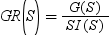信息增益和增益比计算
启用了快速生长属性后,会根据信息增益比而不是信息增益来部分确定节点拆分。本部分介绍信息增益和信息增益比的计算及其优缺点。在这些说明中,将属性视为分类变量的任何特定测度水平或测度变量的箱。
信息增益方法根据提供最大信息增益的属性来选择拆分。增益的度量单位是位。尽管该方法可提供很好的结果,但它倾向于基于具有大量属性的变量进行拆分。信息增益比方法纳入了拆分的值,以确定信息增益的哪个部分对于该拆分具有真正的价值。系统将选择具有最大信息增益比的拆分。
信息增益计算首先要确定训练数据的信息。响应值 r 中的信息通过以下表达式进行计算:
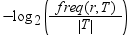
T 表示训练数据,|T| 是观测数。要确定训练数据的期望信息,可针对每个可能的响应值对此表达式求和:
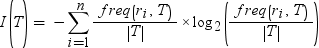
这里,n 是响应值总数。该值也称为训练数据的熵。
接下来,考虑基于有 m 个可能属性的变量 X 的拆分 S。该拆分提供的期望信息通过以下等式计算:
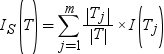
在此等式中,Tj 表示包含第 j 个属性的观测。
拆分 S 的信息增益通过以下等式计算:
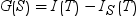
信息增益比会尝试通过引入拆分信息值来修正信息增益计算。拆分信息通过以下等式计算:
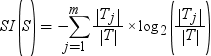
顾名思义,信息增益比是信息增益与拆分信息之间的比率: