“排名数据”任务
示例:按年龄和身高对学生进行排名
设置选项
您必须至少选择一个输出选项。
|
选项名称
|
说明
|
|---|---|
|
选项
|
|
|
排名方法
|
指定进行数据排名时使用的方法。下面是有效值:
无
不使用方法来排名数据。
百分位数排名
将原始值分入 100 组,其中最小值接收的是值为 0 的百分位数,最大值接收的是值为 99 的百分位数。
十分位数
将原始值分入 10 组,其中最小值接收的是值为 0 的十分位数,最大值接收的是值为 9 的十分位数。
|
|
排名方法(续)
|
四分位数
将原始值分入四组,其中最小值接收的是值为 0 的四分位数,最大值接收的是值为 3 的四分位数。
组 = n (NTILES)
将原始值分入 n 组,其中最小值接收的值为 0,最大值接收的值为 n–1。在组数框中,指定 n 值。
分数排名,其中分母 = n
计算分数排名,用每个排名除以包含排名变量的非缺失值的观测数。
分数排名,其中分母 = n+1
计算分数排名,用每个排名除以分母 n+1,其中 n 是指包含排名变量的非缺失值的观测数。
百分比
用每个排名除以包含变量的非缺失值的观测数,再用结果乘以 100 得出百分比。
|
|
排名方法(续)
|
正态评分(Blom 公式)、正态评分(Tukey 公式)、正态评分(van der Waerden 公式)
计算排名的正态评分。作为结果的变量将正态分布。公式如下:
Blom 公式
Tukey 公式
van der Waerden 公式
在这些公式中,
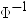 是逆累积正态 (PROBIT) 函数,ri 是第 i 个观测的排名,n 是排名变量的非缺失观测数。 是逆累积正态 (PROBIT) 函数,ri 是第 i 个观测的排名,n 是排名变量的非缺失观测数。
注: 如果您设置若值绑定,使用选项,则“排名数据”任务会根据非绑定值计算排名的正态评分,并将绑定规范应用于计算出的评分。
Savage 评分(指数)
计算排名的 Savage(或指数)评分。
注: 如果您设置了若值绑定,使用选项,那么数据排名任务将基于非绑定值计算排名的 Savage 评分,并将绑定规范应用到作为结果的评分中。
|
|
若值绑定,使用:
|
指定如何计算绑定数据值的正态评分或排名。
均值(中排名)
分配相应排名或正态评分的均值
高排名
分配相应排名或正态评分的最大值
低排名
分配相应排名或正态评分的最小值
密集排名
将绑定值视为单一次序统计量,以计算评分和排名。对于默认方法,排名是连续整数,最小值是 1,最大值是进行排名的变量的唯一非缺失值数量。系统将为绑定值分配相同排名。
|
|
秩序
|
指定是按照从小到大还是从大到小列出值。
|
|
结果
|
|
|
保存输出数据的位置
|
指定输出表的位置。默认情况下,表将保存在临时 Work 逻辑库中。
|
|
包括排名列
|
指定包含原始列和排名列的输出表。如果您希望将原始列替换为排名列,请取消选定包括排名列复选框。
默认情况下,排名列命名为 rank_列名,其中列名是原始列的名称。
|