显著性水平
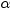 (针对参数或优比的 (针对参数或优比的 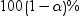 置信限)。 置信限)。
|
|
参数估计
|
|
|
您可以计算下面这些参数估计:
您可以指定参数的置信区间、优比的置信区间以及这些估计的置信水平。
|
|
|
诊断
|
|
|
影响诊断
|
显示用于标识影响观测的诊断测度。每个观测的结果包括观测的序号、最终模型中包括的解释变量值和 Pregibon 提出的回归诊断测度(1981)。您可以指定是否在结果中包括标准和似然残差。
|
|
图
|
|
|
您可选择是否在结果中包括图。
下面是您可以在结果中包括的其他图:
您可以指定是在面板中显示这些图还是单独显示这些图。
|
|
|
标签影响和 ROC 图
|
指定包含影响标签和 ROC 图的输入数据中的变量。
|
|
最大图点数
|
指定可以在图中包括的点数上限。系统默认显示 5,000 点。
|
|
方法
|
|
|
优化
|
|
|
方法
|
指定估计回归参数的优化方法。Fisher 评分和 Newton-Raphson 算法得到相同的估计,但是除为二元响应数据指定 Logit 关联函数外,估计的协方差矩阵略微不同。
|
|
最大迭代数
|
指定要执行的最大迭代数。若未达到指定迭代数量中的收敛,则显示的输出和所有由任务创建的输出数据集都将包含基于最后的最大似然迭代的结果。
|
创建输出数据集
|
选项名称
|
说明
|
|---|---|
|
输出数据集
|
|
|
您可创建两类输出数据集。选中要创建的各个数据集所对应的复选框。
创建输出数据集
输出包含指定统计量的数据集。
下面是您可以在输出数据集中包含的统计量:
创建评分数据集
输出包含输出数据集中所有统计量以及后验概率的数据集。
|
|
|
将 SAS 评分代码添加到日志
|
将计算拟合模型预测值的 SAS DATA 步代码写入文件或目录条目。该代码即可包含在 DATA 步中为新数据评分。
|