데이터베이스 연결 팁
Hadoop 테이블을 가져올 때의 추가 옵션
SAS Visual Analytics에서는 BigInsights, Cloudera, Cloudera Impala, Pivotal HAWQ, Hortonworks,
MapR 및 Pivotal HD에서 데이터를 가져올 때 사용할 수 있는 셀프 서비스 옵션을 제공합니다. 이러한 각 데이터베이스는 관리자가 별도로 설정해야
합니다.
이러한 데이터베이스 모두의 연결 유형에서는 공통적으로 Hive 또는 HiveServer2에 연결한 다음, 테이블을 가져옵니다.
Hadoop 클러스터가 SAS Embedded Process와 함께 구성되면 SAS LASR Analytic Server로의 병렬 로드를 수행할 수
있습니다. 여기서는 데이터 가져오기 창에 있는 다음 중 하나를 나타냅니다.
-
SAS 시스템 옵션 필드에서 SAS_HADOOP_CONFIG_PATH 환경 변수를 지정합니다. 관리자가 값을 이미 지정했으면 필요하지 않습니다.
-
구성 필드에서 Hadoop 구성 파일의 경로를 지정합니다.
사이트에 따라서는 추가 옵션 지정이 필요할 수도 있습니다. Hadoop에서의 병렬 로드 설정에 대한 자세한 내용은 SAS Visual Analytics: Installation and Configuration Guide (Distributed SAS LASR)의 “Where Do I Locate My Analytics Cluster”를 참조하십시오.
ODBC 테이블을 가져올 때의 추가 옵션
연결 옵션 지정 필드를 사용하면 데이터 소스 이름을 사용하지 않고 다른 방법으로 ODBC 데이터베이스에 연결할 수 있습니다. 사용할 수 있는 옵션에 대한 자세한
내용은 SAS/ACCESS for Relational Databases: Reference의 LIBNAME Statement Specifics for ODBC 항목을 참조하십시오.
Oracle 테이블을 가져올 때의 추가 옵션
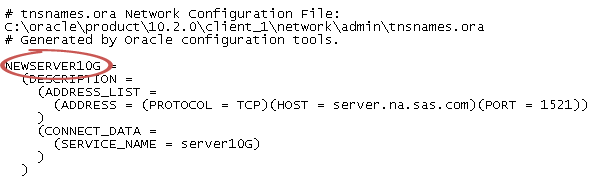
경로 필드의 값은 tnsnames.ora 파일의 넷 서비스 이름과 관련됩니다. tnsnames.ora 파일은 SAS Web Application Server용
컴퓨터에 Oracle 클라이언트를 설치하는 동안 생성됩니다. 이 파일은 대개
/opt/oracle/app/oracle/product/10.2.0/db_1/network/admin/tnsnames.ora 같은 Oracle 설치 디렉터리에 저장됩니다. 연결 정보를 위한 넷 서비스 이름이 이 파일에 포함됩니다. 다음 그림을 참조하십시오.
PostgreSQL 테이블을 가져올 때의 추가 옵션
스키마 필드는 테이블을 찾아볼 때는 대소문자를 구분하지 않지만 가져오기를 수행할 때는 대소문자를 구분합니다. 따라서 잘못된 대소문자로 스키마를 지정했을
때도 테이블을 찾아 테이블 선택 창에서 선택할 수 있습니다. 하지만 가져오기는 실패합니다. 이때, 데이터베이스 관리자에게 문의하여 스키마 이름을 확인하십시오.
Teradata 테이블을 가져올 때의 추가 옵션
Teradata Management Server 필드를 사용하여 SAS LASR Analytic Server가 동일한 데이터 어플라이언스에 배치되어 있는지 확인할 수 있습니다. SAS LASR
Analytic Server와 Teradata 데이터베이스가
동일한 데이터 어플라이언스에 있을 때는 SAS LASR Analytic Server에서 사용하는 호스트 이름이 Teradata Management 서버 필드에 포함되어 있어야 합니다.
SAS Visual Analytics 서버와 Teradata 데이터베이스가 동일한 데이터 어플라이언스에 배치되어 있지 않은 경우 병렬로 데이터를 전송하도록
구성할 수 있습니다. 병렬 로드 설정에 대한 자세한 내용은 SAS Visual Analytics: Installation and Configuration Guide (Distributed SAS LASR)의 Where Do I Locate My Analytics Cluster 항목을 참조하십시오.